
影响鉴别AI和人类的两个因素 (小组作业)
封面作者:NOEYEBROW
先验概率和材料性质对人类识别AI生成文本的交互影响
叶一杉, 李奕璇, 罗晏琦, 高畅. (2025). 先验概率和材料性质对人类识别AI生成文本的交互影响. https://blog.leafyee.xyz/2025/01/30/TextIdentify/
作者
叶一杉, 李奕璇, 罗晏琦, 高畅
单位
北京师范大学心理学部, 北京 100875
摘要
随着人工智能技术的发展,AI生成文本在多个领域中与人类创作的文本日趋相似,给人类判断文本来源带来了挑战。本研究探讨先验概率(被试预期的AI生成比例)和材料性质(AI或人类生成)对文本来源识别的交互影响。实验发现,材料性质显著影响判断,AI生成材料更易被识别为AI创作;先验概率显著影响识别倾向,AI比例越低,被试越倾向判断为人类创作;两者交互效应不显著,表明先验信息的认知偏向稳定存在。材料分析显示,AI生成文本在内容相关性、逻辑性和语言表达上优于人类,但在人类文本的个性化和情感自然性上仍有差距。本研究为理解人类决策偏向和AI文本优化提供了重要理论和实践启示。
关键词
先验概率, AI, 大语言模型, 识别
1 引言
在数字化浪潮汹涌澎湃的当下,人工智能(AI)已深度融入人们的生活,其生成的文本广泛应用于信息传播、教育、娱乐等诸多领域。从答疑解惑的智能助手,到辅助创作的智能写作工具,AI生成的文本无处不在,这使得人们频繁面临判断文本是由人类还是AI创作的情境。在今天,能否正确识别文本的来源已成为一个至关重要的问题。随着人工智能技术的飞速发展,AI 生成的文本在流畅度、逻辑性以及情感表达等方面日益逼近人类水准,这使得单纯凭借文本的表面特征来区分 AI 生成文本和人类创作的文本变得极为困难。在信息传播领域中,虚假信息可能会借助 AI 生成的文本大肆扩散,公众在面对这些信息时,很难仅凭直观感受判断其真实性。这不仅干扰了公众对信息真实性的准确判断,还可能对社会舆论的走向产生深远影响,误导公众舆论,引发不必要的社会波动。因此,探究人类识别AI生成文本的能力及影响因素具有重要意义。
1.1 识别AI生成的文本
Stadler et al. (2024) 的研究显示,经验丰富的审稿人在区分AI生成和人类原创的研究摘要时困难重重,正确识别AI生成摘要的比例仅62%,还将38%的原创摘要误判为AI生成。Porter & Machery (2024) 的研究也发现, 人们在区分AI生成的诗歌和著名诗人创作的诗歌时,识别AI生成诗歌的准确率仅46.6%,还更倾向于将AI生成诗歌判断为人类创作。Kovács (2024) 通过实验发现,人们在区分人类撰写和GPT-4生成的餐厅评论时判断结果与随机猜测无异,且GPT-4和Copyleaks等AI检测工具也无法准确区分。在文本检测工具方面,Ayub et al. (2024) 也指出,HIX.AI等工具会干扰检测结果,经其处理后几乎所有AI生成的文章都会被现有AI文本检测器判定为人类撰写。同时,不同的检测工具也存在各自的问题,Hashemi et al. (2024) 发现GPT-Zero在识别AI润色的文本时倾向于将其误分类为AI原创;Haowei Hua & Co-Jiayu Yao (2024) 研究表明,GPT - Zero在检测经改写工具处理的内容时,因复杂词汇替换和句子结构变化,基准分类准确率下降,难以准确判断文本是否为AI生成。这些都充分说明,无论是在专业领域的学术研究,还是在日常生活中的文本判断,准确区分AI生成文本和人类撰写的文本都存在较大困难。
1.2 先验概率对决策的影响
先验概率(prior probability)是指根据以往经验和分析得到的概率,如全概率公式,它往往作为”由因求果”问题中的”因”出现的概率 (林崇德, 2003)。作为贝叶斯理论中的核心概念,先验概率在人类的认知决策过程中起重要作用。 Dunovan & Wheeler (2014) 研究发现先验概率会导致被试在决策时产生偏向,且先验概率的不确定性对决策有影响,Romanus & Gärling (1999) 表明先验概率在不确定情况下对决策的作用更为显著,而 Seer et al. (2016) 则认为当先验概率可计算时,部分被试在决策时会更倾向于考虑先验概率,不过个体之间对先验概率的依赖程度存在较大差异。王长生 (2010) 研究发现不同的先验概率任务条件(20%、50%、80% 三种先验概率)下,运动员的决策正确率和反应时都有所不同。因此,先验概率作为人们在判断前已有的认知信息,极有可能显著影响文本来源识别结果。
1.3 本研究概述及假设
基于以往研究内容,本研究探究先验概率(被告知的AI生成文本与人类生成文本的比例信息)对识别文本生成来源的影响,试图补充先验概率对人类识别文本生成来源的影响,从而丰富人类识别AI生成文本的理论与研究,也有助于我们更好地应对 AI 技术带来的信息传播变革,提高公众对信息真伪的辨别能力,维护健康有序的信息传播环境和社会舆论生态。
具体提出研究假设如下:H1:材料性质对被试识别结果具有显著影响,与全部为人类回答的材料相比,全部为ai生成材料的条件下被试倾向于认为回答由ai生成;H2:先验概率对被试识别结果具有显著影响,随着ai回答先验概率降低,被试倾向于认为材料为人类生成。
2 实验设计
本实验为两因素 (实验材料性质: AI生成或人类生成, 被试间变量; 给定先验概率: 更多人类、平均、更多AI、随机, 被试内变量) 混合设计, 因变量为被试对给定文本的更像人类生成还是AI生成的评价 (四点量表). 需要指出的是, 被试看到的材料实际上全为AI生成或全为人类生成, 但被试被告知是两种材料混合的, 且在不同的部分会告诉被试不同的两种材料比例.
2.1 实验材料
本研究所用数据集来自AI开源社区 Hugging Face, 该社区提供了大量的开源模型和数据集. 本实验使用了其中由用户 Rui Wang 发布的一个知乎问答数据集 ZhihuKOL 的前五分之一数据 (共 201244 条问答对, 大小约 300 MB).
我们首先对数据进行了清洗过滤. 筛选出问题长度在 25(含) ~ 35(含) 字符数, 答案长度在 95(含) ~ 105(含) 字符数的问答对, 共 888 条.
随后我们使用阿里巴巴”百炼”大模型平台提供的 qwen-max 模型 API, 让该模型逐一生成对 888 条问题的答案. 所用的系统提示词为: “你是一个普通的知乎用户. 你需要尽可能像人类一样回答问题, 包括字数基本相同、可以像人类一样没有逻辑或情绪化地回答问题、回答中可以有搞怪或玩梗的内容、回答可以是片面或错误的. 你的回答应该是一个句子,字数应为 xxx 字左右.” 其中 xxx 设为人类回答的字符数的 1.4 倍 (四舍五入为整数).
生成结束后, 我们再次筛选出人类回答与AI回答字符数差异在 10 以内(含)的问答对, 共 342 条.
之后, 我们再次使用阿里巴巴”百炼”大模型平台提供的 qwen-max 模型 API, 让该模型评价这 342 条问答对的AI回答和人类回答相似度 (1-10 之间的整数). 所用的系统提示词为: “下面是针对同一个问题的两个回答,其中一个回答是由人类知乎用户提供的,另一个回答是由AI生成的。请你用 1-10 之间的一个整数来评价: 如果一个人类来阅读这两个回答,他们分辨出哪个是AI生成难度. 1 表示非常容易,即被试很容易发现哪条回答是AI生成的;10 表示非常困难,即被试很难发现哪条回答是AI生成的。你的回答应该是一个 1-10 之间的整数, 并不要再回答其他任何内容. 问题: xxx, 人类回答: xxx, AI回答: xxx.”
生成结束后, 一条问答对因为被模型内容屏蔽机制拒绝回答, 我们将其剔除, 最终得到 341 条问答对.
最后, 我们只选取得分大于等于 8 的问答对, 共 78 条. 并为了避免人类和AI对符号的偏好, 将所有人类和AI回答中的感叹号替换为句号、为了避免人类明显的答非所问和答案编辑记录影响实验结果, 将相关问答对剔除、把人类回答中带有外部链接和提到了图片的问答对删除, 最终得到 69 条问答对.
2.2 取样和被试
本实验采用方便取样: 在微信朋友圈和校园论坛发布实验招募信息, 有意愿参与的直接扫描二维码进入在线实验页面. 实验参与者需满足: 非心理学专业学生 (大一除外)、具备中文阅读能力. 实验结束后, 参与者将获得主试的学习笔记作为报酬.
实验末尾会询问被试是否认真回答、是否首次参与实验、是否愿意上传数据, 仅上传三个问题都选择肯定答案的被试数据, 最终得到 60 份数据.
之后进行数据清洗. 首先剔除在被试内变量 (给定先验概率) 的四个水平的任意一个中, 10 次选择的答案相同的被试, 得到 55 份数据. 其次, 根据最近的研究, 中国大学生的最快阅读速度约为 507±73 字 / 分 (张慢慢, et al., 2024), 结合考虑本研究的阅读量, 剔除平均反应时小于 6 秒的被试, 得到 42 份数据. 最后, 为避免被试没有一次性完成实验, 剔除平均反应时大于均值加 2.58 倍标准差 (用前两步剔除后的数据计算) 的被试, 得到 41 份数据.
2.3 实验流程
实验流程如图 1 所示.
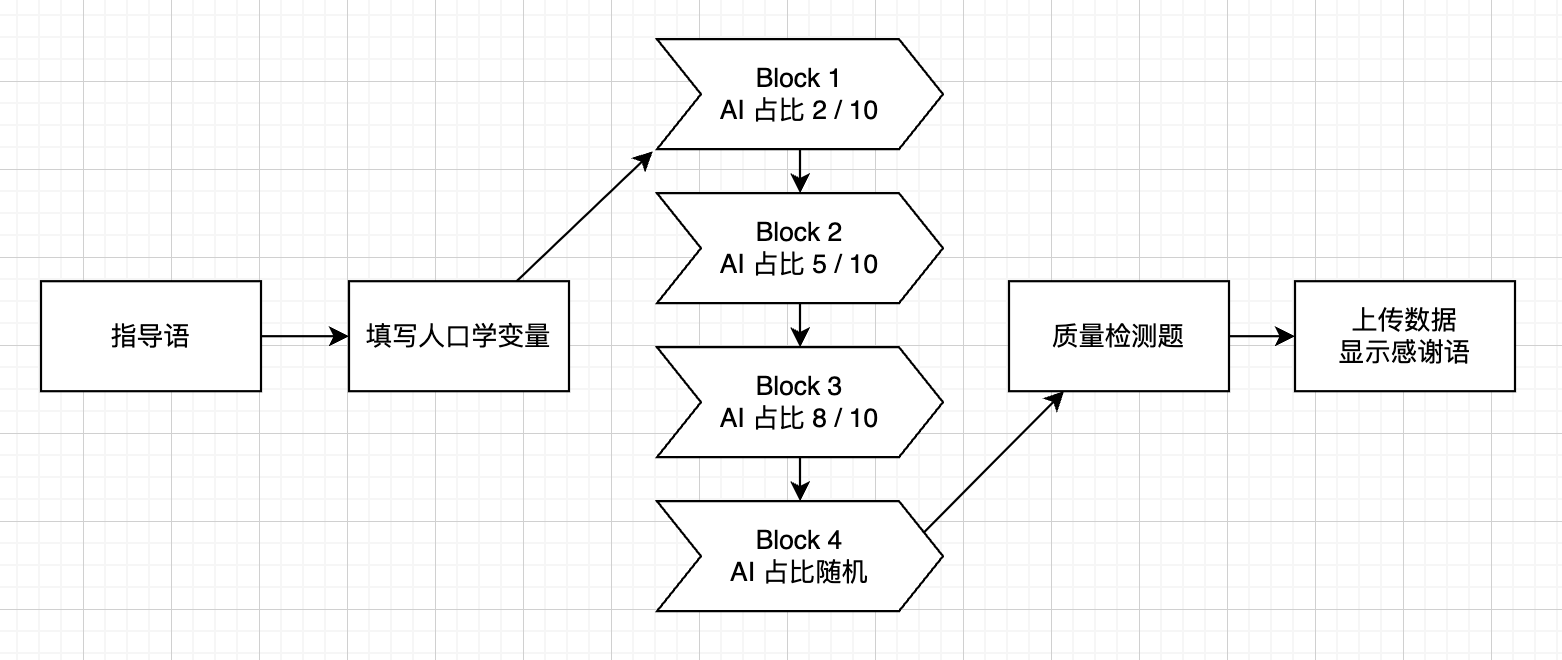
图 1 - 实验流程图
被试通过扫码打开网页进入实验程序, 填写基本人口学信息、阅读指导语后, 进入正式实验. 正式实验共分为四个部分, 每个部分包含 10 个问答对. 对于每个问答对, 被试需要在 “很可能是AI写的”、”有点像AI写的”、”有点像人类写的”、”很可能是人类写的” 四个选项中选择一个. 被试实际上看到的问答对全为AI生成或全为人类生成 (被试间随机), 四个部分依次在开始时告诉被试 10 段问答对中有 2、5、8、随机个是AI生成的.
每个试次呈现效果如图 2 所示.

图 2 - 试次呈现效果图
实验结束后, 被试需要回答是否认真回答、是否首次参与实验、是否愿意上传数据. 实验程序只会上传三个问题都选择肯定答案的被试数据至主试数据库.
2.4 材料分析
为了分析对同一个问题的两个回答的差异, 向 gpt-4o 模型提问: “我想为一段文本回答的某些属性进行评分,从而对比同一问题的AI和人类回答的差异性。我可以从哪些属性打分?”, 结合模型回答决定从以下几个方面进行分析:
表 1 - 材料分析维度
| 评分维度 | 评分标准 |
|---|---|
| 1. 内容相关性 | 回答准确地回答了问题,且内容与问题相关。 |
| 2. 逻辑性 | 回答的结构清晰,论点和论据之间的关系合理。 |
| 3. 语言表达 | 用词准确,句式流畅,容易理解, 语法正确 |
| 4. 创造力 | 表现出原创性或独特性 |
| 5. 情感或态度 | 展现了适当的情感或语气 |
| 6. 专业性 | 体现了对主题的深度理解和专业知识 |
| 7. 实用性 | 能为提问者提供明确、有价值的帮助 |
| 8. 伦理性 | 符合伦理和社会规范, 避免偏见或歧视 |
| 9. 知识覆盖面 | 表现出对多方面的知识理解 |
| 10. 时间效率 | 能够快速传达关键信息, 避免赘述 |
使用 qwen-max 模型 API, 让该模型逐一对 69 条问答对进行 0-10 评分, 提示词为: “请针对给定的问题, 从以下维度评价给定的回答的质量, 为每个维度给出 0 (最低) 到 10 (最高) 的评分: xxx. 问题: xxx, 回答: xxx.”. 结果如图 3 所示.
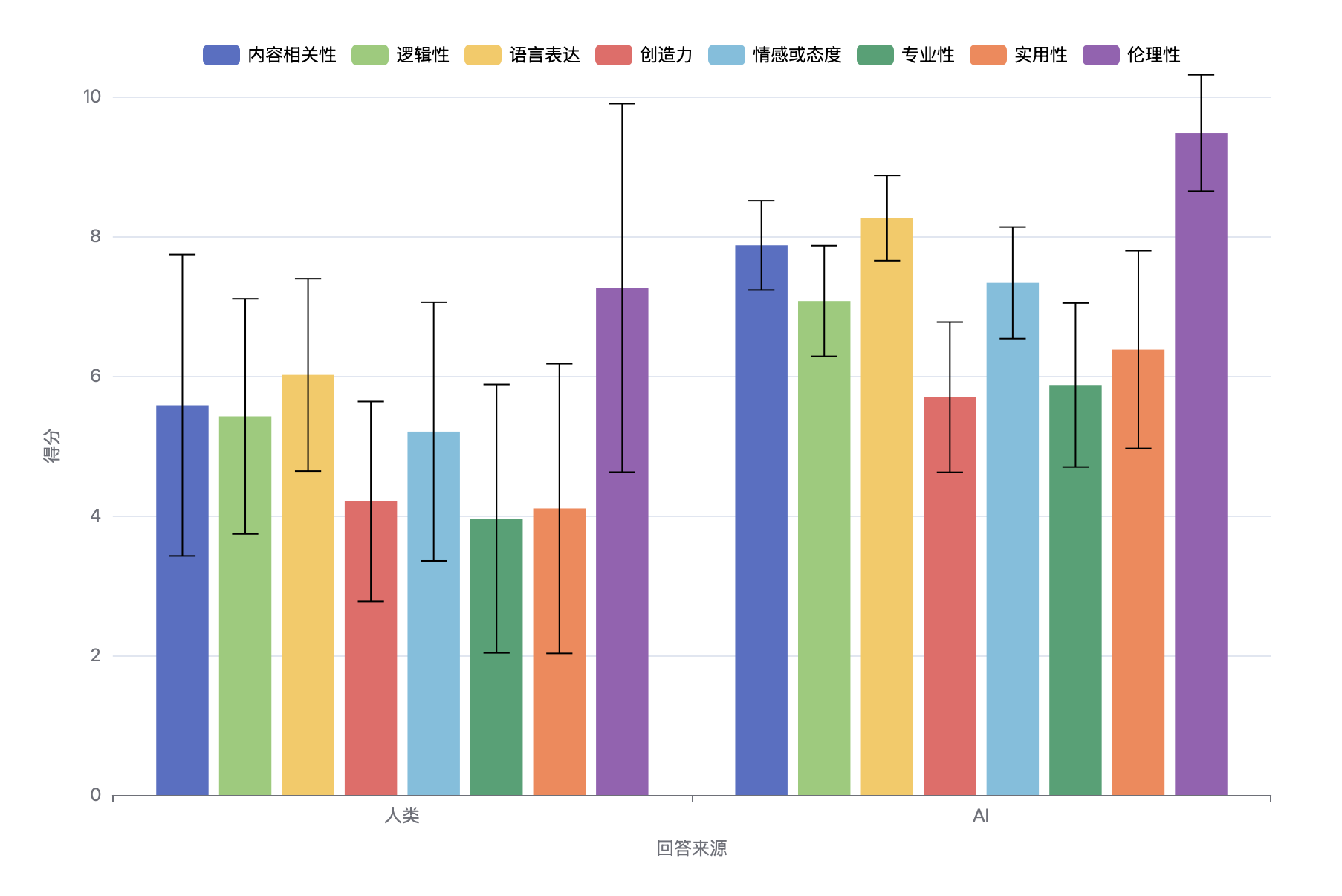
图 3 - 材料分析结果图
对结果进行 Welch’s t 检验, 在所有维度上, AI 的得分均值均显著高于人类的得分均值 (p < .001), 且效应量均在中等到大的范围内. 结果如表 2 所示.
表 2 - 材料分析结果表
| 评分维度 | 人类均值 (人类标准差) |
AI均值 (AI标准差) |
均值差 | t | p | df | Cohen’s d | 95% CI |
|---|---|---|---|---|---|---|---|---|
| 内容相关性 | 5.58 (2.158) |
7.87 (0.64) |
-2.29 | -8.449 | <.001 | 79.854 | -1.438 | [-2.829, -1.75) |
| 逻辑性 | 5.42 (1.684) |
7.072 (0.792) |
-1.652 | -7.375 | <.001 | 96.672 | -1.256 | [-2.097, -1.208) |
| 语言表达 | 6.014 (1.377) |
8.261 (0.61) |
-2.246 | -12.388 | <.001 | 93.692 | -2.109 | [-2.606, -1.886) |
| 创造力 | 4.203 (1.431) |
5.696 (1.075) |
-1.493 | -6.929 | <.001 | 126.24 | -1.18 | [-1.919, -1.066) |
| 情感或态度 | 5.203 (1.852) |
7.333 (0.798) |
-2.13 | -8.776 | <.001 | 92.432 | -1.494 | [-2.613, -1.648) |
| 专业性 | 3.957 (1.921) |
5.87 (1.175) |
-1.913 | -7.058 | <.001 | 112.623 | -1.202 | [-2.45, -1.376) |
| 实用性 | 4.101 (2.073) |
6.377 (1.415) |
-2.275 | -7.529 | <.001 | 120.068 | -1.282 | [-2.874, -1.677) |
| 伦理性 | 7.261 (2.638) |
9.478 (0.833) |
-2.217 | -6.657 | <.001 | 81.434 | -1.133 | [-2.88, -1.555) |
| 知识覆盖面 | 3.493 (1.431) |
5.261 (1.184) |
-1.768 | -7.908 | <.001 | 131.388 | -1.346 | [-2.21, -1.326) |
| 时间效率 | 6.42 (1.242) |
7.797 (0.719) |
-1.377 | -7.971 | <.001 | 109.007 | -1.357 | [-1.719, -1.034) |
3 结果
3.1 描述统计
根据反应时与作答方差为0(所有选项均相同)进行筛选,数据清洗后被试共41名,年龄在17到50之间(Mean = 19.90, Std = 4.974),其中女性占比70.73%(女 = 29, 男 = 12)。描述统计结果显示,被试选择随人类回答先验概率的降低呈现下降趋势,同时人类回答材料组被试选择整体高于ai组,即被试倾向于认为材料由人类生成。
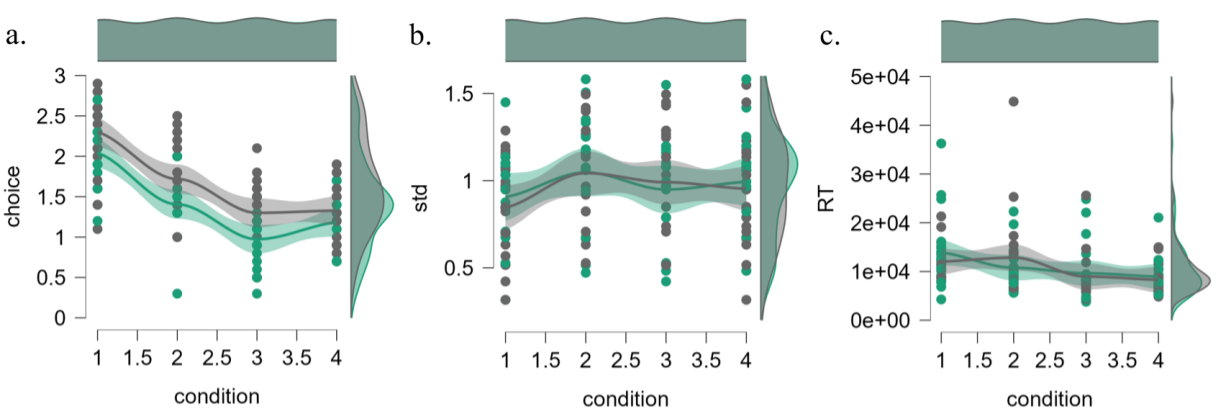
图 1 - 描述统计(a:被试选择,b:作答标准差,c:反应时;材料:灰色-人类回答,绿色-AI回答)
3.2 初步统计分析
为检验连续的无返回试次呈现对被试的判断是否存在顺序效应,首先对不同先验概率与试次顺序进行重复测量两因素方差分析(condition = 4; trial = 10),将材料性质(material_true)作为被试间变量。结果显示,被试选择的先验概率主效应显著,F(3,117) = 77.810,p < .001,ηp2 = 0.666,事后检验结果显示,各组间被试选择差异均显著;材料性质主效应显著,F(1,39) = 6.623,p = .014,ηp2 = 0.145,但试次顺序主效应不显著。此外,先验概率与实验顺序的交互作用边际显著,F(27,1053) = 1.404,p = .083,ηp2 = 0.035,即实验材料全部为ai生成(图2a)与全部为人类生成(图2b)时,不同先验概率条件下被试选择随试次变异存在一定差异但不显著。
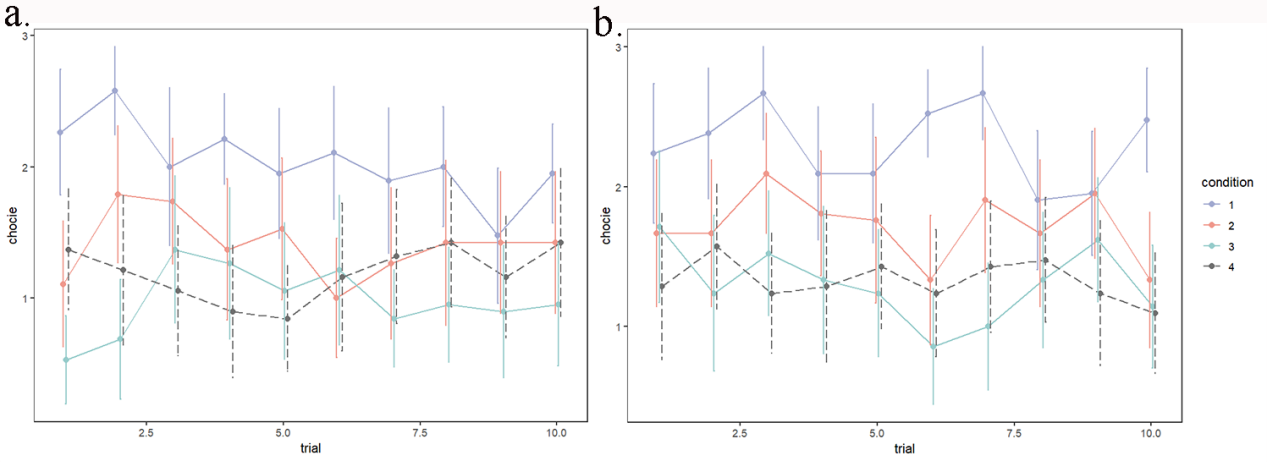
图 2 - 不同条件下随试次进行的被试选择(a:“ai”; b:“human”)
3.3 方差分析
在排除试次顺序影响后,分别针对被试选择、被试选择时长与不同先验概率下的选择标准差进行混合两因素方差分析,将材料性质(material_true)作为被试间变量。结果显示,首先针对被试选择结果与上述一致(图3a);针对作答标准差,仅先验概率主效应显著,F(3,117) = 6.831,p = .001,ηp2 = 0.163(图3b),事后检验结果显示,仅ai先验概率20%与50%组差异显著,MD = -0.186, t = -3.378, Conhen’s d = -0.629;针对反应时,仅先验概率主效应显著,F(3,117) = 7.045,p < .001,ηp2 = 0.164(图3c),事后检验结果显示,ai先验概率20%与80%组差异显著,MD = 3.592, t = 2.904, Conhen’s d = 0.632,ai先验概率20%与无先验概率组差异显著,MD = 4.244, t = 4.563, Conhen’s d = 0.747,ai先验概率50%与无80%组差异显著,MD = 2.639, t = 2.643, Conhen’s d = 0.464, ai先验概率50%与无先验概率组差异显著,MD = 3.291, t = 3.068, Conhen’s d = 0.579。
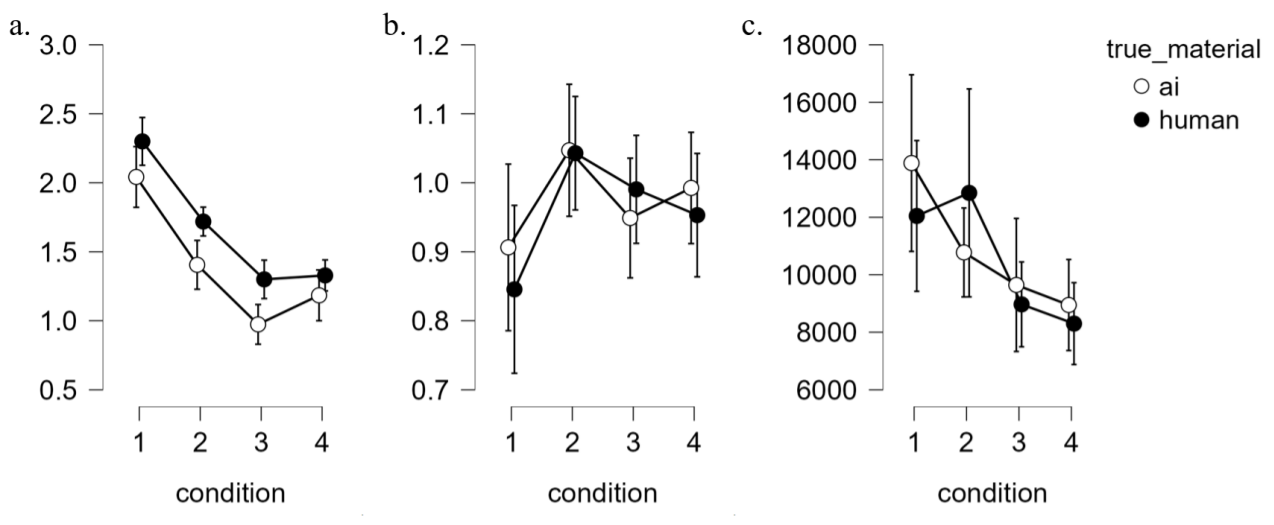
图 3 - 方差分析结果(a: 被试选择;b:作答标准差;c:反应时)
3.4 调节效应检验
使用线性混合模型(linear mixed model, LMM)进行调节效应检验,其中材料性质(1:“全部为ai”;2:“全部为人类”)为调节变量,被试选择作为响应变量。将先验概率、材料性质、先验概率与材料性质交互项加入到固定效应与随机效应,并在随机效应中将被试ID作为主体,其中材料性质以人类生成材料为对照。
结果显示,先验概率主效应显著,β = -3.333, t = -8.528, p < 0.001,表明先验概率显著负向预测被试选择,即随着人类回答占比的先验概率降低,在所有材料性质条件下,被试选择均趋向于认为回答更多由ai生成;材料性质主效应边际显著,β = -.315, t = -1.908, p = 0.058,表明不同材料性质下被试选择差异边际显著,与全部为人类生成的材料相比,全部为ai生成条件下被试更倾向于认为回答为ai生成;先验概率与材料性质交互项不显著,即调节效应不显著:不同材料性质下,先验概率对被试选择的影响方向与大小无显著差异。
表 1 - 线性混合模型检验结果 (因变量:choice)
| 参数 | β | SE | df | t | p | 95% CI |
|---|---|---|---|---|---|---|
| 截距 | 2.495 | .115 | 164.917 | 21.622 | <.001 | [2.267, 2.723) |
| 材料性质 | -.315 | .165 | 164.917 | -1.908 | .058 | [-.641, -.011) |
| 先验概率 | -.333 | .039 | 123.577 | -8.528 | <.001 | [-.410, -.256) |
| 材料性质 * 先验概率 | .034 | .056 | 123.577 | .605 | .547 | [-.077, .145) |
4 讨论
4.1 先验概率的作用机制与影响
本研究发现先验概率对被试识别文本材料的来源具有显著影响,随着人类回答占比的先验概率降低,被试更倾向于认为材料由 AI 生成。这与认知心理学中的贝叶斯推理理论相契合,即人们在面对不确定信息时,会结合先验知识和当前证据进行判断(Kahneman & Tversky, 1984)。在本实验中,被试被告知不同比例的人类和 AI 生成材料的先验信息,这一信息成为他们后续判断的重要依据。当先验概率倾向于人类生成时,被试在面对文本时会不自觉地偏向于认为其是人类所写,反之亦然。这表明在信息处理过程中,人们并非完全依赖文本本身的特征,而是会受到先验信念的引导。这一发现对于理解人类在复杂信息环境下的决策过程具有重要意义,也提示我们在设计信息呈现方式时,需要考虑到先验信息对受众判断的潜在影响。
4.2 材料性质的影响与人类与 AI 文本特征的差异
研究结果表明,材料性质对被试的识别结果也有显著影响,与全部为人类回答的材料相比,全部为 AI 生成的条件下被试更倾向于认为回答为 AI 生成。这说明在没有先验信息的干扰下,被试能够感知到人类和 AI 文本之间存在的差异。通过材料分析维度的评分对比,我们发现 AI 在多个维度上的得分均值显著高于人类,如内容相关性、逻辑性、语言表达等。这可能是因为 AI 模型在训练过程中,通过对大量文本数据的学习,能够较好地掌握语言的规则和结构,从而生成在这些方面表现较为出色的内容。然而,尽管 AI 在这些客观维度上表现优异,但人类回答可能在一些难以量化的方面更具优势,例如情感的自然流露、独特的个人风格等,这些可能是被试在判断时所依据的潜在线索。这一结果也反映了当前 AI 技术的发展现状,即虽然在某些方面已经能够达到甚至超过人类水平,但在完全模拟人类的复杂思维和表达上仍存在一定差距。
4.3 先验概率与材料性质的交互作用
本研究还探讨了先验概率与材料性质之间的交互作用,结果表明这种交互作用并不显著。这意味着无论材料是全部由人类生成还是全部由 AI 生成,先验概率对被试选择的影响方向和大小都无显著差异。这可能是因为先验概率作为一种较强的认知偏差,其影响力在不同材料性质条件下都较为稳定。即使在面对与先验信息不完全一致的材料时,被试的判断仍会受到先验信念的较大牵制。这一结果提示我们在考虑信息处理和决策过程时,不能简单地假设不同情境下各种因素的交互作用会改变其基本的影响模式,一些根深蒂固的认知倾向可能会在多种情况下持续发挥作用。
4.4 局限性及未来研究方向
尽管本研究在实验设计和结果分析方面取得了一定成果,但也存在一些局限性。首先,在实验材料的选择上,虽然经过了严格的筛选和处理,但研究所使用的数据集和AI模型依旧存在一定的局限性,无法完全代表所有类型的人类和AI文本。在本研究中,实验者使用了国产的通义千问模型来生成文本。与其他AI模型相比,通义千问模型在中文文本生成方面表现出色。然而,不同模型在生成文本的质量和人类可识别性方面可能存在差异。例如,一些基于Transformer架构的模型,如GPT系列,在生成连贯、自然的文本方面表现出色,但在某些情况下可能会生成一些逻辑上不够严谨或与人类表达习惯不符的内容。而通义千问模型在中文语境下,能够更好地理解和生成符合中文表达习惯的文本,这可能与其在中文数据上的训练和优化有关。未来的研究可以进一步比较不同模型在同一语言下的表现,以及同一模型在不同语言下的效果,以更全面地了解不同模型的特点和优势,通过使用更多元化的数据源和不同的AI模型,以增强研究结果的普遍性。
其次,实验中的先验概率设置是基于被试被告知的比例,而非被试自身的真实经验或长期形成的信念,这种人为设置的先验概率可能与实际情况存在偏差。未来研究可以探索如何更自然地引入先验概率,例如通过长期的文本接触和学习过程,让被试形成更为稳定和真实的先验信念,再考察其对判断的影响。
此外,本研究主要关注了被试对文本生成来源的识别结果,但未来的研究可以进一步探讨被试的确信程度是否会对其喜爱程度、信任感等变量产生影响。例如,如果被试对AI生成文本的识别确信程度较高,他们可能会对AI生成的内容产生更高的信任感,从而更愿意接受AI提供的信息和建议。相反,如果被试对AI生成文本的识别确信程度较低,他们可能会对AI生成的内容持怀疑态度,进而影响其对AI的喜爱程度和信任感。这种影响对于未来人工智能助手和AI心理咨询的设计具有重要意义。在设计人工智能助手时,需要考虑如何提高用户对其生成内容的信任感,以增强用户的使用体验和满意度。同样,在AI心理咨询领域,用户对AI生成的咨询建议的信任程度将直接影响其对咨询效果的评价和后续的使用意愿。因此,未来的研究可以进一步探索确信程度与喜爱程度、信任感等变量之间的关系,为人工智能助手和AI心理咨询的设计提供理论依据和实践指导。
最后,本研究主要关注了被试的识别结果,对于被试在判断过程中的认知加工机制和心理体验了解有限。未来研究可以引入眼动追踪、脑电图等技术手段,深入探究被试在面对不同先验概率和材料性质时的具体认知过程,以及情感、动机等其他心理因素在其中所起的作用。
4.5 实践意义与应用前景
本研究的成果对于多个领域具有实践意义。在教育领域,了解先验概率和材料性质对学习者判断的影响,可以帮助教师更有效地设计教学材料和活动,引导学生形成正确的认知和判断。例如,在教授文学作品鉴赏时,教师可以适当调整先验信息的呈现,让学生更加客观地评价不同作者的作品风格。在信息传播领域,媒体从业者可以依据本研究结果,优化信息的呈现方式和内容,提高信息的可信度和接受度。例如,在报道人工智能相关新闻时,合理设置先验信息,避免误导公众对AI技术的认知。
除此之外,本研究对于人工智能的开发和应用也具有启示作用。本研究可以被视为一种图灵测试的方式,通过让被试判断文本是由人类还是AI生成,来评估AI模型生成文本的自然度和人类可接受度。开发者可以根据人类对AI文本特征的感知和判断特点,进一步优化AI模型,使其生成的文本更加符合人类的期望和需求,提高AI在实际应用中的效果和用户体验。图灵测试最初是用于判断机器是否具有智能的一种方法,即如果机器能够与人类进行自然对话,而人类无法区分对话对象是人还是机器,那么就可以认为机器具有智能。在本研究中,被试对AI生成文本的识别难度可以作为一种衡量AI模型质量的指标。如果被试很难区分文本是由人类还是AI生成,那么说明AI模型在生成文本方面已经达到了较高的水平。未来,这种图灵测试的方法可以进一步应用于评价AI模型的质量,特别是在自然语言处理和生成领域。通过不断优化模型,提高其生成文本的人类可接受度,可以推动AI技术的发展和应用。
5 结论
材料性质对被试识别结果具有显著影响:与全部为人类回答的材料相比,全部为ai生成材料的条件下被试倾向于认为回答由ai生成.
先验概率对被试识别结果具有显著影响:随着ai回答先验概率降低,被试倾向于认为材料为人类生成;同时实验材料的调节效应不显著,即不同材料性质下先验概率对被试识别结果的影响无显著差异。
参考文献
- 林崇德.心理学大辞典(下卷).上海教育出版社.2003
- 王长生.(2010).不同逻辑背景下知识表征方式对跆拳道运动员直觉思维决策效果影响.(eds.)第九届全国运动心理学学术会议论文集(pp.1125-1127).华中师范大学体育学院;
- 张慢慢, 李鑫, 边菡, 汪强, 臧传丽, 闫国利, 白学军. (2024). 中文阅读中快速读者与慢速读者的知觉广度. 心理科学, 47(4), 788-794.
- Ayub, T., Ahmad Malla, R., Khan, M. Y., & Ganaie, S. A. (2024). The art of deception: humanizing AI to outsmart detection. Global Knowledge, Memory and Communication.
- Dunovan, K. E., Tremel, J. J., & Wheeler, M. E. (2014). Prior probability and feature predictability interactively bias perceptual decisions. Neuropsychologia, 61, 210-221.
- Hashemi, A., Shi, W., & Corriveau, J. P. (2024). AI-generated or AI touch-up? Identifying AI contribution in text data. International Journal of Data Science and Analytics, 1-12.
- Hua, H., & Yao, C. J. (2024). Investigating generative AI models and detection techniques: impacts of tokenization and dataset size on identification of AI-generated text. Frontiers in Artificial Intelligence, 7, 1469197.
- Kahneman, D., & Tversky, A. (1984). Choices, values, and frames. The American Psychologist, 39(4), 341–350. https://doi.org/10.1037/0003-066X.39.4.341
- Kovács, B. (2024). The Turing test of online reviews: Can we tell the difference between human-written and GPT-4-written online reviews?. Marketing Letters, 1-16.
- Porter, B., & Machery, E. (2024). AI-generated poetry is indistinguishable from human-written poetry and is rated more favorably. Scientific Reports, 14(1), 26133.
- Romanus, J., & Gärling, T. (1999). Do changes in decision weights account for effects of prior outcomes on risky decisions?. Acta Psychologica, 101(1), 69-78.
- Seer, C., Lange, F., Boos, M., Dengler, R., & Kopp, B. (2016). Prior probabilities modulate cortical surprise responses: a study of event-related potentials. Brain and cognition, 106, 78-89.
- Stadler, R. D., Sudah, S. Y., Moverman, M. A., Denard, P. J., Duralde, X. A., Garrigues, G. E., … & Menendez, M. E. (2024). Identification of ChatGPT-generated abstracts within shoulder and elbow surgery poses a challenge for reviewers. Arthroscopy: The Journal of Arthroscopic & Related Surgery.
- 标题: 影响鉴别AI和人类的两个因素 (小组作业)
- 作者: 小叶子
- 创建于 : 2025-01-30 18:45:16
- 更新于 : 2026-02-25 14:11:09
- 链接: https://blog.leafyee.xyz/2025/01/30/TextIdentify/
- 版权声明: 版权所有 © 小叶子,禁止转载。


