封面作者:NOEYEBROW
请先阅读JavaScript学习笔记 和TypeScript学习笔记
推荐阅读:Golang中文学习文档
简介 Go 是一种并发支持、垃圾回收的编译型系统编程语言,旨在创造一种具有静态编译语言的高性能和动态语言的高效开发之间的理想平衡
在官网 下载安装包,安装完成后,可以在终端输入 go version 查看版本号并确认安装成功
Go 的注释与 JavaScript 相同; 变量只能由字母、数字、下划线组成,且不能以数字开头; 变量和函数采用驼峰命名法Go 的运算符和 JavaScript 也类似, 但是 ++ 和 -- 必须后置; 数字也和 JavaScript 一样,可以有 _ 分隔符和不同进制Go 的字符字面量使用 '', 支持 Unicode; 字符串字面量使用 "" 或 ``你说得对, 但是 if err != nil
1 2 3 4 go run main.go go build main.go
go mod Go 1.11 版本之后引入了 go mod 包管理工具, 可以在项目中使用, 用于管理项目的依赖; 可以在https://pkg.go.dev/ 上查找依赖
go.mod 相当于 package.json; go.sum 相当于 package-lock.json
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 git clone xxx go mod init github.com/xxx/xxx go mod download go get github.com/xxx/xxx go get github.com/xxx/xxx@none go mod tidy go install github.com/xxx/xxx go run github.com/xxx/xxx
go mod 实际上是基于 git 等版本控制工具的
导入导出 Go 中的包可能包含多个文件,但是只能有一个 main 包,main 包是程序的入口
1 2 3 4 5 6 7 8 9 10 11 12 13 14 package main import "fmt" import o "os" import ( "fmt" _ "os" ) func main () fmt.Println("Hello, World!" ) }
1 2 3 4 5 6 7 8 9 10 11 12 13 package demoimport "fmt" func privateFunc () fmt.Println("privateFunc" ) } func PublicFunc () fmt.Println("PublicFunc" ) }
数据类型
类型
描述
示例
bool布尔型
true, false
uint8/16/32/64无符号整型
0, 255
int8/16/32/64有符号整型
-128, 127
uint/int相当于 Rust 中的 usize
0, 255
uintptr无符号整型,用于存放一个指针
0x123456
float32/64浮点型
3.14, 0.618
complex64/128复数
3.14+0i, 0.618+0i
byteuint8 的别名, 表示 ASCII 码byte('A')
runeint32 的别名, 表示 Unicode 码rune('中')
string字符串, 可以转为 []byte
"Hello, World!"
[]T切片, 动态数组
[]int{1, 2, 3}
[n]T数组, 固定长度数组
[3]int{1, 2, 3}, n 必须是常量
map[K]V映射, 键值对
map[string]int{"a": 1, "b": 2}
struct结构体, 自定义类型
type Person struct { Name string; Age int }
interface接口, 抽象类型
type Animal interface { Eat() }
func函数, 函数类型
func Add(a, b int) int { return a + b }
chan通道, 用于协程间通信 (后面细讲)
ch := make(chan int)
*T指针, 指向 T 类型的指针 (后面细讲)
var p *int = &a
类型转换 : int(3.14)、(func() int)(xxx) 等, 不存在隐式类型转换类型断言 : value.(int), 该语句返回 转换后的值, 转换是否成功 两个返回值; 常用于判断接口变量的实际类型类型判断 : value.(type), 该语句只能用于 switch 语句中, 用于判断接口变量的实际类型
1 2 3 4 5 6 7 8 var a float64 = 3.14 var b int = int (a)switch a.(type ) { case int : fmt.Println("int" ) case float64 : fmt.Println("float64" ) }
默认值 不同于 JavaScript, Go 变量即使没有赋值也会有默认值
类型
默认值 (零值)
boolfalse
数字
0
string""
数组
对应类型的零值, 如 [3]int 为 [0, 0, 0]
struct对应类型的零值, 如 Person 为 Person{}
其他
nil
nil 和 null 不同, 其本身不属于任何类型
自定义类型 1 2 type MyInt int var num MyInt = 123
通常用于类型别名 (有的库的类型名很长)、附加方法、声明结构体字段等
常量 常量的值不能在运行时修改 (即被写死在二进制文件中), 其值只能说基本数据类型, 可能来源于字面量、其他常量标识符、常量表达式等; 常量的类型可以省略
1 2 3 4 5 6 7 8 9 10 const constNum = 123 const constStr = "Hello, World!" const constExp = 1 + 2 + constNumconst ( constA = 1 constB = 2 constC = 3 )
iota iota 是 Go 语言的常量计数器, 只能在常量的表达式中使用, 且每次使用 iota 时都会自增 1
1 2 3 4 5 6 7 8 9 10 11 12 13 const ( Num = iota Num1 Num2 ) const ( Num = iota *2 Num1 Num2 Num3 = iota Num4 )
变量 变量的值可以在运行时修改, 其值可以是任意类型, 但是类型一旦确定就不能修改; Go 的类型推断必须通过 := 手动进行
1 2 3 4 5 6 7 8 9 10 11 12 13 var varNum int = 123 var varStr string = "Hello, World!" var ( varA int = 1 varB string = "Hello" ) var numA, numB, numC int = 1 , 2 , 3 varNum := 123 varStr := "Hello, World!"
Go 中的变量声明必须使用, 否则会报错; 如果确实不需要使用, 可以使用 _ 占位符
解构赋值 1 2 3 4 var a, b := 1 , 2 fmt.Println(a, b) a, b = b, a fmt.Println(a, b)
作用域 Go 中可以手动用 {} 创建作用域, 作用域内的变量只能在作用域内使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 package mainimport "fmt" var a = 1 func main () fmt.Println(a) { var a = 2 fmt.Println(a) } fmt.Println(a) }
输入输出
函数
描述
fmt.Print(xxx)打印, 不换行
fmt.Println(xxx)打印, 换行
fmt.Printf(xxx, var)打印, 格式化输出
fmt.Scan(&var)输入, 根据空格或换行符分割
fmt.Scanln(&var)输入, 根据换行符分割
fmt.Scanf(xxx, &var)输入, 根据格式化输入
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 package mainimport "fmt" func main () var ( num int str string ) fmt.Print("请输入一个整数: " ) fmt.Scan(&num) fmt.Print("请输入一个字符串: " ) fmt.Scanln(&str) fmt.Printf("num: %d, str: %s\n" , num, str) }
格式化
格式化
描述
接受类型
%%百分号
无
%s字符串
string / []byte
%d十进制整数
各种整数类型
%f浮点数
float32/64
%t布尔值
bool
%v值原本的形式,多用于数据结构的输出
任意类型
%#v值的 Go 语法表示
任意类型
%+v类似 %v, 但输出结构体时会添加字段名
任意类型
%T值的类型
任意类型
%p指针指向的地址
*T
条件语句 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 if num > 0 { fmt.Println("num > 0" ) } else if num < 0 { fmt.Println("num < 0" ) } else { fmt.Println("num = 0" ) } if msg := "Hello" ; num > 0 { fmt.Println(msg) } switch num { case 1 : fmt.Println("num = 1" ) case 2 : fmt.Println("num = 2" ) default : fmt.Println("num = 0" ) } str := "Hello" switch { case str == "Hello" : fmt.Println("str = Hello" ) case str == "World" : fmt.Println("str = World" ) default : fmt.Println("str = None" ) } for i := 0 ; i < 10 ; i++ { if i == 5 { goto end } fmt.Println(i) } end: fmt.Println("End" )
循环语句 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 for i := 0 ; i < 10 ; i++ { fmt.Println(i) } for i < 10 { fmt.Println(i) i++ } for { fmt.Println(i) i++ if i == 10 { break } } arr := []int {1 , 2 , 3 } for index, value := range arr { fmt.Printf("index: %d, value: %d\n" , index, value) } for i := 1 ; i != 0 ; i++ { if i <= 5 { continue } if i >= 10 { break } fmt.Println(i) } end: for i := 0 ; i < 10 ; i++ { for j := 0 ; j < 10 ; j++ { if i == 5 && j == 5 { break end } fmt.Println(i, j) } }
数组和切片 Go 中的数组是值类型, 作为参数传递时会拷贝一份, 但是切片是引用类型, 传递时只会传递指针
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 var arr [3 ]int arr[0 ] = 1 arr[1 ] = 2 fmt.Println(arr) fmt.Println(len (arr)) fmt.Println(cap (arr)) slice := []int {1 , 2 , 3 , 4 , 5 } fmt.Println(slice) fmt.Println(slice[1 :3 ]) fmt.Println(slice[:3 ]) fmt.Println(slice[3 :]) fmt.Println(len (slice)) slice := make ([]int , 3 , 5 ) fmt.Println(slice) fmt.Println(len (slice)) fmt.Println(cap (slice)) slice = append (slice, 1 , 2 , 3 ) fmt.Println(slice) slice = append ([]int {1 , 2 , 3 }, slice...) fmt.Println(slice) slice = append (slice[:i+1 ], append ([]int {1 , 2 , 3 }, slice[i+1 :]...)...) fmt.Println(slice) slice = slice[:5 ] fmt.Println(slice) slice = slice[1 :] fmt.Println(slice) slice = append (slice[:i], slice[i+1 :]...) fmt.Println(slice) slice = slice[:0 ] fmt.Println(slice) oldSlice := []int {1 , 2 , 3 } newSlice := make ([]int , len (oldSlice)) copy (newSlice, oldSlice)slice := [][]int {{1 , 2 }, {3 , 4 }} fmt.Println(slice)
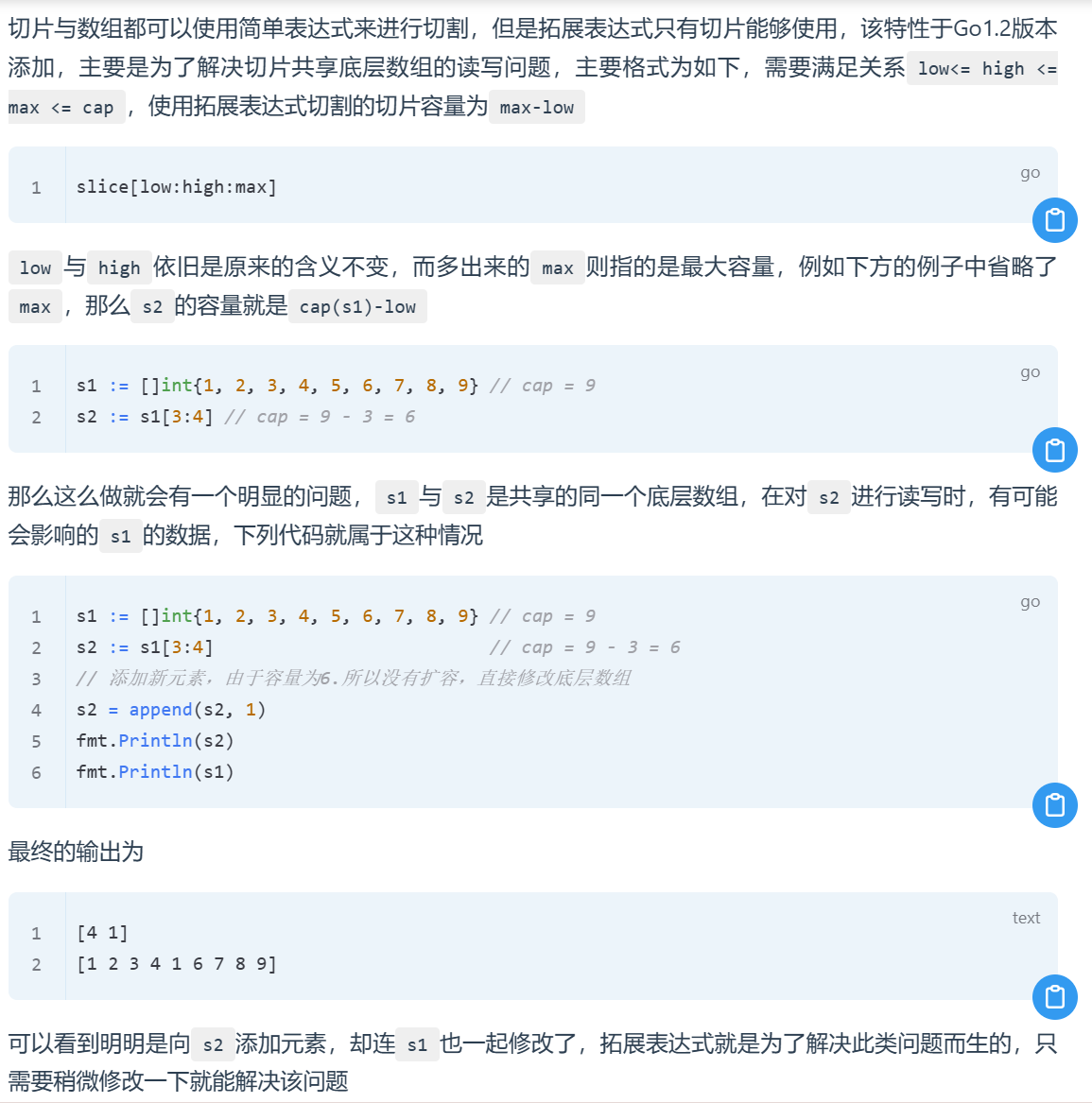
拓展表达式
1 2 3 4 5 6 7 8 func main () s1 := []int {1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 } s2 := s1[3 :4 :4 ] s2 = append (s2, 1 ) fmt.Println(s2) fmt.Println(s1) }
字符串 Go 中的字符串的本质是 [n]byte, 可以使用数组和切片的方式进行操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 str := "Hello, World!" fmt.Println(str[0 ]) fmt.Println(string (str[0 ])) fmt.Println(string (str[0 :5 ])) str[0 ] = 'h' str = "hello" byteStr := []byte (str) fmt.Println(byteStr) fmt.Println(string (byteStr)) byteStr[0 ] = 'H' byteStr = append (byteStr, []byte (" World!" )...) fmt.Println(string (byteStr)) fmt.Println(len (byteStr)) oldStr := "Hello" newStr := make ([]byte , len (oldStr)) copy (newStr, oldStr)newStr = strings.Clone(oldStr) str1 := "Hello" str2 := "World" str3 := str1 + " " + str2 builder := strings.Builder{} builder.WriteString(str1) builder.WriteString(" " ) builder.WriteString(str2) str3 = builder.String()
要遍历打印字符串中的 Unicode 字符, 需要格式化为 rune 类型 (%c)
映射 Go 中的映射是无序的键值对集合, 键值对的类型可以是任意类型, 但是键必须是可以比较的类型 , 如 int, string, float, struct 等
Go 中没有 set 类型, 可以用 map[T]struct{} 来模拟, struct{} 是一个空结构体, 不占用内存
map 不是并发安全的, 如果需要线程安全, 可以使用 sync.Map
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 m := make (map [string ]int , 10 ) m := map [string ]int {"a" : 1 , "b" : 2 } fmt.Println(m["a" ]) fmt.Println(m["c" ]) fmt.Println(len (m)) value, exists := m["c" ] m["c" ] = 3 delete (m, "c" )for key, value := range m { fmt.Printf("key: %s, value: %d\n" , key, value) } for key := range m { delete (m, key) } clear(m)
当键为 math.NaN() 时, 由于 NaN 不等于自身, 所以可以有多个 NaN 键 (其底层由汇编指令 UCOMISD 实现); 应避免用 math.NaN() 作为键
指针 Go 中的指针是一个变量, 其值为另一个变量的地址, 用于存储变量的内存地址; Go 中的指针不能进行运算
1 2 3 4 5 6 7 8 9 10 num := 1 var pointer *int = &num fmt.Println(pointer) fmt.Println(*pointer) pointer := new (int ) fmt.Println(*pointer)
new & make
newmake
语法
pointer := new(T)slice := make([]T, len, cap)
返回值
*TT
参数
类型
类型, 剩余参数由类型决定
用途
给指针分配内存
给切片、映射、通道分配内存
结构体 Go 抛弃了类与继承,同时也抛弃了构造方法,刻意弱化了面向对象的功能,Go 并非是一个面向对象的语言,但是 Go 依旧有着面向对象的影子,通过结构体和方法也可以模拟出一个类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 type Person struct { Name string Age int Hobby []string secret string } type CutePerson struct { Person IsCute bool } p := Person{"小叶子" , 18 , []string {"Reading" , "Painting" }, "Won't tell you" } p := Person{ Name: "小叶子" , Age: 18 , } fmt.Println(p.Name) fmt.Println(p.secret) p := &Person{"小叶子" , 18 , []string {"Reading" , "Painting" }, "Won't tell you" } fmt.Println(p.Name)
函数
Go 中的函数是一等公民, 可以作为参数传递, 也可以作为返回值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 func NameOfFunction (param1 type1, param2 type2) return value } var funcName = func (param1 type1, param2 type2) return value1, value2 } type FuncType func (param1 type1, param2 type2) func Add (a, b int ) int ) { ans := a + b return }
可变参数 1 2 3 4 5 6 7 func sum (args ...int ) int { sum := 0 for _, value := range args { sum += value } return sum }
匿名函数 匿名函数只能在函数内部定义, 但是可以作为返回值
1 2 3 4 5 6 7 8 9 10 11 12 13 func main () func (a, b int ) fmt.Println(a + b) }(1 , 2 ) func addadd (callback func (int , int ) int , c int ) { fmt.Println(callback(1 , 2 ) + c) } addadd(func (a, b int ) int { return a + b }, 3 ) }
闭包 1 2 3 4 5 6 7 8 9 10 11 12 func adder () func (int ) int { sum := 0 return func (x int ) int { sum += x return sum } } func main () add := adder() fmt.Println(add(1 )) fmt.Println(add(2 )) }
defer defer 语句会延迟函数的执行, 直到包含 defer 语句的函数执行完毕后再执行; 通常用于释放资源、关闭文件、解锁等 , 可以写在开启任务的后面, 使代码更加清晰
当有多个 defer 语句时, 其执行顺序是后进先出 的
1 2 3 4 func main () defer fmt.Println("World" ) fmt.Println("Hello" ) }
注意事项 应当避免在 defer 语句中使用使用函数返回值作为参数
1 2 3 4 5 6 7 8 9 10 func main () defer fmt.Println(f()) fmt.Println('3' ) } func f () int { fmt.Println('2' ) return '1' }
方法 Go 中的方法是一种特殊的函数, 其接收者是一个自定义类型, 可以理解为类的方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 type Person struct { Name string Age int } func (p Person) fmt.Println("Hello, I'm" , p.Name) } func (p *Person) p.Age++ } p := Person{"小叶子" , 18 } p.Say() p.Grow() fmt.Println(p.Age)
函数传参时, 会进行值拷贝, 所以推荐使用指针接收者 , 以减少内存开销
接口 Go 中的接口是一种抽象类型, 定义了一组方法, 但是没有具体实现, 只要实现了接口中的所有方法, 就可以称为该接口的实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 type Animal interface { Eat(string ) string Sleep() string } type Cat struct { Name string } func (c *Cat) string ) string { return c.Name + " is eating " + food } func (c *Cat) string { return c.Name + " is sleeping" } func main () var animal Animal = &Cat{"Tom" } fmt.Println(animal.Eat("fish" )) fmt.Println(animal.Sleep()) }
接口是一种隐式实现, 只要实现了接口中的所有方法, 就可以称为该接口的实现, 无需显式 implements
泛型 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 func Add [T int | float ](a, b T) return a + b } fmt.Println(Add(1 , 2 )) fmt.Println(Add[float](1.1 , 2.2 )) type Slice[T any] []Tslice := Slice[int ]{1 , 2 , 3 } type Map[K comparable, V any] map [K]Vm := Map[string , int ]{"a" : 1 , "b" : 2 } type Pair[T any] struct { First, Second T }
any 表示任意类型, 实质是 interface{} 的别名, comparable 表示可比较的类型; 匿名结构体不支持泛型、匿名函数不支持自定义泛型
类型集 类型集是一种泛型约束, 用于限制泛型类型的范围, 只能用于约束泛型, 不能用作类型实参
1 2 3 4 5 6 7 8 9 10 11 12 13 type SignedInteger interface { int | int8 | int16 | int32 | int64 } type UnsignedInteger interface { uint | uint8 | uint16 | uint32 | uint64 } type Integer interface { SignedInteger | UnsignedInteger } func Add [T Integer ](a, b T) return a + b }
错误
Go 中的错误是一个接口, 只要实现了 Error() string 方法, 就可以称为错误
Go 没有 try catch 语句, 通过返回值来处理错误, 如 if err != nil { return err }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import ( "errors" "fmt" ) err := errors.New("This is an error" ) err := fmt.Errorf("This is an error: %s" , "error" ) func f () int , error ) { return 0 , errors.New("This is an error" ) } type MyError struct { Msg string } func (e *MyError) string { return e.Msg }
panic panic 用于引发一个运行时错误, 会导致程序崩溃, 但是可以通过 recover 来捕获 panic 引发的错误
程序退出前会执行所有 defer 语句, 所以可以在 defer 语句中使用 recover 来捕获 panic
1 2 3 4 5 6 7 8 9 10 11 info := "" defer func () if err := recover (); err != nil { fmt.Println("panic error:" , err) } }() if info == "" { panic ("info is empty" ) }
fatal fatal 用于引发一个致命错误, 会导致程序崩溃, 不会执行 defer 语句
1 2 3 4 5 6 import "os" if info == "" { fmt.Println("info is empty" ) os.Exit(1 ) }
一般不会主动触发 fatal, 通常是由于系统错误导致
文件 Go 中的二进制数据是以 []byte 的形式存储的 (类似于 JavaScript 中的 Uint8Array)
常用的文件操作可以使用 os 包实现
打开
函数
描述
os.Open(name string) (*File, error)打开文件, 只读, 实质是 os.OpenFile(name, os.O_RDONLY, 0)
os.OpenFile(name string, flag int, perm FileMode) (*File, error)打开文件, 可以指定打开方式和权限
os.IsNotExist(err error) bool判断错误是否为文件不存在
os.Lstat(name string) (FileInfo, error)获取文件信息
file.Close() error关闭文件, 通常配合 defer 使用
os.Create(name string) (*File, error)创建文件, 实质是 os.OpenFile(name, os.O_RDWR|os.O_CREATE|os.O_TRUNC, 0666), 不支持递归创建目录
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import ( "os" "fmt" ) file, err := os.Open("file.txt" ) if os.IsNotExist(err) { fmt.Println("file not exist" ) } else if err != nil { fmt.Println(err) } else { fmt.Println("file opened" ) defer file.Close() }
模式
模式
描述
os.O_RDONLY只读
os.O_WRONLY只写
os.O_RDWR读写
os.O_APPEND追加
os.O_CREATE不存在则创建
os.O_TRUNC打开时清空
前三个模式必须指定其一, 后面的按需选择
读取
函数
描述
file.Read(p []byte) (n int, err error)读取文件内容到 []byte 中
os.ReadFile(name string) ([]byte, error)读取文件内容到 []byte 中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 import ( "os" "fmt" ) file, _ := os.Open("file.txt" ) defer file.Close()func ReadText (file *os.File) string { buf := make ([]byte , 0 , 1024 ) for { if len (buf) == cap (buf) { buf = append (buf, make ([]byte , 1024 )...) } n, err := file.Read(buf[len (buf):cap (buf)]) if err == io.EOF { buf = buf[:len (buf)+n] break } else if err != nil { fmt.Println(err) break } } return string (buf) } fmt.Println(ReadText(file))
1 2 3 4 5 6 7 8 9 10 11 12 import ( "os" "fmt" ) data, err := os.ReadFile("file.txt" ) if err != nil { fmt.Println(err) } else { fmt.Println(string (data)) }
写入
函数
描述
file.Write(p []byte) (n int, err error)写入 []byte 到文件中
file.WriteString(s string) (n int, err error)写入字符串到文件中
os.WriteFile(name string, data []byte, perm FileMode) error写入 []byte 到文件中
io.WriteString(w Writer, s string) (n int, err error)写入字符串到 Writer 中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import ( "os" "fmt" ) file, _ := os.OpenFile("file.txt" , os.O_RDWR|os.O_APPEND|os.O_CREATE|os.O_TRUNC, 0666 ) defer file.Close()for i := 0 ; i < 10 ; i++ { offset, err := file.WriteString("Hello, World!\n" ) if err != nil { fmt.Println(err, offset) break } }
1 2 3 4 5 6 7 8 9 10 11 import ( "os" "fmt" ) data := []byte ("Hello, World!\n" ) err := os.WriteFile("file.txt" , data, 0666 ) if err != nil { fmt.Println(err) }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import ( "os" "io" "fmt" ) file, _ := os.OpenFile("file.txt" , os.O_RDWR|os.O_APPEND|os.O_CREATE|os.O_TRUNC, 0666 ) defer file.Close()for i := 0 ; i < 10 ; i++ { offset, err := io.WriteString(file, "Hello, World!\n" ) if err != nil { fmt.Println(err, offset) break } }
复制
函数
描述
file.ReadFrom(r io.Reader) (n int64, err error)从 io.Reader 中读取内容到文件中
io.Copy(dst Writer, src Reader) (written int64, err error)复制 Reader 到 Writer 中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import ( "os" "fmt" ) src, _ := os.Open("file.txt" ) defer src.Close()dst, _ := os.Create("file_copy.txt" ) defer dst.Close()n, err := dst.ReadFrom(src) if err != nil { fmt.Println(err) } else { fmt.Println(n) }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import ( "os" "io" "fmt" ) src, _ := os.Open("file.txt" ) defer src.Close()dst, _ := os.Create("file_copy.txt" ) defer dst.Close()n, err := io.Copy(dst, src) if err != nil { fmt.Println(err) } else { fmt.Println(n) }
其他
函数
描述
os.Rename(oldpath, newpath string) error移动文件或目录
os.Remove(name string) error删除文件或空目录
os.RemoveAll(name string) error递归删除目录及其子目录
os.ReadDir(name string) ([]DirEntry, error)读取目录内容
file.Readdir(n int) ([]DirEntry, error)n < 0 读取全部, n > 0 读取 n 个os.ReadDir 的底层原理
os.Mkdir(name string, perm FileMode) error创建目录
os.MkdirAll(path string, perm FileMode) error递归创建目录
filepath.Walk(dir string, walkFn WalkFunc) error递归遍历目录
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 import ( "os" "io" "fmt" "path/filepath" ) func CopyDir (src, dst string ) error { srcInfo, err := os.Stat(src) if err != nil { return err } if !srcInfo.IsDir() { return fmt.Errorf("%s is not a directory" , src) } dstInfo, err := os.Stat(dst) if err != nil { if os.IsNotExist(err) { os.MkdirAll(dst, srcInfo.Mode()) } else { return err } } else if !dstInfo.IsDir() { return fmt.Errorf("%s is not a directory" , dst) } return filepath.Walk(src, func (path string , info os.FileInfo, err error ) error { if err != nil { return err } relPath, err := filepath.Rel(src, path) if err != nil { return err } dstPath := filepath.Join(dst, relPath) if info.IsDir() { return os.MkdirAll(dstPath, info.Mode()) } else { srcFile, err := os.Open(path) if err != nil { return err } defer srcFile.Close() dstFile, err := os.Create(dstPath) if err != nil { return err } defer dstFile.Close() _, err = io.Copy(dstFile, srcFile) return err } }) }
🚧反射 并发 Go 通过 goroutine 实现并发, goroutine 是一种轻量级的线程, 由 Go 运行时管理; 通过 go 关键字后跟一个函数调用 来快速创建一个 goroutine
goroutine 的行为类似于 JavaScript 中的 Promise, 如果不加以控制, 可能会导致程序的主线程提前结束
要控制 goroutine, 可以使用 sync.WaitGroup 来等待所有 goroutine 完成 (类似于 Promise.all); 还可以使用 channel 来进行通信; 以及 context 来控制 goroutine 的生命周期
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import ( "fmt" "sync" ) func main () var wg sync.WaitGroup for i := 0 ; i < 10 ; i++ { wg.Add(1 ) go func (i int ) defer wg.Done() fmt.Println(i) }(i) } wg.Wait() }
channel
channel 是 Go 中的一种数据结构, 用于在 goroutine 之间传递数据, 是一种线程安全 的队列
必须使用 make 创建 channel, channel 有两种类型: unbuffered (同步的) 和 buffered (异步的), 分别对应 make(chan T) 和 make(chan T, n) (其中 n 为缓冲区大小)
对于无缓冲 channel, 发送和接收操作是同步的, 发送操作会阻塞, 直到有其他 goroutine 接收数据; 接收操作也会阻塞, 直到有其他 goroutine 发送数据 (类似于 await)
对于有缓冲 channel, 发送操作不会阻塞, 除非缓冲区满; 接收操作也不会阻塞, 除非缓冲区空
同样可以通过 len 和 cap 函数获取 channel 的长度和容量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import ( "fmt" ) func main () ch := make (chan int , 1 ) defer close (ch) go func () ch <- 123 }() data := <- ch fmt.Println(data) }
加解锁操作 通过一个缓冲区为 1 的 channel 来实现加解锁操作
1 2 3 4 5 6 7 8 9 10 11 12 lock := make (chan struct {}, 1 ) func FetchData () lock <- struct {}{} defer func () <- lock }() }
单向管道 channel 可以通过 chan<- 和 <-chan 限制其方向, 分别表示只能发送和只能接收
1 2 3 4 5 6 7 func Send (ch chan <- int ) ch <- 123 } func Receive (ch <-chan int ) data := <-ch fmt.Println(data) }
遍历管道 通过 range 关键字可以遍历 channel, 但要记得在发送方适时关闭 channel, 否则会导致死锁
1 2 3 4 5 6 7 8 9 10 11 12 ch := make (chan int , 10 ) go func () for i := 0 ; i < 10 ; i++ { ch <- i } close (ch) }() for data := range ch { fmt.Println(data) }
select select 语句用于处理多个 channel 的并发操作, 如果没有 case 可执行, 则会阻塞 (除非存在 default)
每个 case 语句必须是一个 channel 操作 (发送或接收), 当满足多个 case 时, 会随机选择一个执行; 当 default 存在时, 如果没有其他 case 可执行, 则会执行 default (而不会再阻塞)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 func main () ch1 := make (chan int ) ch2 := make (chan int ) ch3 := make (chan int ) defer close (ch1) defer close (ch2) defer close (ch3) Send(ch1, 100 ) Send(ch2, 200 ) Send(ch3, 300 ) lock := make (chan struct {}, 1 ) go func () Loop: for { select { case data, ok := <-ch1: fmt.Println(data, ok) case data := <-ch2: fmt.Println(data) case data := <-ch3: fmt.Println(data) case <-time.After(30 * time.Second): fmt.Println("timeout" ) break Loop } } lock <- struct {}{} }() <-lock } func Send (ch chan <- int , sleepMS int ) for { ch <- 1 time.Sleep(time.Duration(sleepMS) * time.Millisecond) } }
sync.WaitGroup sync.WaitGroup 实质是一个计数器, 用于等待一组 goroutine 完成, 通过 Add 方法增加计数, Done 方法减少计数, Wait 方法等待计数为 0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import ( "fmt" "sync" ) func main () var wg sync.WaitGroup for i := 0 ; i < 10 ; i++ { wg.Add(1 ) go func (i int ) defer wg.Done() fmt.Println(i) }(i) } wg.Wait() }
context
Context 是 Go 提供的一种并发控制的解决方案,相比于管道和 WaitGroup,它可以更好的控制子孙协程以及层级更深的协程
Context 本身是一个接口,只要实现了该接口都可以称之为 context, 例如著名 Web 框架 Gin 中的 gin.Context
context 标准库也提供了几个实现,如 emptyCtx、cancelCtx、timerCtx、valueCtx 等. 这些实现都是不对外暴露的, 只能通过 context 包提供的方法来创建
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 type Context interface { Deadline() (deadline time.Time, ok bool ) Done() <-chan struct {} Err() error Value(key interface {}) interface {} }
context.Background context.Background 是一个 emptyCtx 类型的 context,它是一个空的 context,没有任何值,也没有任何截止时间,也不支持取消, 一般用于根 context
1 2 3 4 5 6 7 8 9 10 11 import ( "context" "fmt" ) func main () ctx := context.Background() fmt.Println(ctx.Deadline()) fmt.Println(ctx.Err()) fmt.Println(ctx.Value("key" )) }
context.TODO context.TODO 是一个 emptyCtx 类型的 context,它和 context.Background 类似,但是它是一个占位符,表示未来会传入一个真正的 context
1 2 3 4 5 6 7 8 9 10 11 import ( "context" "fmt" ) func main () ctx := context.TODO fmt.Println(ctx.Deadline()) fmt.Println(ctx.Err()) fmt.Println(ctx.Value("key" )) }
context.WithValue context.WithValue 用于创建一个带有键值对的 context,它会返回一个 valueCtx 类型的 context,该 context 会在原有的 context 基硿上添加一个键值对
1 2 3 4 5 6 7 8 9 import ( "context" "fmt" ) func main () ctx := context.WithValue(context.Background(), "key" , "value" ) fmt.Println(ctx.Value("key" )) }
context.WithCancel context.WithCancel 用于创建一个可取消的 context,它会返回一个 cancelCtx 类型的 context,该 context 会在原有的 context 基础上添加一个 cancel 方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import ( "context" "fmt" ) func main () ctx, cancel := context.WithCancel(context.Background()) go func () <-time.After(3 * time.Second) cancel() }() <-ctx.Done() fmt.Println("done" ) }
context.WithDeadline context.WithDeadline 用于创建一个带有截止时间的 context,它会返回一个 timerCtx 类型的 context,该 context 会在原有的 context 基础上添加一个截止时间
1 2 3 4 5 6 7 8 9 10 import ( "context" "fmt" ) func main () ctx, cancel := context.WithDeadline(context.Background(), time.Now().Add(3 * time.Second)) <-ctx.Done() fmt.Println("done" ) }
context.WithTimeout context.WithTimeout 用于创建一个带有超时时间的 context,它会返回一个 timerCtx 类型的 context,该 context 会在原有的 context 基础上添加一个超时时间
1 2 3 4 5 6 7 8 9 10 import ( "context" "fmt" ) func main () ctx, cancel := context.WithTimeout(context.Background(), 3 * time.Second) <-ctx.Done() fmt.Println("done" ) }
sync.Mutex sync.Mutex 是一种互斥锁, 用于保护共享资源, 通过 Lock 和 Unlock 方法来控制访问
当一个 goroutine 调用 Lock 方法时, 如果锁已经被其他 goroutine 占用, 则会阻塞, 直到锁被释放; 当一个 goroutine 调用 Unlock 方法时, 会释放锁, 允许其他 goroutine 访问
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import ( "sync" "fmt" ) var mu sync.Mutexvar count int func main () for i := 0 ; i < 10 ; i++ { go func (mu *sync.Mutex) mu.Lock() defer mu.Unlock() count++ }(&mu) } mu.Lock() fmt.Println(count) mu.Unlock() }
注意: 递归锁会导致死锁
sync.RWMutex sync.RWMutex 是一种读写锁, 用于保护共享资源, 通过 RLock 和 RUnlock 方法来控制读访问, 通过 Lock 和 Unlock 方法来控制写访问
方法
描述
RLock读锁定
RUnlock读解锁
Lock写锁定
Unlock写解锁
TryRLock尝试读锁定, 非阻塞, 如果锁已被占用, 则返回 false
TryLock尝试写锁定, 非阻塞, 如果锁已被占用, 则返回 false
下面的 读取 和 写入 是指加读锁和加写锁, 读写数据的操作通常在加解锁之间进行
读锁定时, 允许其他 goroutine 读取, 但不允许写入 (写入时会阻塞)
写锁定时, 不允许其他 goroutine 读取或写入 (读写时会阻塞)
sync.Cond sync.Cond 是一种条件变量, 用于在 goroutine 之间传递信号, 通过 Wait、Signal 和 Broadcast 方法来控制
方法
描述
sync.NewCond(l sync.Locker) *sync.Cond创建一个条件变量
c.Wait()阻塞当前 goroutine, 直到收到 Signal 或 Broadcast 信号
c.Signal()唤醒一个等待的 goroutine
c.Broadcast()唤醒所有等待的 goroutine
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 import ( "sync" "fmt" "time" ) var mu sync.RWMutexvar cond = sync.NewCond(&mu)var count int func main () for i := 0 ; i < 10 ; i++ { go func (count *int , mu *sync.RWMutex) for count < 5 { cond.Wait() } mu.RLock() fmt.Println(count) mu.RUnlock() }(&count, &mu) } for { mu.Lock() count++ mu.Unlock() if count%5 == 0 { cond.Signal() } else if count == 19 { cond.Broadcast() } time.Sleep(time.Second) } }
sync.Once sync.Once 是一种只执行一次的操作, 通过 Do 方法来控制
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import ( "sync" "fmt" ) var once sync.Oncefunc main () for i := 0 ; i < 10 ; i++ { go func () once.Do(func () fmt.Println("only once" ) }) }() } }
对于其他九个 goroutine, Do 方法会直接返回, 不会执行传入的函数
sync.Pool sync.Pool 是一种对象池, 用于存储临时对象, 减少内存分配和释放的频率. 通过 Get 和 Put 方法来控制
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import ( "sync" "fmt" ) var pool sync.Poolfunc main () pool.New = func () interface {} { return "Hello, World!" } for i := 0 ; i < 1000 ; i++ { go func () data := pool.Get().(string ) fmt.Println(data) pool.Put(data) }() } }
上面的例子中, 整个过程只创建/销毁了几个对象, 而不是一千个
注意事项
临时对象 :sync.Pool 只适合存放临时对象,池中的对象可能会在没有任何通知的情况下被 GC 移除,所以并不建议将网络链接,数据库连接这类存入 sync.Pool 中不可预知 :sync.Pool 在申请对象时,无法预知这个对象是新创建的还是复用的,也无法知晓池中有几个对象并发安全 :官方保证 sync.Pool 一定是并发安全,但并不保证用于创建对象的 New 函数就一定是并发安全的,New 函数是由使用者传入的,所以 New 函数的并发安全性要由使用者自己来维护
sync.Map sync.Map 是一种并发安全的 map, 通过 Store、Load、LoadOrStore、Delete、LoadAndDelete、Range 方法来控制
由于需要保证并发安全, sync.Map 相比于 map 会有一些性能损耗
方法
描述
Load(key any) (value any, ok bool)获取指定键的值
Store(key, value any)设置指定键的值
LoadOrStore(key, value any) (value any, loaded bool)获取或设置指定键的值
Delete(key any)删除指定键的值
LoadAndDelete(key any) (value any, loaded bool)获取并删除指定键的值
Range(f func(key, value any) bool)遍历所有键值对, 如果 f 返回 false, 则停止遍历
sync/atomic sync/atomic 包提供了一些原子操作. 原子操作指的是在单个 goroutine 中执行的操作, 不会被其他 goroutine 打断, 保证了操作的完整性
原子类型指的是 atomic.Value (可以存储除 nil 外的任何值)、atomic.Bool、atomic.Int32、atomic.Int64、atomic.Uint32、atomic.Uint64、atomic.Pointer 等, 每个原子类型都有 Load、Store、Swap 等方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import ( "sync/atomic" "fmt" ) func main () var count atomic.Int32 count.Store(123 ) old := count.Swap(456 ) count.Add(1 ) count.Sub(1 ) data := count.Load() }
CompareAndSwap / CAS CompareAndSwap 是一种原子操作, 用于比较并交换, 如果当前值等于旧值, 则将新值存入, 并返回 true, 否则返回 false
CAS 是一种乐观锁
1 2 3 4 5 6 7 8 9 10 11 import ( "sync/atomic" "fmt" ) func main () var count atomic.Int32 ok := count.CompareAndSwap(123 , 456 ) fmt.Println(ok) }
🚧测试