
全栈开发相关学习笔记
封面作者:NOEYEBROW
本文需要您对 JavaScript、TypeScript、HTML、CSS、Go (可选) 等语言有一定了解, 可参考站内相关笔记
运行环境
Node.js
Node.js 是一个基于 Chrome V8 引擎(用 C++ 编写)的跨平台 JavaScript 运行环境, 用于开发服务器端和桌面端的应用程序, 例如 VSCode 就是基于基于 Node.js 的 Electron 框架开发的
Node.js 提供了一些核心模块, 用于处理网络请求 (http、https)、文件操作 (fs、fs/promises)、路径操作 (path)、系统信息 (os) 等, 也可以通过 npm 安装第三方模块
document、window、XMLHttpRequest等对象在Node.js中是不存在的console、setTimeout、setInterval等对象在Node.js中是存在的Node.js中的顶级对象是global, 也可以通过globalThis访问- 推荐将
node内置模块写成node:xxx而不是xxx - 推荐在
package.json中设置"type": "module",并使用ESM替代CommonJS
安装运行
| 命令 | 作用 |
|---|---|
node -v |
查看版本 |
node |
进入交互模式 |
node xxx.js |
运行文件 |
node --watch xxx.js |
运行并监视文件变化Node.js 22.0.0 以上版本支持 |
node --run xxx |
运行 package.json 中的 xxx 脚本Node.js 22.0.0 以上版本支持 |
命令行工具
在 Windows 中, 可以使用 cmd 或 PowerShell 打开命令行工具
- 命令由命令名称和参数组成, 例如
node -v中node是命令名称,-v是参数 - 参数可以没有, 也可以有多个, 相当于函数的参数
VSCode中有内置的终端, 可以直接使用
常用命令
| 命令 | 作用 | 示例 |
|---|---|---|
cd |
切换目录 | cd d:: 切换到 D 盘cd ..: 返回上一级目录cd xxx 或 cd ./xxx: 切换到当前目录下的 xxx 目录 |
dir |
查看目录 | dir: 查看当前目录下的文件和文件夹dir -s: 会展开所有子目录 |
cls |
清屏 | 清除当前命令行窗口的所有内容 |
ctrl + c |
退出当前命令 | 输入 dir -s 后, 按 ctrl + c 可以停止输出 |
NVM
NVM 是 Node.js 的版本管理工具, 可以用于安装、切换、卸载 Node.js 的不同版本; 可以在Github上下载安装包(左侧是 Windows 版本链接)
| 命令 | 作用 |
|---|---|
nvm list |
查看已安装的 Node.js 版本 |
nvm install x.x.x |
安装指定版本的 Node.js, 版本可以是 latest |
nvm use x.x.x |
切换到指定版本的 Node.js |
nvm uninstall x.x.x |
卸载指定版本的 Node.js |
nvm on |
开启 NVM |
nvm off |
关闭 NVM |
Buffer
Buffer 是 Node.js 中的一个全局对象, 类似于 Array, 但长度固定且不可调整, 用于处理二进制数据, 直接操作内存所以性能较好, 每个元素占用一个字节 1 byte 或 8 bit
由于
JavaScript语言自身只有字符串数据类型, 没有二进制数据类型, 所以Node.js提供了Buffer对象来处理二进制数据
创建
| 方法 | 作用 |
|---|---|
Buffer.alloc(size) |
创建一个指定大小的 Buffer, 并用 0 填充 |
Buffer.allocUnsafe(size) |
创建一个指定大小的 Buffer, 不会初始化速度更快, 但可能包含旧的内存数据 |
Buffer.from(str[, encoding]) |
创建一个包含 str 字符串的 Buffer |
Buffer.from(arr) |
创建一个包含 arr 数组的 Buffer |
1 | // 创建 |
JavaScript中number类型用0x...表示十六进制数, 用0b...表示二进制数
属性和方法
| 属性或方法 | 作用 |
|---|---|
buf.length |
返回 buf 的长度(字节数) |
buf[index] |
返回 buf 中指定位置的字节, 类似于数组 |
buf.write(string[, offset[, length]][, encoding]) |
将 string 写入 buf从 offset 开始, 最多写入 length 个字节如果 string 长度大于 buf 的长度, 会截断 |
buf.toString([encoding[, start[, end]]]) |
返回 buf 的字符串形式从 start 到 end |
buf.toJSON() |
返回 buf 的 JSON 对象 |
buf.slice([start[, end]]) |
返回 buf 的一个片段从 start 到 end |
buf.copy(target[, tStart[, sStart[, sEnd]]]) |
将 buf 的一部分复制到 target从 sStart 到 sEnd, 从 tStart 开始写入 |
encoding默认为utf-8;[]表示可选参数, 后同
1 | // 定义一个 Buffer |
常见问题
- 一个字节的
Buffer可以存储256/11111111种不同的值, 即0-255 - 如果试图存入一个超过
255的值, 则只会保留二进制的后8位 - 如
buf[0] = 256会变成0, 因为256的二进制是100000000 UTF-8编码中, 一个中文字符占3个字节, 一个英文字符占1个字节- 而
ASCII编码中, 一个中文字符只占2个字节
计算机相关基础知识
计算机组成
- 计算机主要由
CPU、内存、硬盘 等组成
CPU 用于计算; 移动端一般叫 SOC, 因为还集成了显卡和基带等模块内存 用于存储数据, 速度很快, 但断电后数据丢失硬盘 用于存储数据, 速度较慢, 断电后数据不丢失主板 用于连接各个部件显卡 用于处理图形数据, 并输出到显示器, 可以是独立的, 也可以集成在 CPU 中操作系统 用于管理硬件和软件, 提供用户界面, 调度资源; 例如 Windows、Linux
进程和线程
进程 是程序的一次执行, 是资源分配的基本单位线程 是进程的一个执行流, 是 CPU 调度的基本单位- 一个进程可以包含多个线程
- 例如打开两个
Chrome 窗口, 就是两个进程; 一个 Chrome 窗口中的多个标签页或 WebWorker 就是多个线程
CPU、内存、硬盘 等组成CPU 用于计算; 移动端一般叫 SOC, 因为还集成了显卡和基带等模块内存 用于存储数据, 速度很快, 但断电后数据丢失硬盘 用于存储数据, 速度较慢, 断电后数据不丢失主板 用于连接各个部件显卡 用于处理图形数据, 并输出到显示器, 可以是独立的, 也可以集成在 CPU 中操作系统 用于管理硬件和软件, 提供用户界面, 调度资源; 例如 Windows、Linux进程是程序的一次执行, 是资源分配的基本单位线程是进程的一个执行流, 是CPU调度的基本单位- 一个进程可以包含多个线程
- 例如打开两个
Chrome窗口, 就是两个进程; 一个Chrome窗口中的多个标签页或WebWorker就是多个线程
process
process 是 Node.js 中的一个全局对象, 用于获取 Node.js 进程的信息, 提供了一些方法用于控制 Node.js 进程
| 属性或方法 | 作用 |
|---|---|
process.on('exit', callback) |
在进程退出时执行回调函数 |
process.on('beforeExit', callback) |
在进程退出前执行回调函数 |
process.exit([code]) |
退出进程, code 默认为 0 |
process.upTime() |
返回 Node.js 进程运行的时间 |
process.memoryUsage() |
返回 Node.js 进程的内存使用情况 |
process.cwd() |
返回 Node.js 进程的当前工作目录 |
模块化
老版本 Node.js 中的模块化是基于 CommonJS 规范的, 每个文件就是一个模块, 模块内部的变量和函数默认是私有的, 需要通过 module.exports 导出, 通过 require 引入
CommonJS是一个早期模块化规范, 用于JavaScript语言export和import是ES6中的模块化规范, 用于JavaScript语言;Node.js也支持ES6的模块化规范, 但需要在package.json中设置type字段为module
导出
module.exports是Node.js中的一个全局对象, 用于导出模块exports是module.exports的一个引用, 可以直接使用exports.xxx导出- 如果直接赋值
exports本身, 而不是添加属性或方法, 会导出空对象, 即module.exports对象
1 | module.exports = { |
导入
require是Node.js中的一个全局函数, 用于引入模块require会返回被引入模块的module.exports对象require中的相对路径不会受工作目录影响, 而是相对于当前文件
1 | const obj = require('./xxx.js') |
- 引入
Node.js内置模块或npm安装的包时, 不需要写路径, 直接写模块名即可 - 引入除
.js、.json、.node以外的拓展名的文件, 如.txt时, 会按照.js的方式解析 - 通过
require和解构赋值可以方便地引入JSON文件及其内特定变量 - 引入自定义模块的过程: 将路径解析为绝对路径 → 检测缓存中是否有该模块 → [读取文件内容] → [编译执行文件内容] → [将文件内容放入缓存] → 返回
module.exports对象
对于 require('./xxx') 的情况
1 | // 不写后缀时 |
fs
fs 是 file system 的缩写, 用于与硬盘交互, 提供了文件的读写、删除、重命名等功能; 要使用 fs 等模块, 需要先引入
1 | const fs = require('node:fs') |
文件路径
| 路径 | 类型 | 说明 |
|---|---|---|
./xxx 或 xxx |
相对路径 | 相对于命令行的工作目录 |
../xxx |
相对路径 | 相对于命令行的工作目录的上一级目录 |
/xxx |
绝对路径 | 相对于文件所在盘符的根目录 |
D:/xxx |
绝对路径 | D 盘的 xxx 目录(部分 C 盘目录需要管理员权限) |
__dirname |
绝对路径 | 表示当前文件所在目录的绝对路径 |
__filename |
绝对路径 | 表示当前文件的绝对路径 |
- 可以把
__dirname和__filename看作是Node.js中的全局变量 - 网站的根目录可以利用
__dirname和path模块拼接得到, 例如path.join(__dirname, '/../public') - 若设置了
"type": "module",则应使用import.meta.dirname和import.meta.filename替代__dirname和__filename
1 | // 直接用 ./ 可能达不到预期效果 |
网页路径
本部分不属于 fs 模块, 为便于理解路径, 写在此处
| 路径 | 类型 | 说明 |
|---|---|---|
https://xxx.com/xxx |
绝对路径 | https 协议的 xxx.com 域名的 xxx 路径 |
//xxx.com/xxx |
绝对路径 | 当前协议的 xxx.com 域名的 xxx 路径 |
/xxx |
绝对路径 | 当前协议的当前域名的 xxx 路径 |
./xxx 或 xxx |
相对路径 | 相对于当前网页的路径 |
../xxx |
相对路径 | 相对于当前网页上一级目录的路径 |
浏览器在发送相对路径的请求时, 会自动在当前域名后拼接路径; 如果
../超出了根目录, 会被忽略; 如https://xxx.com/xxx下的../../会被解析为https://xxx.com/而不是https://或404 Not Found
文件写入
| 方法 | 作用 |
|---|---|
fs.writeFile(path, data[, options], callback) |
异步将 data 写入到文件 path |
fs.appendFile(path, data[, options], callback) |
异步追加 data 到文件 path |
fs.writeFileSync(path, data[, options]) |
同步写入文件 |
fs.appendFileSync(path, data[, options]) |
同步追加文件 |
fs.createWriteStream(path[, options]) |
创建一个流式写入对象 频繁写入时不会多次开闭文件 |
以 const ws = fs.createWriteStream(xxx) 为例
| 流式写入对象方法 | 作用 |
|---|---|
ws.write(data[, encoding][, callback]) |
写入数据 |
ws.close([callback]) |
关闭流, 可以不写(脚本结束时会自动关闭) |
options: 一个对象, 用于设置编码、模式等callback: 回调函数, 用于处理结果; 写入完成后调用, 参数为一个错误对象, 如果没错误则为null- 默认情况下, 如果文件不存在, 会创建文件
- 同步写入没有回调函数, 直接返回结果(值同回调函数形参)
- 写入的内容不再能用
HTML的<br>或 等标签, 而是需要使用\n、\t等转义字符 \n: 换行符;\t: 制表符(Tab键);\r: 回车符;\b: 退格符;\\: 反斜杠;\': 单引号;\": 双引号
1 | // 引入 fs 模块 |
options 参数
1 | { |
Node.js中的同步与异步类似于JavaScript, 但其异步代码不是由浏览器开启新线程执行, 而是由Node.js的libuv模块负责调度
文件读取
| 方法 | 作用 |
|---|---|
fs.readFile(path[, options], callback) |
异步读取文件 |
fs.readFileSync(path[, options]) |
同步读取文件, 无回调函数, 直接返回数据 |
fs.createReadStream(path[, options]) |
创建一个流式读取对象 用于分块地读取文件 |
以 const rs = fs.createReadStream(xxx) 为例
| 流式读取对象方法 | 作用 |
|---|---|
rs.on('data', callback) |
读取出一块数据后执行, 回调函数的形参是读取的数据 |
rs.on('end', callback) |
读取完成后执行, 回调函数没有形参 |
rs.on('error', callback) |
读取出错后执行, 回调函数的形参是错误对象 |
rs.pipe(ws) |
将读取的数据写入到 ws 中 |
callback: 回调函数, 用于处理结果; 读取完成后调用, 有两个形参, 第一个是错误对象, 第二个是读取的数据- 读取的数据是
Buffer类型, 需要使用toString/toJSON方法转换为字符串或JSON对象 - 流式读取中,
data事件会多次触发, 每次读取的数据大小由highWaterMark设置决定, 默认64KB - 对于大文件, 如果一次性读取, 会占用大量内存, 可能导致内存溢出, 所以需要使用流式读取
1 | // 引入 fs 模块 |
其他文件操作
| 方法 | 作用 |
|---|---|
fs.rename(oldPath, newPath, callback) |
异步重命名文件 |
fs.copyFile(src, dest[, options], callback) |
异步复制文件 |
fs.rm(path[, options], callback) |
异步删除文件或目录 |
fs.mkdir(path[, options], callback) |
异步创建目录 |
fs.stat(path, callback) |
异步获取文件信息 回调函数第二个形参是文件信息对象 |
fs.readdir(path, callback) |
异步读取目录 回调函数第二个形参是目录下的文件名数组 |
fs.unlink(path, callback) |
异步删除文件 |
fs.rmdir(path, callback) |
异步删除目录 |
callback: 回调函数, 第一个参数都是一个错误对象, 有的还有其他参数- 上述方法都有同步版本, 方法名后加上
Sync并不传入回调函数即可, 如fs.renameSync - 默认不可以删除空目录或一次创建多级目录, 如果要, 需将
options设置为{ recursive: true }
1 | // 重命名文件 |
文件批量重命名
1 | // 引入 fs 模块 |
fs/promises
fs/promises 顾名思义是 fs 模块的 Promise 版本; 方法中的完整参数详见官方文档
1 | import fs from 'node:fs/promises' |
| 方法 | 作用 |
|---|---|
fs.access(path) |
验证访问权限 (或文件存在); 成功返回 null, 失败返回错误对象 |
fs.appendFile(path, data) |
追加文件内容; data: string | Buffer |
fs.copyFile(src, dest) |
复制文件 |
fs.mkdir(path[, options]) |
创建目录; options.recursive: boolean 是否递归创建 |
fs.open(path, flag) |
打开文件, 返回 fs.FileHandle 对象; flag: r/r+/w/w+/a/a+ |
fs.readFile(path) |
读取文件内容 |
fs.rename(oldPath, newPath) |
重命名文件 |
fs.rm(path[, options]) |
删除文件或目录options.recursive: boolean 是否递归删除options.force: boolean 忽略文件不存在带来的错误 |
fs.stat(path) |
获取文件信息, 返回 fs.Stats 对象 |
fs.writeFile(path, data) |
写入文件内容; data: string | Buffer | ... |
path可以是string、Buffer、URL、FileHandle等类型
path
path 是 Node.js 中的一个核心模块, 提供了一些方法用于处理文件路径
1 | const path = require('path') |
| 方法 | 作用 |
|---|---|
path.join([...paths]) |
将所有参数拼接为一个路径 |
path.resolve([...paths]) |
将所有参数拼接为一个绝对路径 |
path.sep |
操作系统的路径分隔符 |
path.basename(path[, ext]) |
返回路径的最后一部分 如果 ext 存在, 则去掉 ext |
path.dirname(path) |
返回路径的目录部分 |
path.extname(path) |
返回路径的扩展名部分 |
path.parse(path) |
返回路径对象 |
path.format(pathObject) |
返回路径字符串 |
利用
path模块可以避免因为不同操作系统的路径分隔符不同而导致的问题
1 | // 引入 path 模块 |
http
http 是 Node.js 中的一个核心模块, 用于创建 HTTP 服务器和客户端; http 模块提供了一个 createServer 方法, 用于创建一个 HTTP 服务器对象
1 | const http = require('http') |
| 服务器对象属性或方法 | 作用 |
|---|---|
server.listen(port[, hostname][, backlog][, callback]) |
监听端口, 启动服务器hostname: 主机名, 默认 localhostbacklog: 最大连接数, 默认 511callback: 服务器启动成功后执行的回调函数 |
server.close([callback]) |
关闭服务器, 服务器关闭后执行回调函数 |
server.on('request', callback) |
监听请求事件 创建服务器时传入回调函数与此效果相同 |
server.on('close', callback) |
监听关闭事件 本地通过 ctrl + c 关闭服务器不会触发 |
server.on('error', callback) |
监听错误事件 |
1 | // 创建服务器 |
请求对象
| 属性或方法 | 作用 |
|---|---|
req.url |
请求的路径和查询参数, 如 /xxx?prompt=xxx和 new 创建的 request 对象不同, 不包含路径前的部分 |
req.method |
请求的方法 |
req.httpVersion |
HTTP 版本 |
req.headers |
请求头对象req.headers['host']: 主机名和端口req.headers['accept']: 接受的数据类型 |
req.on('data', callback) |
监听请求体数据 每次接收到数据时执行, 回调函数的形参是数据块 |
req.on('end', callback) |
监听请求体数据结束 |
req.on('error', callback) |
监听请求体数据错误 回调函数的形参是错误对象 |
以上是
node中request的独特属性, 其他属性和方法见JavaScript学习笔记
响应对象
| 属性或方法 | 作用 |
|---|---|
res.setHeader(name, value) |
设置响应头, value 可以是数组, 此时会设置多个 name 相同的响应头 |
res.write(data) |
写入响应体, 数据可以是字符串或 Buffer 对象 |
res.end([data]) |
结束响应, 可以写入最后一块数据; 只能调用一次(类似于 return) |
res.on('finish', callback) |
监听响应结束事件 |
请求(响应)体实际上是一个可读(可写)流对象, 所以可以使用流的相关方法
简单的注册和登陆
1 | // 引入 http 模块 |
资源类型
Multipurpose Internet Mail Extensions, MIME 是一种互联网标准, 用于表示文档、文件、图像、音频、视频等的类型
Content-Type 是 HTTP 协议的一个头部字段, 用于指定响应体的数据类型; 值的格式为 type/subtype
| 类型 | 说明 | 子类型 | 说明 |
|---|---|---|---|
text |
文本 | text/plaintext/htmltext/csstext/javascript |
纯文本HTML 文档CSS 文件JavaScript 文件 |
image |
图片 | image/jpegimage/pngimage/gifimage/svg+xml |
JPEG 图片PNG 图片GIF 图片SVG 图片 |
audio |
音频 | audio/mpeg |
MP3 音频 |
video |
视频 | video/mp4 |
MP4 视频 |
multipart |
多部分 | multipart/form-data |
表单数据 |
application |
应用程序 | application/jsonapplication/xmlapplication/pdfapplication/octet-streamapplication/x-www-form-urlencoded |
JSON 数据XML 数据PDF 文件二进制数据, 浏览器会自动下载 表单数据 |
Content-Type的值可以包含字符集, 例如text/html; charset=utf-8- 上述设置的优先级高于
HTML中的<meta charset="xxx">标签 CSS和JavaScript文件在执行时会自动以HTML的编码格式解析- 由于浏览器存在资源类型判断机制, 所以有时不设置
Content-Type也可以正常显示资源
静态资源与动态资源
- 静态资源: 不需要经过服务器处理, 直接返回给客户端的资源, 如
HTML、CSS、JavaScript、图片、音视频等 - 动态资源: 需要经过服务器处理后返回给客户端的资源, 如
PHP、JSP、ASP、Servlet等
简单的静态资源服务器
1 | // 引入模块 |
跨域请求
跨域请求指请求的源和资源的源不同, 如 https://a.xxx 通常不能请求 https://b.xxx 的资源; 而 CORS 是 Cross-Origin Resource Sharing 的缩写, 指的是跨域资源共享, 用于解决跨域请求的问题
- 跨域请求分为简单请求和非简单请求
- 简单请求
请求方法为GET、POST、HEAD之一
请求头只包含Accept、Accept-Language、Content-Language、Content-TypeContent-Type为application/x-www-form-urlencoded、multipart/form-data、text/plain之一
客户端会直接发送请求, 再根据响应头决定是否接收响应 - 非简单请求
不符合上述条件的请求
客户端会先发送一个OPTIONS请求, 询问服务器是否允许跨域请求OPTIONS请求由客户端浏览器自动发送, 不需要, 也不能手动发送
服务器将返回以下信息, 客户端浏览器会根据这些信息决定是否发送真正的请求
| 响应头 | 说明 |
|---|---|
| Access-Control-Allow-Origin | 允许跨域请求的源, 可以是 * 或具体的 URL, 多个 URL 用逗号隔开 |
| Access-Control-Allow-Methods | 允许跨域请求的方法, 多个方法用逗号隔开, 简单请求包含的方法不需要设置 |
| Access-Control-Allow-Headers | 允许跨域请求的请求头, 多个请求头用逗号隔开, 简单请求包含的请求头不需要设置 |
| Access-Control-Allow-Credentials | 是否允许发送 Cookie, 默认为 false为 true 时, ...Allow-Origin 不能为 *, 且请求头要包含 credentials: 'include'(针对 fetch) |
| Access-Control-Max-Age | OPTIONS 请求的有效期, 单位为秒, Chrome 默认为 5 秒 |
| Access-Control-Expose-Headers | 允许获取的响应头, 多个响应头用逗号隔开 |
通常对于简单应用只需要设置
Access-Control-Allow-Origin
访问控制
HTTP 协议是无状态的, 即每次请求都是独立的, 服务器无法识别请求是否来自同一个客户端; 为了解决这个问题, 可以使用 Cookie、Session、Token 等技术来实现会话控制
Cookie
Cookie 是 HTTP 协议的一个头部字段, 用于在客户端存储数据, 以便下次请求时发送给服务器; Cookie 保存在浏览器, 每个域名的 Cookie 是独立的(不同域名的 Cookie 不能共享)
Cookie的存储形式是键值对, 如name=xxx; age=xxx- 每次请求时, 浏览器会自动将
Cookie发送给服务器, 服务器可以通过req.headers.cookie获取 - 如果数据量较大, 建议使用
localStorage和sessionStorage来代替Cookie, 见JavaScript学习笔记
| 命令 | 适用对象 | 作用 |
|---|---|---|
document.cookie |
客户端 | 读取或设置 Cookie |
fetch(url,{credentials:'include'}) |
客户端 | 发送请求时携带 Cookie默认为 same-origin |
res.cookie('name', 'value'[, { options }]) |
服务器(express) |
设置 Cookie设置多个 Cookie, 多次调用即可 |
res.setHeader('Set-Cookie','name=value[; options]') |
服务器(http 模块) |
设置 Cookie |
req.clearCookie('name') |
服务器(express) |
清除 Cookie |
res.setHeader('Set-Cookie','name=; Max-Age=0') |
服务器(http 模块) |
清除 Cookie |
options
express |
原生 | 说明 |
|---|---|---|
maxAge |
Max-Age |
Cookie 的有效期, 单位为毫秒, 优先级高于 expires |
expires |
Expires |
Cookie 的过期时间 |
path |
Path |
Cookie 的路径, 只有在该路径下的请求才会发送 Cookie |
domain |
Domain |
Cookie 的域名, 只有在该域名下的请求才会发送 Cookie |
secure |
Secure |
是否只在 HTTPS 连接中发送 Cookie, 默认为 false |
httpOnly |
HttpOnly |
是否只能通过 HTTP 协议访问 Cookie避免用户通过 JavaScript 访问, 默认为 false |
如果不设置
maxAge和expires,Cookie默认为会话Cookie, 即关闭浏览器后失效
读取 Cookie
使用 cookie-parser 中间件可以方便地读取 Cookie, 它会将 Cookie 解析为对象并挂载到 req.cookies 上
1 | # 安装 cookie-parser |
1 | // 引入模块 |
Session
Session 是服务器端的一种会话控制技术, 用于保存用户的会话信息, 如用户的登录状态、购物车、权限等
Session的原理是在客户端保存一个SessionID, 然后在服务器端保存一个Session对象Session ID与Session对象是唯一对应的, 用户在请求时会携带Session ID- 在
express中, 可以使用express-session中间件来实现Session的功能 - 设置上述中间件后, 会在
req对象上挂载一个session对象, 用于读取和设置Session - 还可以使用
connect-mongo中间件将Session保存到MongoDB数据库中 - 相比于
Cookie,Session相对更安全, 且可以保存更多的数据(对于Chrome等浏览器,Cookie的大小限制为4KB)
1 | # 安装 express-session |
1 | // 引入模块 |
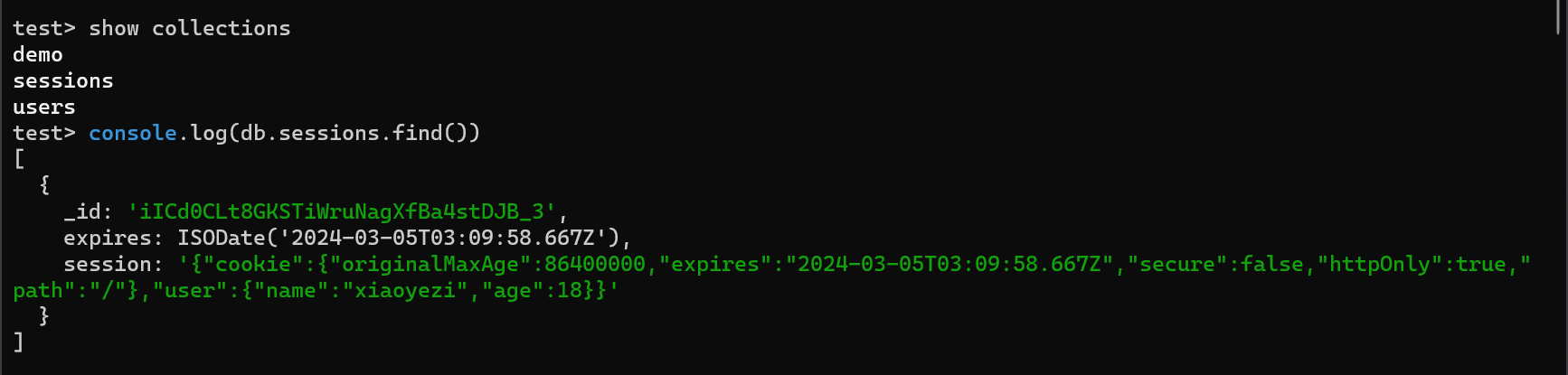
数据库数据示例
CSRF 攻击
CSRF 是 Cross-Site Request Forgery 的缩写, 指的是跨站请求伪造, 是一种网络攻击方式, 攻击者可以利用受害者的身份向服务器发送请求, 执行一些操作, 如转账、发帖等
CSRF攻击的原理是利用受害者的Cookie, 因此可以通过设置SameSite属性来防御CSRF攻击SameSite属性是Cookie的一个属性, 用于指定Cookie是否可以跨站发送, 有三个值:Strict、Lax、NoneStrict: 只有在同源请求时才会发送Cookie, 不同源请求时不会发送Lax: 在GET请求和POST请求时都会发送Cookie, 但是在GET请求中, 如果是跨站请求, 不会发送CookieNone: 无论是GET请求还是POST请求, 都会发送Cookie, 即使是跨站请求也会发送
1 | // 在服务端, 可以将上面的 /logout 路由改为 post 来防御 CSRF 攻击 |
Token
Token 是一种无状态的会话控制技术, 是服务端生成、返回给客户端、内含用户信息的、加密的字符串
- 用户在登陆时, 服务端在验证用户信息后生成一个
Token, 并返回给客户端 - 客户端在请求时携带
Token(通常放在请求头中), 服务端通过解密Token来验证用户身份 Token是加密的, 且加解密过程只会在服务端进行, 客户端无法解密;Token还可以避免CSRF攻击; 所以Token更安全Token的存储位置是客户端, 可以是localStorage、sessionStorage、Cookie等; 且不同于Cookie,Token不会自动发送给服务器, 需要手动设置
JWT
JWT 是 JSON Web Token 的缩写, 是一种 Token 的标准, 用于在网络中传递声明, 通常用于身份验证
JWT由三部分组成, 分别是Header、Payload和Signature, 用.分隔Header是一个JSON对象, 用于描述Token的元数据, 如alg(加密算法)和typ(JWT类型)Payload是一个JSON对象, 用于存放用户信息, 如sub(主题)、exp(过期时间)、iat(签发时间)Signature是Header和Payload的签名, 用于验证Token的完整性
jsonwebtoken
jsonwebtoken 库是 JWT 的一个实现, 用于生成和验证 Token
| 属性或方法 | 作用 |
|---|---|
jwt.sign(data, secretOrPrivateKey, options) |
生成 Token |
jwt.verify(token, secretOrPublicKey, callback) |
验证 Token |
options.expiresIn |
Token 的有效期, 单位为秒 |
options.notBefore |
Token 的生效时间, 单位为秒 |
options.audience |
Token 的受众, 默认为 options.issuer |
options.issuer |
Token 的签发者, 默认为 localhost |
callback |
回调函数, 形参为 err 和 data不写回调函数时, 直接返回 data 或抛出错误 |
1 | # 安装 jsonwebtoken |
1 | // 引入模块 |
命令行交互
inquirer 是一个 Node.js 模块, 可以用于创建交互式命令行工具, 可以用于创建一个命令行工具
1 | # 安装 inquirer |
| 方法 | 作用 |
|---|---|
inquirer.prompt(questionsArray[, answersObj]) |
获取用户的输入, 返回 Promise |
new inquirer.ui.BottomBar() |
创建一个底部栏, 用于显示进度 |
outputStream.pipe(ui.log) |
将输出流导入底部栏 |
ui.log.write('msg') |
在底部栏中显示信息 |
ui.updateBottomBar('msg') |
更新底部栏的信息 |
inquirer是纯es module, 不支持CommonJS, 需要使用import导入inquirer的prompt方法返回一个Promise对象, 可以使用await来获取用户的输入、用then、catch来处理用户的输入
Questions
questionsArray 是一个数组, 数组中的每个元素都是一个 question 对象, 用于定义问题的类型、提示信息、默认值等
| 属性 | 作用 |
|---|---|
type |
问题的类型, 如 input、confirm、password |
name |
问题的名称, 用于把值存储到 answersObj.name 中 |
message |
问题的提示信息 |
choices |
问题的选项数组 |
default |
问题的默认值, 可以是值或函数(的返回值) |
validate |
答案的验证函数, 应返回 true 或 false |
filter |
答案的过滤函数, 应返回过滤后的值 |
transformer |
问题的转换函数, 应返回转换后的值, 用于隐藏密码等 |
只有前三个是所有
type都必须有的
type
| 类型 | 作用 |
|---|---|
list |
选择一个选项, 需要设置 choices |
rawlist |
选择一个选项(数字序号), 需要设置 choices |
expand |
选择一个选项(指定序号), 需要设置 choiceschoice 需要额外设置 key 作为序号 |
checkbox |
选择多个选项, 需要设置 choiceschoice 可选设置 checked 为 true |
confirm |
选择 yes 或 no |
input |
输入一个值 |
password |
输入一个密码 |
editor |
打开一个文本编辑器, 关闭后返回输入的值 |
choices
choices 是一个数组, 数组中的元素可以是一个值, 也可以是一个 choice 对象, 用于定义选项的值、显示的文本等
1 | const questions = [ |
示例
这是我的爬虫练习小程序的一个片段
1 | import inquirer from 'inquirer' |
RESTful API
接口 Application Programming Interface, API 是一种用于连接不同软件、不同模块、网站前后端等的数据交换方式; 一个接口由 URL、请求方法、请求参数、响应数据 等组成, 可以在这里查看一个接口文档的示例, 也可以在这里查看一些免费的接口
而 RESTful 是一种软件架构风格, 是一种设计 API 的方式, 可以用于创建 Web 服务; 用任何语言都可以创建 RESTful API, 只要遵循 REST 的设计风格即可:
URL代表资源, 路径中不应包含动词HTTP方法应代表对资源的操作, 如GET、POST、PUT、DELETE等HTTP状态码应代表操作的结果, 如200、404、500等RESTful API一般使用JSON格式来传输数据
前面说的用
GET / POST方法来进行所有操作的设计实际上是不符合RESTful的设计风格的
json-server
json-server 是一个 Node.js 模块, 可以用于快速创建 RESTful API
1 | # 安装 json-server |
1 | // db.json |
接口测试
Postman、APIpost、APIfox 等都是一些常用的接口测试工具, 可以用于测试接口; 其中, Postman 提供了 VScode 插件, 可以直接在 VScode 中测试接口, 推荐使用
Postman似乎会无视Access-Control-Allow-Origin, 始终显示返回的数据
本地域名
hosts 文件是一个没有扩展名的系统文件, 用于将域名映射到 IP 地址, 可以用于本地开发和测试
- 访问域名时, 操作系统会先在
hosts文件中查找, 然后再去DNS服务器查找 hosts文件的位置是C:\Windows\System32\drivers\etc\hosts, 可以使用记事本打开hosts文件的格式是IP地址、域名, 用任意数量的空格分隔, 如127.0.0.1 bnu.edu.cn- 可以用
hosts文件来屏蔽广告、防止应用在线更新等, 如127.0.0.1 ad.xxx.com
Deno
Deno 是一个基于 V8 引擎的 JavaScript 和 TypeScript 运行时, 由 Node.js 的创始人 Ryan Dahl 开发, 目的是解决 Node.js 的一些问题
介绍
Deno是一个安全的运行时环境, 它默认不允许访问文件系统、网络和环境变量, 除非显式授权Deno内置了TypeScript编译器, 无需安装额外的工具Deno使用ES Modules, 不再支持CommonJS模块Deno所有的异步操作都返回Promise, 不再使用传统回调函数Deno通过URL导入模块, 可以不再使用node_modules目录Deno可以简单地将JS或TS文件编译为可执行文件Deno旨在兼容WebAPI, 如fetch、prompt等Deno的内置 API 都在全局对象Deno上
| 命令 | 说明 |
|---|---|
deno |
进入 Deno 的交互式命令行 |
deno --version |
显示 Deno 版本 |
deno upgrade [--version x.x.x] |
更新 Deno 版本 |
deno init |
创建一个 Deno 项目 |
deno xxx.ts |
运行 .js 或 .ts 文件 |
deno run [--watch] [安全选项] xxx.ts或url或npm:cowsay [args] |
运行本地、远程、模块脚本 |
deno test [--watch] |
运行测试文件 |
deno fmt [--check] |
格式化文件, 取代 prettier; --check 表示仅检查 |
deno lint |
检查代码风格, 取代 eslint |
deno add jsr/npm:xxx |
添加 jsr 或 npm 模块到 deno.json |
- 运行选项应放在
run等命令之后,xxx之前 --watch: 选项可以监视文件变化, 自动重新执行命令--watch-hmr: 尝试使用HMR(热模块替换)来更新模块--watch-exclude=xxx.ts,xxx.ts: 排除监听指定文件--no-remote: 禁止远程导入--unstable: 允许不稳定的API- 安全选项
注意: localStorage 等 WebAPI 也属于文件系统--allow-all/-A: 允许所有权限--allow-net[=IP/HOSTNAME]: 允许网络访问--allow-read[=PATH]: 允许读取文件--allow-write[=PATH]: 允许写入文件--allow-env[=KEY]: 允许访问环境变量--allow-run[=PROGRAM]: 允许运行子进程
- 在
xxx之后的所有选项都会被传递给xxx内的Deno.args数组
1 | // 如果要引入 node 模块 |
1 | # 创建一个 Deno 项目 |
deno.json
1 | { |
Deno也可以解析package.json文件Deno不推荐手动设置TypeScript配置, 而是使用默认配置
JSR和标准库
JSR 是一个现代的 JavaScript 模块注册机构, 内部的模块被要求类型安全; JSR 还会标注每个模块的可用平台, 如 Deno、Node.js、Web、Workers 等
Deno 的标准库也存放于 JSR 中, 例如 jsr:@std/fs、jsr:@std/path 等
JSR在node.js中同样可用, 只需运行bunx jsr add xxx即可
Deno KV
本部分笔记写于 Deno 1.x 时期, 且 Deno KV 本身属于不稳定的 API, 可能会有变动
Deno 提供了内置的 KV 存储驱动, 用于存储键值对数据, 可以在本地或 Deno Deploy 上直接使用
本地访问远程 KV 存储时, 需要将 Deno Deploy 的 Access Token 设置为环境变量 DENO_KV_ACCESS_TOKEN, 并在调用 Deno.openKv 时传入数据库的 URL 作为参数
key 是一个数组, 元素按照重要性先后排列, 如 ['user', 'xiaoyezi']; 元素可以是 Uint8Array、string、number、bigint、boolean; value 是一个对象
| 方法 | 说明 |
|---|---|
Deno.openKv(['URL']) |
打开 KV 数据库 |
kv.close() |
关闭 KV 数据库 |
kv.delete(key) |
删除键值对 |
kv.get(key) |
获取键值对 |
kv.getMany(keysArray) |
获取多个键值对 |
kv.list(selector) |
列出键值对, 返回迭代器而不是 Promise但遍历迭代器时会返回 Promise |
kv.set(key, value[, { expireIn }]) |
设置键值对expireIn: 过期时间(毫秒) |
- 获取到的多个键值对是一个
KvListIterator类的可迭代对象, 也可以用[]访问其元素 - 获取到的键值对是一个
Deno.KvEntry类的实例对象:{ key: KvKey; value: T; versionstamp: string; } selector是一个Deno.KvListSelector类的实例对象:{ prefix: KvKey; }(前缀选择器); 详见官方文档
1 | // 打开 KV 数据库 |
常见问题
要这么写才对, 而不是在 kv.list 前加 await
1 | const test = kv.list({ prefix: [params.hostname, 'visitors'] }) |
Bun
Bun 也是一个 JavaScript 和 TypeScript 运行时, 基于 JavaScriptCore 而不是 V8; 相比于 Deno, Bun 更注重于 Node.js 的兼容性, 可以无痛迁移, 也可以作为类似 npm 的包管理器使用
Bun 的内置 API 都挂载于全局对象 Bun 上, 与 Deno 的 Deno 对象类似; 并且也支持很多 WebAPI
1 | # 安装 (Windows) |
1 | Bun.serve({ |
Runtime
bun |
node |
|---|---|
bun [--watch] [run] x.js/ts/jsx/tsx |
node xxx.js |
bun [run] xxx |
npm run xxx |
bun run --bun xxx |
强制使用 Bun 运行脚本忽略 #!/usr/bin/env node 声明 |
bun init |
pnpm init |
bun create xxx |
pnpm create xxx |
- 内置命令和
package.json冲突时, 优先使用内置命令; 此时应使用bun run xxx而不是bun xxx - 通过
bun add -d @types/bun可以安装Bun的类型声明文件
.env
Bun 会自动按顺序读取以下环境变量文件 (无需 dotenv), 并挂载到 process.env 上 (但也可以通过 Bun.env 或 import.meta.env 获取)
- 通过命令行传递:
KEY=VALUE bun run dev - 手动指定文件:
bun --env-file=xxx run dev .env.local.env.production/.env.development/.env.test(根据NODE_ENV环境变量).env
1 | # .env |
1 | // 读取环境变量 |
import.meta
| 属性 | 说明 |
|---|---|
import.meta.dirnameimport.meta.dir |
当前模块目录的绝对路径 |
import.meta.filenameimport.meta.path |
当前模块的绝对路径 |
import.meta.file |
当前模块的文件名, 如 xxx.ts |
import.meta.main |
是否为主模块, 类似于 Python 的 __name__ == '__main__' |
import.meta.url |
以 file:// 开头的当前模块的绝对路径 |
Shell
1 | // 引入 Shell 模块 |
🚧 Redirect
1 | import { $ } from 'bun' |
File I/O
| 方法 | 说明 | 类型 |
|---|---|---|
Bun.file('path'[, options]) |
创建文件对象 | (string, object?) => BunFile |
Bun.stdin |
标准输入 | 只读 BunFile |
Bun.stdout |
标准输出 | BunFile |
Bun.stderr |
标准错误 | BunFile |
Bun.write(dest, data) |
写入文件 | (string | URL | BunFile, string | Blob | BunFile | ArrayBuffer | TypedArray | Response) => Promise<number> |
Bun.file的path可以指向不存在的文件, 可以通过options.type来指定文件类型, 如text/plain;charset=utf-8,application/json
BunFile
| 方法 | 说明 | 类型 |
|---|---|---|
file.size |
文件大小 | number |
file.type |
文件 MIME 类型 |
string |
file.exists() |
判断文件是否存在 | Promise<boolean> |
file.text() |
读取文件 | Promise<string> |
file.stream() |
读取文件 | Promise<ReadableStream> |
file.arrayBuffer() |
读取文件 | Promise<ArrayBuffer> |
file.bytes() |
读取文件 | Promise<Uint8Array> |
file.writer([options]) |
创建 FileSink 对象 |
Promise<FileSink> |
FileSink
| 方法 | 说明 | 类型 |
|---|---|---|
writer.write(data) |
写入缓存 | void |
writer.flush() |
写入本地磁盘 | void |
writer.end() |
写入并关闭文件 | void |
file.writer的options.highWaterMark可以自定义缓存区大小, 达到缓存大小后会自动flush
SQLite
Bun 原生实现了一个高性能 SQLite3 数据库驱动, 可以直接通过 bun:sqlite 引入
1 | import { Database } from 'bun:sqlite' |
注意: 与
PostgreSQL等一般数据库不同,SQLite的一个文件就是一个数据库
包管理工具
包 package 指一些特定功能源码的集合, 而包管理工具则是用于安装、卸载、更新、发布、管理包的工具, 如 python 的 pip、Java 的 Maven
bun pm
bun |
pnpm |
|---|---|
bun install/i |
pnpm i |
bun update |
pnpm up |
bun add/a xxxbun add/a --dev/-d/-D xxxbun add/a --global/-g xxx |
pnpm add xxxpnpm add -D xxxpnpm add -g xxx |
bun remove/rm xxx |
pnpm rm xxx |
bun pm ls [-g] |
pnpm list [-g] |
bunx [--bun] xxxbun x [--bun] xxx |
pnpx xxx |
bun publish |
pnpm publish |
bun pm whoami |
pnpm whoami |
--bun会强制使用Bun运行脚本, 忽略#!/usr/bin/env node声明- 如果没有
node_modules目录,Bun会像Deno一样自动安装依赖 (到全局缓存)
npm
JavaScript 中常用的包管理工具是 npm, 它是 Node.js 自带的包管理工具, 可以用 npm -v 验证是否安装并查看版本
在操作系统层面也有包管理工具, 用于管理软件包, 如
Ubuntu的apt、CentOS的yum、Windows的chocolatey
全局与本地
- 全局安装: 安装在
Node.js的安装目录下, 可以在命令行中直接使用 - 本地安装: 安装在当前项目的
node_modules目录下, 只能在当前项目中使用 - 只有一些命令行工具才需要全局安装
- 在
windows中, 可能需要以管理员身份运行命令行才能全局安装包
| 命令 | 作用 |
|---|---|
npm install -g xxx |
全局安装 xxx 包 |
npm uninstall -g xxxnpm remove -g xxx |
全局卸载 xxx 包 |
npm update -g xxx |
全局更新 xxx 包 |
npm list -g |
查看全局下的所有包 |
计算机环境变量
windows 中, 可以在 系统属性 -> 高级系统设置 -> 环境变量 中设置环境变量; 在命令行执行某个命令时, 会先在当前目录下查找, 然后在环境变量 Path 中的目录下查找(优先查找系统的环境变量, 然后查找用户的环境变量)
环境变量的作用是为了方便在任意目录下使用某些命令行工具, 如 node、npm、git 等
初始化
| 命令 | 作用 |
|---|---|
npm init |
交互式地初始化一个 package.json 文件将当前工作目录作为一个项目(包)的根目录 |
npm init -y |
快速初始化一个 package.json 文件使用默认值, 不需要交互 |
package.json是一个JSON格式的文件, 用于描述项目的信息和依赖dependencies是项目运行时需要的依赖, 如框架、库等, 在生产和开发环境中都使用devDependencies是开发时需要的依赖, 如测试框架、打包工具等, 只在开发环境中使用scripts是一些脚本命令, 可以通过npm run xxx来执行scripts中的start是一个特殊的脚本命令, 可以直接通过npm start来执行npm run xxx同样有向上级目录查找的特性, 所以可以在package.json所在的目录的子目录中执行
1 | { |
设置
bin属性后, 可以在命令行中直接使用xxx命令, 会执行./bin/xxx.js文件 (用户全局安装后)
命令行工具
可以在 package.json 中的 bin 属性中设置命令行工具, 然后在 bin 目录下创建一个 xxx.js 文件, 用于处理命令行参数
1 | // bin/hello.js |
1 | // package.json |
1 | # 全局安装 |
安装包
可以在 npm 的官网 npmjs.com 上搜索需要的包, 然后在命令行中安装
| 命令 | 作用 |
|---|---|
npm install |
安装 package.json 中的所有依赖第一次运行时, 会在当前目录下创建 node_modules 目录和 package-lock.json 文件 |
npm install xxxnpm install --save xxx |
安装 xxx 包并将其添加到 dependencies 中 |
npm install xxx@x.x.xnpm install --save xxx@x.x.x |
安装指定版本的 xxx 包并将其添加到 dependencies 中 |
npm install -D xxxnpm install --save-dev xxx |
安装 xxx 包并将其添加到 devDependencies 中 |
- 上面的
install命令可以简写为i - 安装包时, 会自动安装其依赖包至
node_modules目录下, 但不会在package.json中显示 package-lock.json文件用于锁定依赖的版本, 防止不同环境下安装的依赖版本不一致- 用
npm install安装依赖时, 会根据package-lock.json文件中的版本号来安装依赖 - 用
require('xxx')引入的包会优先从./node_modules目录下查找, 然后查找../node_modules目录, 以此类推 require('./node_modules/xxx')一般与require('xxx')等价, 但不会向上级目录查找- 根据模块化一节中的知识, 导入包实质上是导入包的入口文件
node_modules目录下的包不需要上传到git仓库(太多了), 所以克隆的项目需要重新安装依赖
其他包命令
| 命令 | 作用 |
|---|---|
npm uninstall xxxnpm remove xxx |
卸载 xxx 包 |
npm update |
更新 package.json 中的所有依赖 |
npm update xxx |
更新 xxx 包 |
npm list |
查看当前目录下的所有包 |
npm info xxx |
查看 xxx 包的信息 |
npm uninstall和npm remove可以简写为npm r- 更新包时, 会更新
package.json中的版本号, 然后重新安装依赖 - 如果
package.json中的版本号含^或~, 会根据语义化版本规范来更新 - 如果存在
package-lock.json文件, 更新包时会根据package-lock.json文件中的版本号来更新
语义化版本规范
Semantic Versioning, 简称 SemVer, 是一种版本号规范, 用于描述包的版本号, 对于 x.y.z 形式的版本号, 有以下规定
x: 主版本号, 当做了不兼容的 API 修改时, 增加y: 次版本号, 当做了向下兼容的功能性新增时, 增加z: 修订号, 当做了向下兼容的问题修正时, 增加^x.y.z:x不变,y和z可以更新到最新^0.y.z:0和y不变,z可以更新到最新~x.y.z:x和y不变,z可以更新到最新*: 任意版本
npx
npx 是 npm 自带的一个包运行器, 用于运行本地安装的包, 或者直接运行远程的包
运行 npx command 会自动地在项目的 node_modules 文件夹中找到命令的正确引用, 而无需知道确切的路径, 也不需要在全局和用户路径中安装软件包; 甚至, 当找不到本地包时, npx 还会询问你是否安装它
1 | # Hexo 相关命令 |
如果不使用
npx, 则需要在package.json中的scripts中设置命令, 然后通过npm run xxx来执行项目中的命令
发布包
类似于 GitHub, npm 也是一个开源的包管理平台, 可以将自己的包发布到 npm 上
| 命令 | 作用 |
|---|---|
npm login |
登录 npm |
npm publish |
发布包 |
npm unpublish <name> |
撤销发布 xxx 包, 只会撤销最近的一个版本 |
npm logout |
登出 npm |
npm whoami |
查看当前登录的用户 |
- 发布包时, 会将当前目录下的
package.json文件中的name和version作为包的名称和版本号 - 发布包时, 会将当前目录下的所有文件上传到
npm上, 所以需要在.gitignore文件中忽略一些文件 - 发布前必须先将镜像源切换至
npm官方源, 如执行:npm config set registry https://registry.npmjs.org
或nrm use npm - 用上面的命令可能报错, 查看错误信息即可, 为避免误操作删除不该删除的包, 这里不再提供详细的命令
yarn
yarn 是 Facebook 开发的包管理工具, 与 npm 类似, 但更快、更安全、更可靠
1 | # 安装 yarn |
yarn也可以通过yarn config set registry https://registry.npm.taobao.org来切换至淘宝镜像yarn用于锁定依赖的版本的文件是yarn.lock, 与npm不同- 尽量不要同时使用
npm和yarn来安装依赖
| 项目命令 | 作用 |
|---|---|
yarn init [-y] |
初始化一个 package.json 文件 |
yarn add xxx[@x.x.x] |
安装 xxx 包并将其添加到 dependencies 中 |
yarn add xxx[@x.x.x] --dev |
安装 xxx 包并将其添加到 devDependencies 中 |
yarn remove xxx |
卸载 xxx 包 |
yarn |
安装 package.json 中的所有依赖 |
yarn upgrade |
更新 package.json 中的所有依赖 |
yarn upgrade xxx |
更新 xxx 包 |
yarn list |
查看当前目录下的所有包 |
yarn xxx |
执行 package.json 中的 scripts 中的 xxx 脚本简化了 run 命令, 所以注意自定义的脚本命令不能与 yarn 的命令重名 |
| 全局命令 | 作用 |
|---|---|
yarn -v |
验证是否安装并查看版本 |
yarn global bin |
查看全局安装的包的路径 |
yarn global add xxx |
全局安装 xxx 包 |
yarn global remove xxx |
全局卸载 xxx 包 |
yarn global upgrade |
更新全局安装的包 |
yarn global list |
查看全局下的所有包 |
yarn config list |
查看 yarn 的配置 |
pnpm
pnpm 会把所有依赖安装在一个地方, 并使用符号链接的方式链接到各个项目, 节省校园网流量
1 | # 安装 pnpm |
pnpm |
npm |
|---|---|
pnpm install/i |
npm install |
pnpm add [-D/-g] xxx |
npm install [-D/-g] xxx |
pnpm update/up [-g] [xxx] |
npm update [-g] [xxx] |
pnpm remove/rm [-D/-g] xxx |
npm uninstall [-D/-g] xxx |
pnpm prune |
移除不需要的依赖 |
pnpm list [-g] |
npm list [-g] |
pnpm [run] xxx |
npm run xxx |
pnpx xxx |
npx xxx |
如果运行有问题, 可能需要手动设置环境变量: 将
PNPM_HOME设置为你想要的路径如C:\Users\xxx\pnpm,然后在Path中添加%PNPM_HOME%
首次安装 (如在C盘) 后, 如果出现在其他盘符 (如D盘) 上的包存放位置错误的问题, 可以先在正确的目录运行pnpm store path获取正确位置, 再运行pnpm config set store-dir 刚才的正确位置进行设置
打包工具
Webpack
Webpack 是一个现代 JavaScript 应用程序的静态模块打包器 module bundler, 它主要用于打包 JavaScript 模块, 但也能够打包 CSS、HTML、图片、字体等文件
1 | # 全局安装 |
webpack是Webpack的核心包,webpack-cli是Webpack的命令行工具- 注意: 默认状态下,
webpack打包的入口文件是src/index.js, 输出文件是dist/main.js ES6模块化语法import和export以及CommonJS模块化语法require和module.exports都可以被Webpack解析, 但建议不要混用Node.js中的模块化语法require和module.exports不能直接在浏览器中使用, 需要通过Webpack打包npm包无法通过script标签或import语句直接在浏览器中使用, 也需要通过Webpack打包, 或者使用CDN引入
| 打包前 | 打包后 |
|---|---|
 |
 |
上面的警告会在创建下面的配置文件后消失
完整配置示例
1 | // package.json |
1 | // webpack.config.js |
配置
Webpack 的配置文件是 webpack.config.js, 它是一个 CommonJS 模块, 返回一个配置对象; Webpack 会自动查找当前目录下的 webpack.config.js 文件
默认情况下, Webpack 不会创建 HTML 文件, 可以使用 HtmlWebpackPlugin 插件来生成 HTML 文件
1 | # 安装插件 |
1 | const path = require('path') |
| 打包前 | 打包后 |
|---|---|
 |
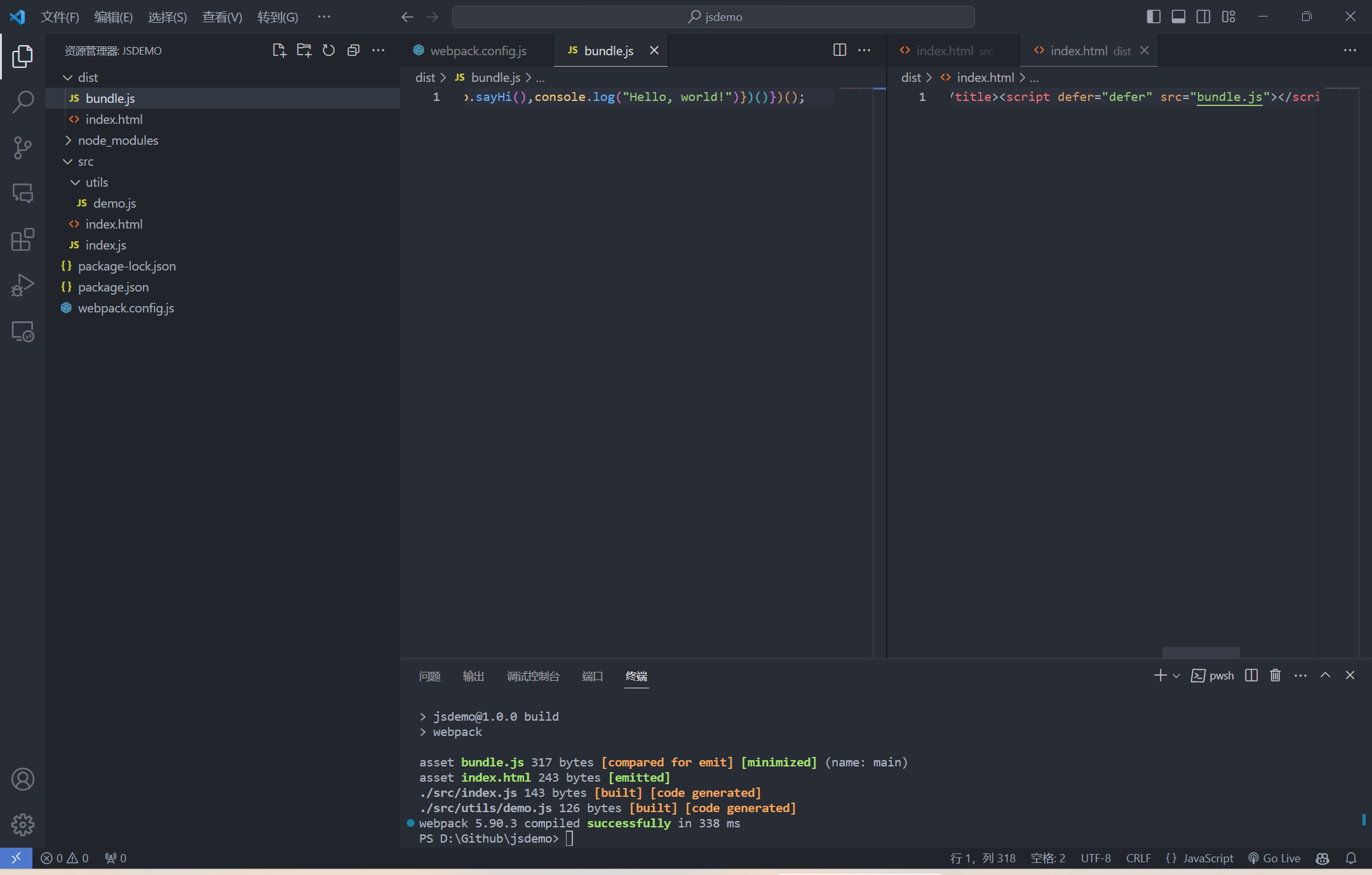 |
打包后的
bundle.js在加入HTML时会自动添加defer属性, 在HTML加载完后再执行
引入 CDN
externals 对象用于配置哪些模块不应该被 webpack 打包, 而是在运行时从环境中的某个特定环境变量获取
1 | // webpack.config.js |
1 | <!-- index.html --> |
- jsDelivr
- unpkg
- BootCDN: 国内访问较快
- CDNJS
- Cloudflare: 主要用于加速网站(
在国内可能是减速), 需要你的域名使用Cloudflare解析
多页面打包
1 | // webpack.config.js |
分割公共代码
splitChunks 对象用于配置 Webpack 如何将模块分割成块, 并将这些块作为单独的文件加载; 可以将公共的模块提取到一个单独的文件中, 以便多页面共享, 减少加载时间
1 | // webpack.config.js |
集成打包 CSS
Webpack 只能处理 JavaScript 和 JSON 文件, 其他类型的文件需要使用加载器 loader 来处理
1 | # 安装加载器 |
1 | // webpack.config.js |
| 打包前 | 打包后 |
|---|---|
 |
 |
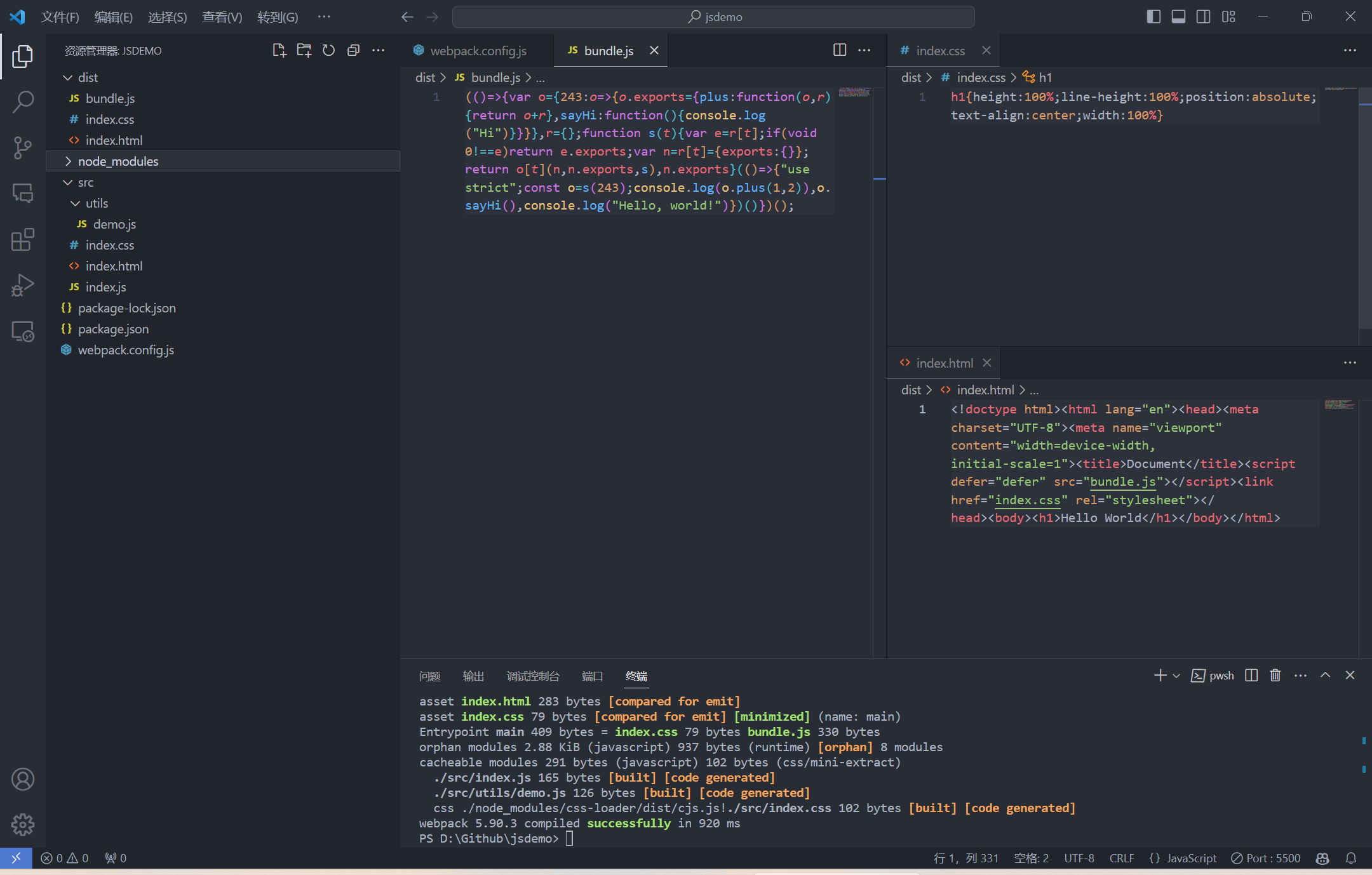
单独打包 CSS
上述方法会将所有的 JavaScript 和 CSS 文件打包到一个文件中, 但有时需要将 CSS 文件单独打包, 从而优化加载速度
1 | # 安装插件 |
1 | // webpack.config.js |
| 打包前 | 打包后 |
|---|---|
 |
 |
打包其他资源
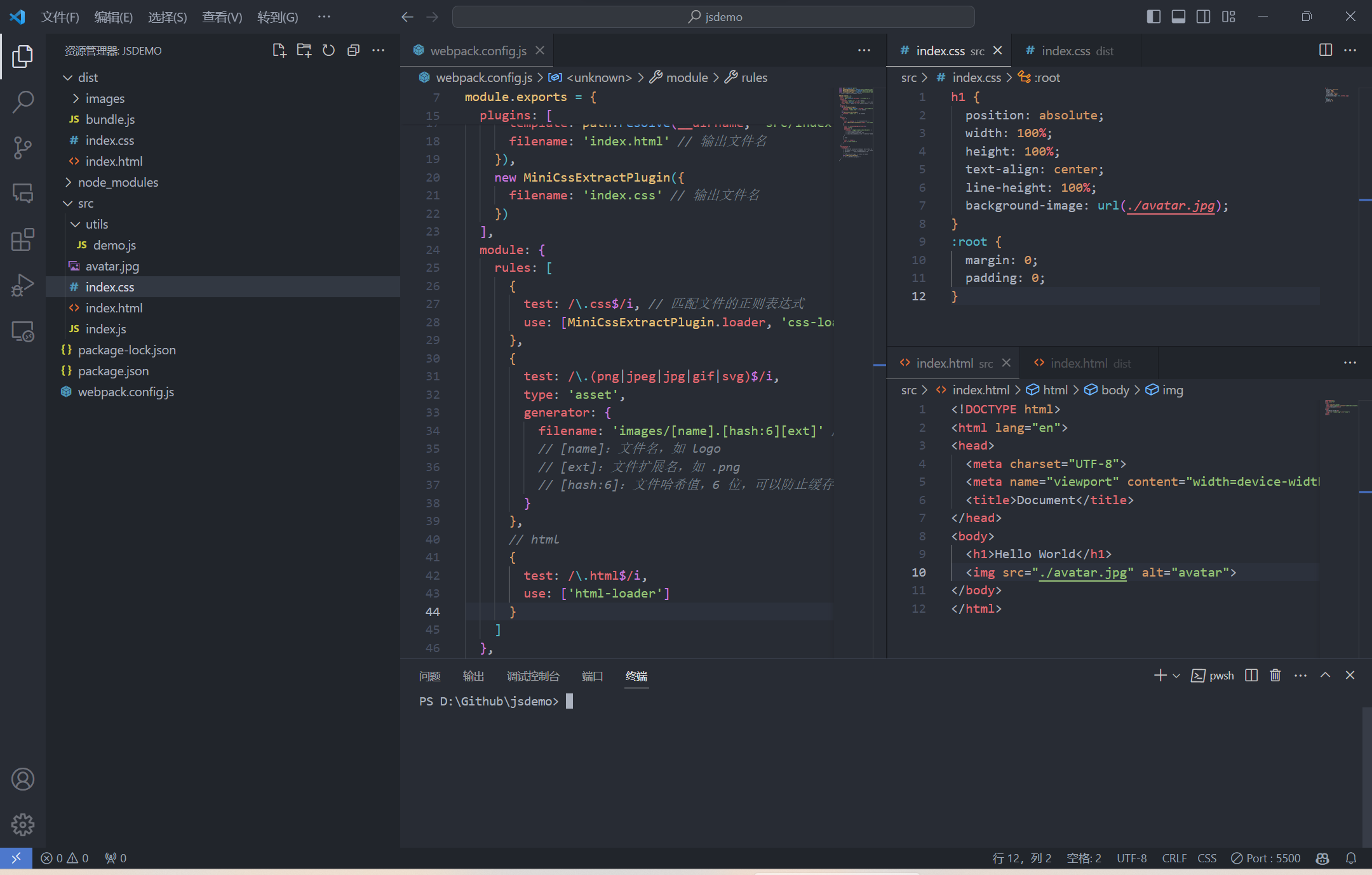
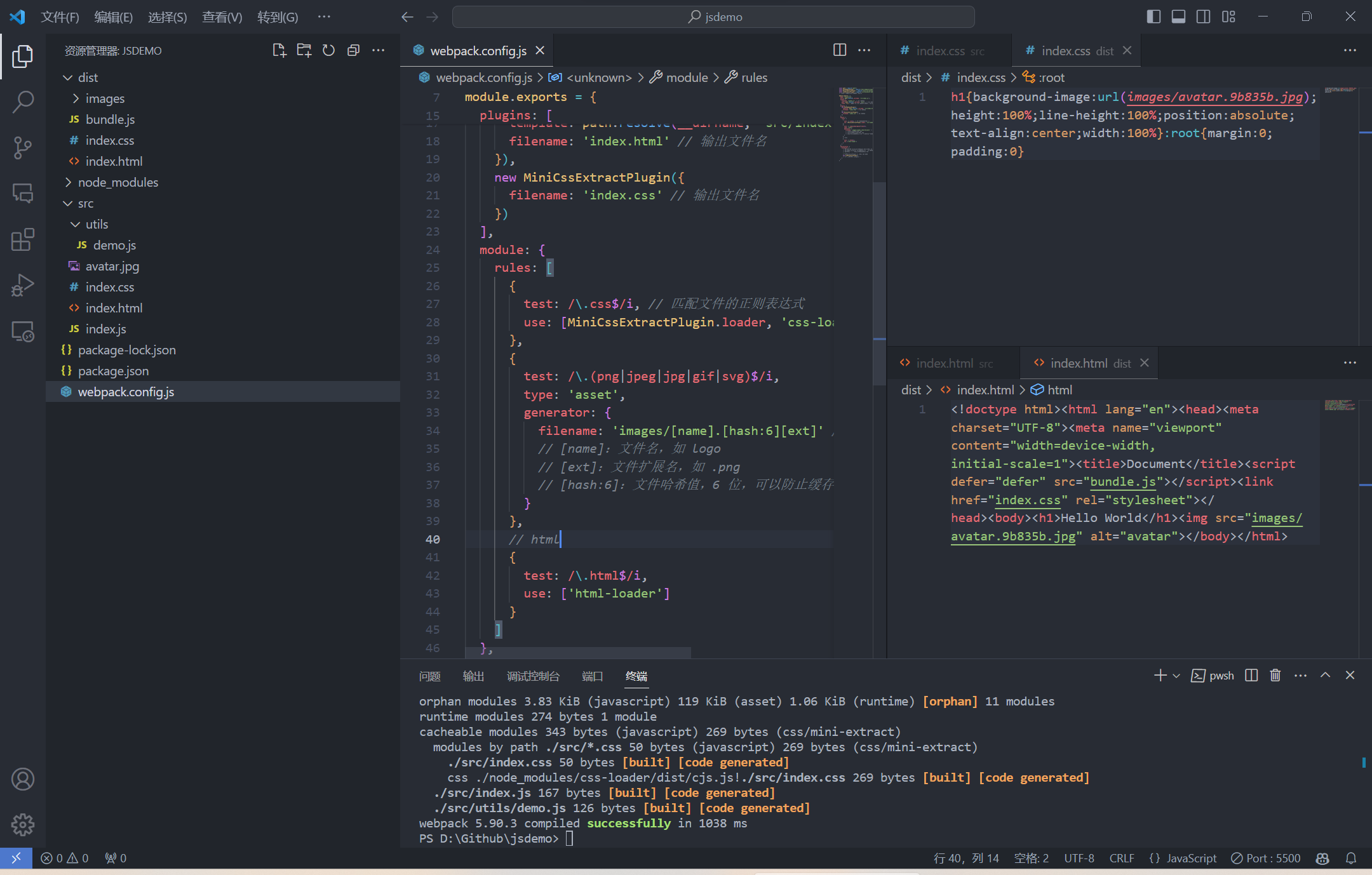
Webpack5 之后, 一些资源文件(如图片、字体等)可以直接使用 asset 模块类型来打包, 不再需要额外的加载器 loader
| 模块类型 | 说明 |
|---|---|
asset/resource |
用于将文件单独打包 |
asset/inline |
用于将文件转换为 base64 编码的 URL |
asset/source |
用于将文件导出为字符串 |
asset |
将大于 8KB 的文件单独打包小于 8KB 的文件转换为 base64 编码的 URL |
asset/inline适用于小图片, 可以减少HTTP请求- 但
asset/inline会增加图片的体积, 所以不适用于大图片 - 打包完成后,
Webpack会自动将图片文件的路径替换为打包后的路径 - 除了上面的
html-webpack-plugin插件外, 还需要安装html-loader加载器来处理HTML文件, 否则HTML文件中的图片路径不会被替换
1 | # 安装加载器 |
1 | // webpack.config.js |
| 打包前 | 打包后 |
|---|---|
 |
 |
开发环境
Webpack 可以通过 webpack-dev-server 来搭建开发环境, 它是一个基于 Node.js 的 Web 服务器, 可以实现热更新、代理等功能
1 | # 安装插件 |
1 | // webpack.config.js |
webpack命令可以用--mode=development/--mode=production来设置模式, 优先级高于配置文件, 从而避免反复修改配置文件
source map
如果代码有错误, 在浏览器中的报错指向的是打包后的文件, 不利于调试; source map 可以将打包后的文件映射回原始文件, 从而方便调试
1 | // webpack.config.js |
注意: 不要在生产环境中使用
source map, 因为它会暴露源码和增加文件体积
环境变量
cross-env 工具
cross-env 是一个跨平台的环境变量设置工具, 可以在 Windows、Linux、macOS 上设置环境变量
1 | # 安装 cross-env |
1 | // package.json |
通过环境变量优化打包配置
1 | // webpack.config.js |
如生产和开发配置差异过大, 用环境变量也很麻烦, 则可以配置两个配置文件, 分别为
webpack.config.js和webpack.config.prod.js, 然后在package.json中设置scripts, 如"build": "webpack --config webpack.config.prod.js", 这样就可以根据不同的命令来执行不同的配置文件
DefinePlugin
webpack 内置的 DefinePlugin 用于在编译时将代码中的某个环境变量替换为指定的值或表达式
如果给定的值是字符串, 需要用 JSON.stringify 来转换, 否则会被当做可执行代码(如变量名、函数名等)
1 | // webpack.config.js |
1 | // index.js |
解析别名 alias
Webpack 可以通过 resolve.alias 来设置模块的别名, 从而简化模块的引入, 并将相对路径转换为绝对路径(更安全)
1 | // webpack.config.js |
Parcel
Parcel 是一个零配置的打包工具, 可以用于打包 JavaScript、CSS、HTML 等文件, 相比 Webpack 等打包工具, Parcel 更加简单易用
1 | # 安装 parcel |
| 命令 | 作用 |
|---|---|
parcel [-p xxx] [entry] |
启动服务, -p 用于指定端口, 默认为 1234 |
parcel watch [entry] |
只监听文件变化并热替换, 不启动服务 |
parcel build [entry] [-d xxx] |
打包文件, -d 用于指定输出目录, 默认为 dist |
entry既可以是HTML文件, 也可以是JavaScript文件Parcel会自动解析HTML、CSS、JavaScript等文件的依赖, 然后打包Parcel同时支持CommonJS、ES6两种模块规范Parcel原生支持TypeScript, 不需要额外的配置
静态资源打包
在 jsPsych 中, 一些图片往往不是直接在 HTML 或 CSS 引用的, 所有可能不会被打包, 可以使用 parcel-reporter-static-files-copy 插件来复制静态资源
1 | # 安装插件 |
还有个办法, 在
HTML里面preload一下图片, 然后JavaScript里获取<link>标签的href属性
Vite
Vite 是一个由 Vue.js 核心团队维护的下一代前端构建工具, 它主要用于快速搭建现代化的前端项目, 并提供了 Vue、React、Preact 等框架的插件
1 | # 创建一个 Vite 项目 (可以选择 React 等模板) |
| 命令 | 描述 |
|---|---|
pnpm dev (vite) |
启动开发服务器 |
pnpm build (vite build) |
构建生产版本 |
pnpm preview (vite preview) |
预览生产版本 |
- 使用
Vite构建的前端项目默认入口是根目录的index.html文件 - 要打包的资源通过相对路径引入即可 (如
<script src="src/main.js"></script>,import app from 'App.jsx'); 其中引入的json文件会被自动解析 /public目录下的静态资源会被直接复制到输出目录, 通过绝对路径引入 (如/favicon.ico)- 样式表除了在
HTML文件中引入, 还可以通过import语句引入, 如import 'App.css' - 不能被直接引用的资源, 除了放在
/public目录下, 还可以通过import 'xxx'的方式引入, 如:import img from 'img.png': 返回路径import str from 'file.txt?raw': 返回字符串import Worker from 'worker.js?worker': 返回Web Worker
环境变量
Vite 会默认将根目录的 .env 文件中的环境变量注入到 import.meta.env 对象中
1 | .env # 所有情况下都会加载 |
- 所有环境变量的类型都会被转换为字符串
- 只有以
VITE_开头的环境变量才能被客户端代码访问 - 可以在
HTML文件中通过%VITE_XXX%的方式引用环墧变量 Vite的mode与NODE_ENV是相对独立的,vite build会自动设置NODE_ENV为production, 但可以通过--mode development来将Vite的mode设置为developmentimport.meta.env.PROD/DEV是由NODE_ENV环境变量决定的; 而import.meta.env.MODE是由Vite的mode决定的
配置文件
1 | // vite.config.js |
| 配置选项 | 描述 | 默认值 |
|---|---|---|
root |
项目根目录(index.html 位置) |
process.cwd() |
mode |
Vite 模式 |
取决于命令 |
plugins |
插件 | undefined |
publicDir |
静态资源目录 | 'public' |
envDir |
环境变量目录 | root |
server.port命令 --port xxx |
服务器端口 | 5173 |
server.open命令 --open |
启动时是否自动打开浏览器 | false |
server.cors |
是否启用跨域 (允许所有) | false |
build.target |
构建目标, esnext, es2020, chrome80, safari14 等 |
'modules' |
build.outDir命令 --outDir xxx |
输出目录 | 'dist' |
build.minify |
压缩和混淆代码, false, 'terser', 'esbuild' |
'esbuild' |
分块策略
可以通过 build.rollupOptions.output.manualChunks 来手动配置分块策略, 见rollup 文档
1 | // vite.config.js |
版本控制工具
Git
Git 是一个分布式版本控制系统, 可以用于管理代码, 跟踪文件的变化, 协作开发等; 而世界上最大的代码托管平台 GitHub 就是基于 Git 的; 可以在官网下载 Git 客户端, 并在 Git Bash 中使用命令行操作
| 命令 | 作用 |
|---|---|
git -v |
验证是否安装并查看版本 |
git --help |
查看帮助 |
git reflog --oneline |
查看所有操作日志 |
大多数命令都可以在
VScode或GitHub Desktop中图形化地执行
配置用户信息
使用 Git 前, 需要配置用户信息, 包括用户名和邮箱, 这样提交代码时才能知道是谁提交的
1 | # 设置用户名 |
注:
Git Bash中清屏命令是clear, 而不是cls
创建仓库
仓库是用于存放代码的地方, 可以是本地的, 也可以是远程的, 实质上是一个隐藏的 .git 目录, 里面存放着 Git 的版本库
1 | # 在当前目录下创建仓库 |
仓库的三个区域
- 工作区: 实际操作的文件夹
- 暂存区: 用于存放暂时的改动, 位于
.git/index文件中 - 版本库: 存放历史记录, 位于
.git/objects文件夹中
文件状态
- 未跟踪
U: 未被Git跟踪(通常是新文件), 不在版本库中; 暂存后变为A - 新添加
A: 已被Git跟踪(首次暂存), 未提交到版本库 - 已修改
M: 已被Git跟踪, 且已被修改(不一定被暂存), 修改未提交到版本库 - 未修改
Git跟踪, 且未被修改, 已提交到版本库 - 已删除
D: 已被Git跟踪, 但已被删除, 删除操作未提交到版本库
文件修改和提交
在 Git 中, 文件的添加、修改、删除等操作都需要经过 add 命令, 将文件的改动添加到暂存区
| 命令 | 作用 |
|---|---|
git add xxx |
将 xxx 文件添加到暂存区 |
git add . |
将所有改动过的文件添加到暂存区 |
git rm --cached xxx |
从暂存区移除文件 |
git rm xxx |
从工作区移除文件, 并将删除操作添加到暂存区 |
git status -s |
查看工作区和暂存区的状态-s 表示简短输出, 结果形如 MM xxx第一位表示暂存区, 第二位表示工作区 |
git ls-files |
查看暂存区的文件 |
git restore xxx |
将暂存区的文件覆盖到工作区 |
git commit -m "some message" |
将暂存区的文件提交到版本库-m 表示附加的提交信息如果不加 -m 参数, 会打开 Vim 编辑器 |
在
Git中务必使用相对路径(相对于命令行所在的目录)
版本回退
Git 的每次提交都会生成一个 commit 及其对应的 SHA 值(作为版本号), 可以通过 SHA 值来回退到指定的 commit
| 命令 | 作用 |
|---|---|
git log --oneline |
查看提交历史, 只显示 SHA 值和提交信息 |
git reset --hard xxx |
回退到指定的 commit, xxx 为 SHA 值 |
git reset --soft xxx |
回退到指定的 commit, 但保留暂存区和工作区的改动 |
git reset --mixed xxxgit reset xxx |
回退到指定的 commit, 但保留工作区的改动 |
git reset --hard HEAD |
放弃工作区和暂存区的所有改动 |
忽略文件
.gitignore 文件用于忽略不需要上传到 git 仓库的文件, 如 node_modules 目录、package-lock.json 文件等
| 内容 | 作用 |
|---|---|
xxx |
忽略所有名为 xxx 的文件和目录 |
/xxx |
忽略当前目录下的名为 xxx 的文件和目录 |
/xxx/ |
忽略当前目录下的名为 xxx 的目录 |
*.xxx |
忽略所有扩展名为 xxx 的文件可以把 * 理解为除 / 之外的任意字符 |
/xxx/*.xxx |
忽略当前目录下的 xxx 目录中的所有扩展名为 xxx 的文件不会忽略 /xxx/xxx/xxx.xxx 等子目录内的文件 |
/xxx/**/*.xxx |
忽略当前目录下的 xxx 目录中的所有扩展名为 xxx 的文件会忽略 /xxx/xxx/xxx.xxx 等子目录内的文件 |
/xxx/**/?.xxx |
忽略当前目录下的 xxx 目录中的所有 x.xxx 文件如 1.xxx、a.xxx, 不会忽略 10.xxx、aa.xxx |
!xxx |
不忽略名为 xxx 的文件或目录可以用于忽略整个目录, 但不忽略其中的某个文件 |
1 | # 忽略 node_modules 目录 |
注意:
.gitignore文件只对未被Git跟踪的文件有效, 如果文件在之前的提交中已经被跟踪, 则需要先将其暂时移除
分支管理
Git 的分支管理是其最大的特色之一, 可以通过分支来实现多人协作、版本控制、功能开发等; 默认的分支是 master 或 main
| 命令 | 作用 |
|---|---|
git branch |
查看所有分支 |
git branch xxx |
创建分支 xxx |
git checkout xxx |
切换到分支 xxx暂存区和工作区的改动会转移到新分支 原分支变回最近一次提交的样子 没有更改时, 切换分支不影响两个分支的内容 |
git checkout -b xxx |
创建并切换到分支 xxx |
git merge xxx |
将分支 xxx 合并到当前分支 |
git branch -d xxx |
删除分支 xxx |
git branch -D xxx |
强制删除分支 xxx |
git branch -m old new |
重命名分支 old 为 new |
- 如果分支迁出后, 原分支没有新提交, 则将迁出的分支合并到原分支时, 迁出分支的所有提交会拼接到原分支, 并将
HEAD指向合入分支的最新提交 - 如果分支迁出后, 原分支有新提交, 则将迁出的分支合并到原分支时,
Git会尝试自动合并, 为原分支生成一个最新提交(将原分支和合入分支的最新提交合并), 如果这个最新提交里有冲突, 则需要手动解决冲突; 而合入分支的其他提交会拼接到原分支 - 冲突会在对同一文件的同一部分进行不同的修改时产生, 尝试合并后, 原分支和合入分支的内容已合并, 但冲突部分暂时全部保留并被特殊标记,
VScode会引导我们解决冲突, 解决冲突后, 需要手动提交
远程仓库
Git 可以通过 SSH 或 HTTPS 协议来与远程仓库通信, SSH 协议更安全, 但需要配置公钥和私钥
除了在自己的服务器上搭建 Git 仓库外, 还可以使用 GitHub、GitLab、Gitee 等代码托管网站上的 Git 仓库
配置公钥和私钥
1 | # 生成 SSH 密钥 |
公钥和私钥简单来说是: 公钥加密的信息只能用私钥解密, 私钥加密的信息只能用公钥解密; 公钥用于交给要通信的对方, 私钥只有自己知道; 发信息时用对方的公钥加密, 收到信息时用自己的私钥解密
相关命令
| 命令 | 作用 |
|---|---|
git remote add 远程仓库别名 远程仓库地址 |
关联远程仓库, 别名一般取 origin |
git push -u 远程仓库别名 分支名 |
推送到远程仓库 若本地和远程分支名不一致, 写 本地分支名:远程分支名 |
git pull 远程仓库别名 分支名 |
拉取远程仓库 相当于 git fetch 和 git merge 的合并操作没有冲突时, 会自动合并到当前本地分支 |
git clone 远程仓库地址 |
克隆远程仓库到当前目录 克隆后会自动关联远程仓库, 别名为 origin如果要克隆到指定目录, 可以加上 ./xxx |
git remote -v |
查看远程仓库 |
git remote show 远程仓库别名 |
查看远程仓库详细信息 |
git branch -r |
查看远程分支 |
git branch -a |
查看所有分支 |
git push origin xxx |
创建远程分支(在远程仓库没有 xxx 分支时) |
git push origin --delete xxx |
删除远程分支 |
git remote rm 远程仓库别名 |
删除远程仓库关联 不会影响本地和远程仓库的内容 |
git remote rename old new |
重命名远程仓库别名 |
VScode中的同步修改其实是pull和push的合并操作
标签管理
Git 可以给 commit 打标签, 用于标记重要的提交, 如版本号、发布日期等
| 命令 | 作用 |
|---|---|
git tag |
查看所有标签 |
git show xxx |
查看标签 xxx 的详细信息 |
git tag xxx |
给当前 commit 打标签 xxx |
git tag -a xxx -m "some message" |
给当前 commit 打标签 xxx, 并附加信息 |
git tag -d xxx |
删除标签 xxx |
git push origin xxx |
推送标签 xxx 到远程仓库 |
git push origin --tags |
推送所有标签到远程仓库 |
提交规范
Git 提交规范是指在提交代码时, 通过规范化的提交信息来标明提交的类型、影响范围、简要描述等, 以便更好地追踪和管理代码
通常使用 Conventional Commits 规范: type(scope): description, 其中 type 为提交类型, scope 为影响范围, description 为简要描述; scope 可以省略
| 类型 | 描述 |
|---|---|
feat |
新功能, 如 feat: add login page |
fix |
修复问题, 如 fix: fix login bug |
docs |
文档修改, 如 docs: update README |
style |
代码格式修改, 不影响代码含义, 如 style: format code |
refactor |
代码重构, 如 refactor: refactor login page |
perf |
性能优化, 如 perf: improve login speed |
test |
测试用例, 如 test: add login test |
chore |
构建过程或辅助工具的变动, 如 chore: update dependencies |
build |
构建工具相关的修改, 如 build: update webpack config |
ci |
CI 配置文件和脚本的修改, 如 ci: update GitHub Actions |
revert |
撤销上一次的提交, 如 revert: revert login page |
如果要标注破坏性变更, 可以在
type后加上!, 如feat!: add login page
如果还需要更详细的信息, 可以在提交信息中添加 body 和 footer
1 | feat: add login page |
前端框架
React
Solid
后端/全栈框架
Express
Express 是一个基于 Node.js 平台的 Web 应用开发框架, 可以用于构建 Web 服务器、API 服务器等
1 | # 创建项目 |
1 | // 导入 express 模块 |
res.send()与res.end()类似, 但res.send()可以自动设置Content-Type, 并且可以发送Buffer、String、Object、Array等
路由
Express 中的路由是指 URL 和处理函数之间的映射关系, 用于处理客户端的请求
1 | app.请求方式('路径', (req, res) => xxx) |
1 | // get 请求 |
路由参数
路由参数是指路径中的占位符, 用于获取客户端传递的数据; 可通过 req.params 获取路由参数对象
1 | app.get('/user/:id', (req, res) => { |
路由模块化
为便于维护和开发, 可以将路由规则封装到单独的模块中, 然后导入到主模块中
1 | // routes/user.js |
1 | // app.js |
请求对象
Express 完全兼容 Node.js 的 http 模块的属性和方法, 但也提供了一些更高级的属性和方法, 还可以用第三方中间件来实现更多功能
| 属性或方法 | 作用 |
|---|---|
req.method |
(原生)获取请求方式 |
req.url |
(原生)获取请求 URL |
req.httpVersion |
(原生)获取 HTTP 版本 |
req.headers |
(原生)获取请求头对象 |
req.path |
(原生) 获取请求路径 |
req.query |
获取查询字符串对象 |
req.ip |
获取客户端的 IP 地址 |
req.get('xxx') |
获取请求头中的 xxx 属性 |
req.params |
获取路由参数对象 |
req.body |
获取请求体对象 |
解析请求体
Express 默认不解析 POST 请求的请求体, 需要使用中间件
1 | // 解析 application/x-www-form-urlencoded 格式的请求体 |
解析文件
formidable 是一个用于解析 form 表单的包, 可以用于解析 form 表单的请求体, 包括图片、文件等
1 | # 安装 formidable |
1 | // 导入 formidable 模块 |
注意: 上传的文件不会自动删除, 需要手动进行管理
options
| 属性 | 作用 | 默认值 |
|---|---|---|
encoding |
设置编码 | utf-8 |
uploadDir |
设置上传文件的保存路径 | os.tmpdir() |
keepExtensions |
是否保留文件扩展名 | false |
allowEmptyFiles |
是否允许上传空文件 | false |
minFileSize |
设置上传文件的最小大小(字节) | 1 |
maxFiles |
设置上传文件的最大数量 | Infinity |
maxFileSize |
设置上传文件的最大大小(字节) | 200 * 1024 * 1024 |
maxTotalFileSize |
设置上传文件的最大总大小(字节) | options.maxFileSize |
maxFields |
设置非文件字段的最大数量 | 1000 |
maxFieldsSize |
设置非文件字段的最大大小(字节) | 20 * 1024 * 1024 |
hashAlgorithm |
设置文件的哈希算法 | false |
fileWriteStreamHandler |
设置文件写入流的处理函数 | null |
filename |
newFilename 的处理函数形如 `(field, file) => ‘xxx’ |
undefined |
filter |
文件过滤函数 | (field, file) => true |
files 对象
files 对象是一个键值对, 键是表单中的文件字段名, 值是一个对象, 包含了文件的信息
| 属性 | 含义 |
|---|---|
size |
文件大小(字节) |
filepath |
文件的保存路径 |
originalFilename |
文件的原始名 |
newFilename |
经过 filename 的回调函数处理后的文件名 |
mimetype |
文件的 MIME 类型(Content-Type) |
mtime |
文件的最后修改时间, 是一个 Date 对象 |
hashAlgorithm |
文件的哈希算法 |
传入的文件数据并不会保存到
files对象中, 而是保存到uploadDir目录下, 并将其路径保存到files对象中
响应对象
| 属性或方法 | 作用 |
|---|---|
res.statusCode |
(原生)设置状态码, 默认为 200 |
res.statusMessage |
(原生)设置状态消息, 默认与状态码对应 |
res.setHeader('key', 'value') |
(原生)设置响应头 |
res.write(xxx) |
(原生)向响应体中写入数据 |
res.end([xxx]) |
(原生)结束响应, 向客户端发送数据 |
res.status(404) |
设置状态码 |
res.set('key', 'value') |
设置响应头 |
res.send(xxx) |
向客户端发送数据, 自动设置 Content-Type可以发送 Buffer、String、Object、Array 等 |
res.json(xxx) |
向客户端发送 JSON 数据 |
res.download('path') |
向客户端发送下载 |
res.redirect('path') |
向客户端发送重定向 |
res.sendFile('path') |
向客户端发送文件 |
- 后四种方法都会自动设置
Content-Type res.download()与res.sendFile()的区别在于, 前者会自动设置Content-Disposition头, 用于告诉浏览器以下载的方式打开文件- 支持链式调用, 如
res.status(200).set('x-powered-by', 'Express').send('Hello World!')
中间件
Express 中的中间件是指一个可以访问请求和响应对象的函数, 用于封装和处理请求和响应的逻辑
- 中间件分为全局中间件和路由中间件:
全局中间件: 任何传入请求都会先经过这个中间件
路由中间件: 只有传入请求的路径匹配时, 才会经过这个中间件 - 注意: 书写顺序很重要, 全局中间件要放在所有路由之前
- 如果全局中间件在某个路由中间件之后, 那匹配这个路由的请求就不会经过全局中间件
1 | // 全局中间件 |
静态资源
Express 内置了一个静态资源中间件 express.static, 用于向客户端发送静态资源文件
express.static会自动设置Content-Type、Cache-Control等响应头express.static会自动根据请求路径去指定目录下查找文件, 如果找到了就发送, 找不到就继续执行后续的回调函数- 但如果传入请求的路径是一个目录(包括
/), 则会自动发送目录下的index.html文件 - 路由规则一般用于处理动态资源, 而静态资源中间件用于处理静态资源
1 | // 将 public 目录下的文件作为静态资源 |
防盗链
Express 可以通过中间件来实现防盗链, 即只允许指定的域名访问资源
- 每一个发出的请求都会携带
Referer头, 用于告诉服务器请求的来源 - 服务器可以根据
Referer头来判断请求的来源, 从而决定是否允许访问资源 - 下面代码的功能与
Access-Control-Allow-Origin类似, 但是Access-Control-Allow-Origin的拒绝请求的判断是在浏览器中进行的, 而下面代码的拒绝请求的判断是在服务器中进行的
Cloudflare可以通过设置Hotlink Protection来实现防盗链, 无需在代码中实现
1 | app.use((req, res, next) => { |
EJS
模板引擎是一种将模板和数据结合起来生成 HTML 的工具, Express 可以通过模板引擎来渲染 HTML 文件; 常用的模板引擎有 EJS、Pug、Handlebars 等
随着
React、Vue等前端框架的兴起, 前后端分离的开发模式越来越流行, 模板引擎的使用也越来越少
1 | # 安装 EJS |
1 | // 设置模板引擎 |
1 | <!-- views/index.ejs --> |
语法
EJS 是一种简单的模板引擎, 可以通过 <% %> 来插入 JavaScript 代码, 通过 <%= %> 来插入 JavaScript 表达式的值
注意: HTML 中应当使用绝对路径(如 /xxx)来引用静态资源(指向 public/xxx)
1 | // 引入 ejs 模块 |
1 | <!-- views/index.ejs --> |
列表渲染
1 | <!-- views/index.ejs --> |
条件渲染
1 | <!-- views/index.ejs --> |
包含模板
1 | <!-- views/index.ejs --> |
Hono
Hono 是一个跨平台的 Web 框架, 适用于 Cloudflare Workers, Node.js, Deno, Bun, Vercel 等环境; Hono 的使用方法与 Express 类似
1 | # 创建一个 hono 项目 |
1 | // 引入 hono |
CORS
Hono 提供了一个 cors 中间件, 可以用于设置 CORS 头
1 | import { cors } from 'hono/cors' |
options.origin默认为*, 详见官方文档
App
| 方法 | 作用 |
|---|---|
new Hono() |
创建一个 Hono 实例 |
new Hono().basePath('/api') |
设置基础路径, 路由的 path 会自动添加在基础路径之后 |
app.get(path, handler) |
添加一个 GET 路由 |
app.post(path, handler) |
添加一个 POST 路由 |
app.put(path, handler) |
添加一个 PUT 路由 |
app.delete(path, handler) |
添加一个 DELETE 路由 |
app.all(path, handler) |
添加一个通用路由 |
app.use([path,] middleware) |
添加一个中间件 |
- 路径中可以使用
*来匹配任意字符串 - 路径中可以使用
:key来匹配任意字符串, 通过c.req.param('key')来获取参数 :key可以用正则表达式来匹配, 如:data{[0-9]+},:title{[a-zA-Z]+}- 路由顺序是按照添加的顺序来的, 先添加的先匹配
Context
| 方法 | 作用 |
|---|---|
c.env |
环境变量 (wrangler.toml 中) |
c.text('text') |
创建文本响应 |
c.json({ data }) |
创建 JSON 响应 |
c.html('<App />' |
创建 HTML 响应, 支持 JSX |
c.notFound() |
创建 404 响应 |
c.redirect('url'[, status]) |
创建重定向响应, 默认状态码为 302 |
c.req |
HonoRequest 对象 |
c.res |
一般在中间件中使用, 如 c.res.headers.append('key', 'value') |
c.set('key', 'value') |
一般在中间件中使用, 设置变量 |
c.get('key') |
一般在路由中使用, 获取变量 |
不是必须用
c.text()等方法, 也可以自己创建Response对象
Request
c.req 是一个 HonoRequest 对象, 用于获取请求的一些信息
| 方法 | 作用 |
|---|---|
c.req.params('key') |
获取路由中 :key 的值 |
c.req.query('key') |
获取查询参数 |
c.req.queries('key') |
获取查询参数数组, 适用于有多个相同参数的情况 |
c.req.header('key') |
获取请求头 |
c.req.parseBody() |
解析请求体, 返回 Promise |
c.req.json() |
解析请求体为 JSON 格式, 返回 Promise |
c.req.text() |
解析请求体为 text 格式, 返回 Promise |
c.req.arrayBuffer() |
解析请求体为 ArrayBuffer 格式, 返回 Promise |
c.req.path |
请求的路径 |
c.req.url |
请求的完整 URL |
c.req.method |
请求的方法 |
c.req.raw |
请求的原始 Request 对象 |
c.req.query会自动进行URL解码, 无需额外处理
Next.js
SolidStart
🚧 Astro
数据库
MongoDB
MongoDB 是一个基于分布式文件存储的数据库, 由 C++ 语言编写, 旨在为 Web 应用提供可扩展的高性能数据存储解决方案
- 服务器
Server: 一个MongoDB实例, 可以包含多个数据库 - 数据库
Database: 一个数据仓库, 可以包含多个集合 - 集合
Collection: 类似于JavaScript中的数组, 是一个文档的集合, 可以包含多个文档 - 文档
Document: 类似于JavaScript中的对象, 是一个键值对的集合, 可以包含多个键值对 - 一般情况下, 一个项目对应一个数据库
- 一个集合会存储同一类型的数据, 如用户数据、商品数据等
安装 (Windows)
- 下载
MongoDB安装包 - 安装
MongoDB, 并将bin目录添加到环境变量 - 在
xxx目录下创建data/db目录, 用于存放数据 - 在
xxx目录下创建logs目录, 用于存放日志 - 在
xxx目录下创建mongod.cfg文件, 用于配置MongoDB服务 - 在
xxx目录下打开命令行, 输入mongod --config mongod.cfg启动MongoDB服务
- 如果直接运行
mongod, 会按默认配置启动MongoDB服务, 数据会存放在C:\data\db目录下、日志会直接输出到控制台 - 注意: 通过上面的方式启动
MongoDB服务后, 不可以选中命令行窗口内的日志内容, 否则会导致服务暂停 - 可以用绝对路径指定配置文件, 如
mongod --config D:\Database\mongod.cfg
基础配置文件
1 | systemLog: # 系统日志 |
命令行操作
- 下面的命令需要下载
mongosh客户端来运行 mongosh可以直接运行JavaScript代码, 如console.dir(db.demo)- 要断开连接, 可以输入
exit或quit, 或直接关闭mongosh窗口 - 推荐使用
MongoDB Compass图形化客户端来操作数据库(内部集成了mongosh, 界面设计也很好看)
数据库操作
| 命令 | 作用 |
|---|---|
show dbs |
显示所有数据库 |
use xxx |
切换到 xxx 数据库 |
db |
显示当前数据库 |
db.dropDatabase() |
删除当前数据库 |
集合操作
| 命令 | 作用 |
|---|---|
show collections |
显示当前数据库的所有集合 |
db.createCollection('xxx') |
创建一个名为 xxx 的集合 |
db.xxx.drop() |
删除 xxx 集合 |
db.xxx.renameCollection('abc') |
重命名 xxx 集合为 abc |
文档操作
| 命令 | 作用 |
|---|---|
db.xxx.find([{ filter }]) |
查询 xxx 集合的文档, 可以传入查询条件查询条件如 { name: 'xiaoyezi' }会返回所有 name 为 xiaoyezi 的文档 |
db.xxx.insertOne({ data }) |
向 xxx 集合插入文档 |
db.xxx.updateOne({ filter }, { data }) |
更新 xxx 集合的文档不保留除 _id 以外的其他字段 |
db.xxx.updateOne({ filter }, { $set: { data } }) |
更新 xxx 集合的文档保留除修改字段以外的其他字段 |
db.xxx.deleteOne({ filter }) |
删除 xxx 集合的文档 |
每个文档都有一个
_id属性, 用于唯一标识文档, 可以手动指定_id, 也可以不指定,MongoDB会自动为其生成一个唯一的ObjectId
增删改查
MongoDB 官方提供了一个 Node.js 驱动, 可以用于连接 MongoDB 数据库、操作数据库、定义模型等
参见官方文档
1 | # 安装 mongodb |
1 | // 导入 mongodb 模块 |
| 方法 | 作用 |
|---|---|
coll.findOne({ filter }) |
查询集合的一个文档 |
coll.insertOne({ data }) |
向集合插入一个文档 |
coll.insertMany([{ data }, { data }, ...]) |
向集合插入多个文档 |
coll.updateOne({ filter }, { $set: { data } }) |
更新集合的一个文档 |
coll.updateMany({ filter }, { $set: { data } }) |
更新集合的多个文档 |
coll.updateOne({filter}, { $push: { data }}) |
向集合的一个文档中的数组字段中添加一个元素 |
coll.updateMany({filter}, { $push: { data }}) |
向集合的多个文档中的数组字段中添加一个元素 |
coll.replaceOne({ filter }, { data }) |
替换集合的一个文档 |
coll.deleteOne({ filter }) |
删除集合的一个文档 |
coll.deleteMany({ filter }) |
删除集合的多个文档 |
coll.countDocuments({ filter }) |
统计集合的文档数量 |
- 以上的方法都是异步的, 返回
Promise - 向数组添加元素示例:
({ name: 'leaf' }, { $push: { hobbies: 'coding' }}), 如果hobbies不存在, 则会自动创建一个数组字段
批量操作
1 | await coll.bulkWrite([ |
过滤器
上面的 filter 用于筛选文档, 除了指定某字段等于某值外, 还可以指定某字段大于、小于、包含等于某值, 以及使用逻辑与、或、非等
| 筛选器和作用 | 示例 |
|---|---|
{ key: value }字段等于某值 |
{ name: 'xiaoyezi' } |
{ key: { $gt: value } }字段大于某值 |
{ age: { $gt: 18 } } |
{ key: { $lt: value } }字段小于某值 |
{ age: { $lt: 18 } } |
{ key: { $gte: value } }字段大于等于某值 |
{ age: { $gte: 18 } } |
{ key: { $lte: value } }字段小于等于某值 |
{ age: { $lte: 18 } } |
{ key: { $in: [value1, value2] } }字段包含某值 |
{ name: { $in: ['xiaoyezi', 'leaf'] } } |
{ key: { $nin: [value1, value2] } }字段不包含某值 |
{ name: { $nin: ['xiaoyezi', 'leaf'] } } |
{ key: { $exists: true } }字段存在 |
{ name: { $exists: true } } |
{ key: { $exists: false } }字段不存在 |
{ name: { $exists: false } } |
{ key: { $regex: /pattern/ } }{ key: new RegExp('pattern') }{ key: /pattern/ }字段匹配正则表达式 |
{ name: { $regex: /xiaoyezi/ } }{ name: new RegExp('xiaoyezi') }{ name: /xiaoyezi/ } |
{ key: { $or: [{ filter1 }, { filter2 }] } }逻辑或 |
{ $or: [{ name: 'xiaoyezi' }, { age: 18 }] } |
{ key: { $and: [{ filter1 }, { filter2 }] }}逻辑与 |
{ $and: [{ name: 'xiaoyezi' }, { age: 18 }]} |
{ key: { $not: { filter } } }逻辑非 |
{ name: { $not: { name: 'xiaoyezi' } } } |
高级查询
| 方法 | 作用 |
|---|---|
coll.find({ filter }) |
查询集合的文档, 返回一个 Cursor 对象, 而不是文档本身 |
for await (const doc of cursor) { } |
异步遍历 Cursor 对象 |
cursor.toArray() |
将 Cursor 对象转换为数组, Promise<Document[]> |
cursor.stream() |
查询集合的文档, 返回一个 Readable 流 |
cursor.close() |
关闭 Cursor 对象, 释放客户端和服务端资源 |
cursor.sort({ key: 1 }) |
按 key 升序排序, -1 降序排序 |
cursor.limit(10) |
限制返回的文档数量 |
cursor.skip(10) |
跳过前 10 个文档 |
cursor.project({ key: 1, _id: 0 }) |
只返回值为 1 的字段, 除 _id 外都默认为 0 |
coll.findOne({ filter }, { projection }) |
查询集合的一个文档, projection 同 project |
coll.distinct('key'[, { filter }]) |
查询集合中某字段的所有不同值, 返回一个 Cursor 对象 |
上面的读取方法可以链式调用; 当文档量较大时, 警惕
toArray方法带来的性能问题
1 | // 按照年龄降序排序, 只返回年龄第 4-6 名的名字 |
1 | // 也可以直接写在一个方法中 |
Lowdb
lowdb 是一个轻量级的 JSON 数据库, 可以用于存储数据, 支持链式调用和异步操作
1 | # 安装 lowdb |
1 | // 导入 lowdb 模块 |
SQL
SQL 是一种用于管理关系数据库的标准化语言, 用于查询、更新、删除和管理数据库中的数据
- 不同的数据库管理系统(
DBMS)有不同的SQL方言, 如MySQL、PostgreSQL、SQLite、Oracle等, 但基本语法是相同的 SQL语言不区分大小写, 但是建议关键字大写, 表名和字段名小写, 以提高可读性SQL的数据库层级结构: 数据库(Database) -> 表(Table) -> 记录(Record)/ 行(Row) -> 字段(Field)SQL语句以分号结尾, 可以在一行或多行书写, 分号可以省略SQL语句可以使用注释, 单行注释以--开头, 多行注释以/*开头和*/结尾
创建和删除表
1 | -- 创建表 |
表的主键
PRIMARY KEY用于唯一标识表中的每一行 (相当于MongoDB的_id), 由表的一个或多个字段组成; 主键字段的值不能重复, 且不能为空; 主键字段可以是自增的, 也可以是手动指定的
数据类型
| 类型 | 说明 |
|---|---|
int |
整数类型 |
numeric(p, s) |
定点数, p 为总位数, s 为小数位数 |
float(p) |
浮点数, p 为精度 |
char(n) |
定长字符串, n 为长度 |
varchar(n) |
变长字符串, n 为最大长度 |
text |
文本类型, 适合存储大量文本 |
date |
日期类型, 格式为 YYYY-MM-DD |
插入数据
1 | INSERT INTO table_name (uname, age) VALUES ('xiaoyezi', 18) |
null进行任意比较和运算的结果都是null, 可以使用IS NULL和IS NOT NULL来判断, 不能用=和!=
查询数据
1 | SELECT * FROM table_name -- 查询所有字段 |
字段别名如果有空格或特殊字符, 需要用引号包裹
更新数据
1 | UPDATE table_name SET age = 19 WHERE uname = 'xiaoyezi' -- 更新符合条件的数据 |
删除数据
1 | DELETE FROM table_name -- 删除所有数据(但不删除表) |
连接查询
1 | -- 内连接查询 |
集合运算
1 | -- 交集 |
分组查询
1 | -- 统计函数 |
子查询
1 | -- 查询年龄最大的人的姓名 |
自动化/测试工具
Puppeteer
Puppeteer 是一个 Node.js 库, 提供了一组用于操纵 Chrome 或 Chromium 的 API, 可以用于爬取网页数据、生成网页截图、生成 PDF 等; 官方文档写地很详细和易懂, 要用什么去查即可
1 | # 安装 puppeteer |
配置文件
puppeteer 可以用两种方法来进行设置:
- 创建一个设置文件, 如
puppeteer.config.js - 通过环境变量来设置
HTTP_PROXY、HTTPS_PROXY、NO_PROXY只能通过环境变量来设置- 如果设置项会影响
puppeteer的安装, 则修改后需要删除和重新安装puppeteer - 设置项详见官方文档
1 | // puppeteer.config.js |
浏览器对象
| 方法 | 作用 |
|---|---|
puppeteer.launch([settings]) |
打开浏览器, 返回一个 Browser 对象 |
puppeteerCore.launch({ executablePath, ... }) |
打开浏览器, 返回一个 Browser 对象需要传入一个可执行文件路径 在 chrome/edge://version 中可查看 |
browser.newPage() |
打开一个新的页面, 返回一个 Page 对象 |
browser.close() |
关闭浏览器 |
浏览器设置
puppeteer.launch 方法可以传入一个配置对象, 用于设置浏览器的一些参数, 如路径、视口、用户代理等
| 属性 | 作用 |
|---|---|
executablePath |
浏览器的可执行文件路径 仅 puppeteer-core 需要设置 |
slowMo |
减慢操作的速度, 单位为 ms, 默认为 0 |
defaultViewport |
视口的默认大小, 如 {width:1920,height:1080}, 默认为 800x600 |
args |
浏览器的启动参数数组, 如 ['--no-sandbox'] |
1 | const browser = await puppeteer.launch({ |
网页对象
puppeteer 的 page 对象是一个 Browser 对象的实例, 可以用于访问网页、操作网页、获取网页信息等
| 方法 | 作用 |
|---|---|
page.goto(url[, { waitUntil, timeout, referer }]) |
访问一个网页 |
page.evaluate(() => {}) |
在网页中执行 JavaScript 代码可以使用 document、window 等对象 |
page.waitForSelector(selector) |
等待一个元素出现在网页中 |
page.waitForNavigation([{ waitUntil, timeout }]) |
等待页面跳转 |
page.waitForNetworkIdle({ idleTime(空闲时间, 默认500ms),concurrency(判定空闲的最大并发请求数, 默认0),timeout }) |
等待网络空闲 |
page.type(selector, text) |
在一个输入框中输入文本 |
page.click(selector) |
点击一个元素 |
page.hover(selector) |
悬停在一个元素上 |
page.focus(selector) |
聚焦一个元素 |
page.close() |
关闭网页 |
- 基本所有方法都是异步的, 返回
Promise对象, 可以使用await(如果不确定可以加个await看编辑器有没有提示) waitUntil可以设置为load: 页面的load事件触发时, 默认值domcontentloaded: 页面的DOMContentLoaded事件触发时networkidle0: 网络空闲时networkidle2: 网络空闲 2 秒后timeout默认为30000, 单位为ms, 可以设置为0来禁用超时goto中的referer会覆盖setExtraHTTPHeaders中的Referer
1 | // 导入 puppeteer |
进程退出时,
puppeteer会自动关闭浏览器, 如果操作结束后会立即退出, 无需手动关闭浏览器; 并且, 如果browser是在try语句中创建的, 那在catch和finally语句中无法访问browser对象(因为已被垃圾回收机制回收)
截图
page.screenshot(settings) 方法可以用于截取网页的截图, 可以设置截图的路径、质量、类型等
| 属性 | 作用 | 默认值 |
|---|---|---|
fullPage |
是否截取整个网页 | false |
path |
截图的保存路径 | undefined |
quality |
截图的质量, 0-100由于 png 是无损压缩, 所以该属性对其无效 |
undefined |
type |
截图的类型, jpeg、png、webp |
png |
page.pdf(settings) 方法可以用于生成网页的 PDF 文件, 可以设置 PDF 的路径、格式、尺寸等
| 属性 | 作用 | 默认值 |
|---|---|---|
displayHeaderFooter |
是否显示页眉页脚 | false |
format |
PDF 的格式, A4、Legal 等 |
letter |
height |
纸张的高度, 数字或字符串 | undefined |
width |
纸张的宽度, 数字或字符串 | undefined |
margin |
纸张的边距, 对象, 属性为数字或字符串{top:'10mm',right:'10mm',bottom:'10mm',left: '10mm'} |
undefined |
outline |
是否生成大纲 | false |
pageRanges |
生成 PDF 的页码范围 |
''(全部) |
path |
PDF 的保存路径 |
undefined |
scale |
PDF 的缩放比例, 0.1-2 |
1 |
页面设置
page 对象的 setXXX 方法可以用于设置页面的一些属性, 如 userAgent、viewport、cookie 等
| 方法 | 作用 |
|---|---|
page.setCookie(cookieObjA, cookieObjB, ...) |
设置页面的 cookie |
page.setExtraHTTPHeaders({ key: value }) |
设置页面的 HTTP 头 |
page.setUserAgent({ userAgent: 'xxx' }) |
设置页面的 userAgent |
page.setViewport({ width, height, ... }) |
设置页面的视口 |
page.setJavaScriptEnabled(true) |
设置页面的 JavaScript 是否启用 |
page.setGeolocation({ latitude, longitude }) |
设置页面的地理位置 |
setUserAgent可以用来模拟不同的设备和浏览器, 默认的userAgent为HeadlessChrome, 可以设置为Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36来模拟Chrome浏览器(避免被识别为爬虫)
Cookie
| 属性 | 作用 |
|---|---|
name |
cookie 的名字 |
value |
cookie 的值 |
url |
cookie 的域名 |
domain |
cookie 的域名 |
path |
cookie 的路径 |
expires |
cookie 的过期时间 |
httpOnly |
cookie 是否只能通过 HTTP 协议访问 |
secure |
cookie 是否只能通过 HTTPS 协议传输 |
sameSite |
cookie 的 SameSite 属性 |
priority |
cookie 的优先级 |
sameParty |
cookie 是否只能通过同一站点访问 |
iframe 操作
iframe 是一个 HTML 标签, 可以用于嵌入其他网页, puppeteer 可以用 frame 对象来操作 iframe 中的元素
| 方法 | 作用 |
|---|---|
page.frames() |
返回一个 Frame 对象的数组 |
page.mainFrame() |
返回主 frame 对象 |
frames.find(frame => null) |
用数组的 find 方法来查找 iframe |
frame.xxx |
Frame 对象的方法与 page 对象的方法基本相同 |
frame.childFrames() |
返回一个 Frame 对象的数组用于查找 iframe 中的 iframe |
frame没有screenshot、pdf、mainFrame、frames等方法- 要等待
iframe加载完毕, 直接使用page.waitForNetworkIdle()即可 - 但要等待
iframe中的元素出现时, 需要使用frame.waitForSelector()方法
1 | // 获取所有的 iframe |
元素操作
ElementHandle 对象是一个 JSHandle 对象的实例, 可以用于操作网页元素, 如点击、输入、获取属性等
| 方法 | 作用 |
|---|---|
page.$(selector) |
选择一个元素, 返回一个 ElementHandle 对象 |
page.$$(selector) |
选择多个元素, 返回一个 ElementHandle 对象的数组 |
page.$eval(selector, ele => null) |
$ 和 evaluate 的结合, 返回一个 Promise |
page.$$eval(selector, eles => null) |
$$ 和 evaluate 的结合, 返回一个 Promise |
elementHandle.click() |
点击一个元素 |
elementHandle.type('text') |
在一个输入框中输入文本 |
elementHandle.select('value') |
选择一个下拉框中的选项 |
elementHandle.focus() |
聚焦一个元素 |
elementHandle.hover() |
悬停在一个元素上 |
elementHandle.screenshot({ path }) |
截取一个元素的截图, 保存到指定路径 |
- 与真实的
DOM元素不同,ElementHandle对象的操作都是异步的, 返回Promise对象 - 其他的方法与
DOM元素的操作方法类似, 不再赘述 - 以上操作也可以用
page.click(selector)等方法来代替, 效果相同
Playwright
Playwright 由 Microsoft 开发, 用于操纵 Chrome、Firefox、WebKit 浏览器, 可以用于爬取网页数据、生成网页截图、生成 PDF 等; Playwright 支持 Node.js、Python、C#、Go 等语言, 详见官方文档 (其 API 与 Puppeteer 非常相似)
🚧 bun test
🚧 deno test
微服务
Wrangler
Wrangler 是一个 Cloudflare Workers 的命令行工具, 可以用于创建、部署、管理 Cloudflare Workers, 详见官方文档
1 | # 安装 wrangler |
| 命令 | 作用 |
|---|---|
npm create cloudflare |
初始化项目 |
wrangler docs |
打开文档 |
wrangler login |
登录 Cloudflare 账号 |
wrangler dev |
启动本地开发服务器 |
wrangler deploy |
部署项目至 Cloudflare Workers |
wrangler d1 create <name> |
创建一个数据库 |
wrangler d1 info <name> |
查看数据库信息 |
wrangler d1 list |
查看账号的所有数据库 |
wrangler kv:namespace create <name> |
创建一个命名空间 |
wrangler kv:namespace list |
查看账号的所有命名空间 |
wrangler r2 bucket create <name> |
创建一个存储桶 |
wrangler r2 bucket list |
查看账号的所有存储桶 |
D1是Cloudflare推出的一个Serverless数据库, 采用SQL语法KV也是一个Serverless数据库, 数据以键值对的形式存储R2是Cloudflare推出的对象存储服务, 兼容S3协议
wrangler.toml
wrangler.toml 是一个配置文件, 用于配置 Cloudflare Workers 的一些参数
1 | name = "my-worker" # 项目名称 |
示例
以下是一些 worker 环境的基本代码, 点击查看更多教程
1 | // src/index.js |
返回网页
1 | export default { |
返回 JSON
1 | export default { |
简单的代理服务器
1 | export default { |
Vercel
1 | # 安装 |
桌面/移动应用
Electron
Electron 是一个 Node.js 框架, 可以用于创建桌面应用程序; Electron Vite 是一个命令行工具, 可以用于创建 Electron 项目, 详见官方文档
1 | bun create @quick-start/electron@latest |
流程模型
Electron 分为 Main 进程和 Renderer 进程, Main 进程用于控制应用程序的生命周期, 属于 Node.js 进程, Renderer 进程用于显示 HTML 页面, 属于 Chromium 进程
Main 进程可以通过 BrowserWindow 类来创建窗口 (Renderer 进程), 通过 ipcMain 和 ipcRenderer 来进行进程间通信
除此之外, 还有 preload 脚本, 在 Renderer 进程中运行, 它只能访问少量的 Node.js 模块, 主要用于与 Main 进程通信
进程通信
ipcMain 和 ipcRenderer 是 Electron 提供的两个模块, 用于 Main 进程和 Renderer 进程之间的通信
1 | // main.ts |
1 | // preload.ts |
1 | // renderer.ts |
on和send类似于Wails中的事件,handle和invoke类似于Wails中调用Go函数
主进程发送浏览器事件
BrowserWindow 类的 webContents 属性可以用于发送浏览器事件
1 | // main.ts |
1 | // renderer.ts |
这个有点奇怪, 为什么不像
Wails一样直接用ipcMain来向ipcRenderer发送事件
Wails
Wails 是一个用于构建桌面应用程序的框架, 使用 Go 和 Web 技术进行开发, 类似于 Rust 的 Tauri
1 | # 安装命令行工具 |
调用 Go 函数
Wails 将自动生成 Go 函数的 TypeScript 类型定义, 通过 import { Xxx } from '../wailsjs/go/main/App' 即可引入; 所有的 Go 函数都返回 Promise
1 | import { SayHello } from '../wailsjs/go/main/App' |
API
Go 中的 API 通过导入 github.com/wailsapp/wails/v2/pkg/runtime 来获取, 所有函数的第一个参数 context 都是应用启动时传入的上下文
JavaScript 中的 API 全部挂在 window.runtime 下, 可以通过 runtime.xxx 来调用
Go |
JavaScript |
描述 |
|---|---|---|
Hide(c) |
runtime.Hide() |
隐藏窗口 |
Show(c) |
runtime.Show() |
显示窗口 |
Quit(c) |
runtime.Quit() |
退出应用 |
BrowserOpenURL(c, "url") |
runtime.BrowserOpenURL('url') |
在默认浏览器中打开链接 |
ClipboardGetText(c) |
runtime.ClipboardGetText() |
获取剪贴板文本 |
ClipboardSetText(c, "text") |
runtime.ClipboardSetText('text') |
设置剪贴板文本 |
MessageDialog(c, MessageDialogOptions) |
消息对话框, 返回 (string, error) |
MessageDialogOptions
| 字段 | 描述 |
|---|---|
Type |
弹窗类型, InfoDialog、ErrorDialog、WarningDialog、QuestionDialog |
Title |
标题 |
Message |
消息 |
Buttons |
按钮, 仅对 Mac 有效 |
DefaultButton |
默认按钮, OK、Cancel、Yes、No |
CancelButton |
取消按钮, OK、Cancel、Yes、No |
事件
Wails 中的事件在 Go 和 JavaScript 之间是统一的
Go |
JavaScript |
描述 |
|---|---|---|
EventsOn(c, "event", f([data])) |
runtime.EventsOn('event', f([data])) |
监听事件 |
EventsOff(c, "event") |
runtime.EventsOff('event') |
取消监听事件 |
EventsOnce(c, "event", f([data])) |
runtime.EventsOnce('event', f([data])) |
一次性监听事件 |
EventsOnMultiple(c, "event", f([data]), count) |
runtime.EventsOnMultiple('event', f([data]), count) |
监听多次事件, 返回取消监听的函数 |
EventsEmit(c, "event", data) |
runtime.EventsEmit('event', data) |
触发事件 |
窗口
Go |
JavaScript |
描述 |
|---|---|---|
WindowSetTitle(c, "title") |
runtime.WindowSetTitle('title') |
设置窗口标题 |
WindowFullscreen(c) |
runtime.WindowFullscreen() |
全屏窗口 |
WindowUnFullscreen(c) |
runtime.WindowUnFullscreen() |
退出全屏 |
WindowIsFullscreen(c) |
runtime.WindowIsFullscreen() |
判断是否全屏 |
WindowCenter(c) |
runtime.WindowCenter() |
居中窗口 |
WindowReload(c) |
runtime.WindowReload() |
重新加载窗口 |
WindowSetAlwaysOnTop(c, bool) |
runtime.WindowSetAlwaysOnTop(bool) |
设置窗口是否置顶 |
WindowMaximise(c)WindowUnmaximise(c)WindowIsMaximised(c) |
runtime.WindowMaximise()runtime.WindowUnMaximise()runtime.WindowIsMaximised() |
最大化窗口 |
WindowMinimise(c)WindowUnminimise(c)WindowIsMinimised(c) |
runtime.WindowMinimise()runtime.WindowUnMinimise()runtime.WindowIsMinimised() |
最小化窗口 |
WindowToggleMaximise(c) |
runtime.WindowToggleMaximise() |
在最大化和非最大化之间切换 |
配置
wails.Run() 方法接收一个 options.App 结构体, 用于配置应用
| 字段 | 类型 | 描述 |
|---|---|---|
Width |
int |
窗口宽度 |
Height |
int |
窗口高度 |
Title |
string |
窗口标题 |
Framelss |
bool |
是否无边框 |
MinWidth |
int |
窗口最小宽度 |
MinHeight |
int |
窗口最小高度 |
MaxWidth |
int |
窗口最大宽度 |
MaxHeight |
int |
窗口最大高度 |
StartHidden |
bool |
启动时是否隐藏 |
BackgroundColour |
*options.RGBA |
背景颜色 |
AlwaysOnTop |
bool |
是否置顶 |
OnStartup |
func(c) |
启动时 (index.html 加载前) 回调 |
OnDomReady |
func(c) |
DOM 加载完成后回调 |
OnShutdown |
func(c) |
关闭时回调 |
OnBeforeClose |
func(c) |
关闭前回调 |
Windows |
*windows.Options |
Windows 配置 |
Mac |
*mac.Options |
Mac 配置 |
Linux |
*linux.Options |
Linux 配置 |
对于无边框窗口,
Wails提供了一个非常简单的拖动解决方案: 任何具有--wails-draggable:drag样式的元素都可以拖动窗口
Windows
| 字段 | 类型 | 描述 |
|---|---|---|
WebviewIsTransparent |
bool |
Webview 是否透明 |
WindowIsTranslucent |
bool |
窗口是否半透明 |
BackdropType |
windows.BackdropType |
半透明背景类型 |
DisableWindowIcon |
bool |
禁用窗口图标 |
半透明背景类型有
3: Acrylic(亚克力) 和2: Mica(亚克力玻璃) 等
Mac
| 字段 | 类型 | 描述 |
|---|---|---|
TitleBar |
*mac.TitleBar |
标题栏外观 |
WebviewIsTransparent |
bool |
Webview 是否透明 |
WindowIsTranslucent |
bool |
窗口是否半透明 |
Linux
| 字段 | 类型 | 描述 |
|---|---|---|
WindowIsTranslucent |
bool |
窗口是否半透明 |
Tauri
Tauri 是一个用于构建桌面端/移动端应用程序的 Rust 框架, 它使用 Web 技术来构建用户界面, 并使用 Rust 来构建应用程序的后端
Tauri类似于Electron, 也有一个Core进程和一个/多个Webview进程, 但Tauri的Webview直接使用系统的Webview组件, 而不是使用内置的Chromium内核Tauri也使用了类似Electron的IPC机制, 并将其分为Events(事件, 核心进程和浏览器进程都可以发送) 和Commands(命令, 浏览器进程调用, 核心进程执行)- 浏览器进程和核心进程之间有
Brownfield(默认) 和Isolation两种关系模式;Isolation模式下, 所有前端发送到后端的信息都将经过一个安全程序的检查或修改, 这会带来一定的性能开销和兼容性问题, 详见官方文档相关内容 Tauri可以嵌入附加文件, 并在Rust或JavaScript中访问, 详见官方文档Tauri可以嵌入外部可执行文件, 称为sidecar, 并在Rust或JavaScript中访问, 详见官方文档- 如果在
Rust端需要对某个状态进行竞争性访问, 可能需要使用std::sync::Mutex等线程安全的数据结构, 详见官方文档 - 关于软件分发、安全性、测试工具的更多信息, 详见官方文档
1 | # 创建一个新项目 |
移动开发相关额外设置详见官方文档
Events
Tauri 中的 Events 用于在 Rust 和 JavaScript 之间进行简单通信, 相比于 Commands, Events 没有强类型支持, 事件的有效负载始终是一个 JSON 字符串
后端发送全局事件
1 | use tauri::{AppHandle, Emitter}; |
后端向特定浏览器发送事件
1 | use tauri::{AppHandle, Emitter}; |
前端监听全局事件
1 | import { listen } from '@tauri-apps/api/event'; |
注意:
listen函数返回一个unlisten函数, 用于取消监听事件; 对于MPA项目, 切换页面时会自动取消当前页面监听, 但对于SPA项目, 需要手动取消监听 (对于React项目, 应在useEffect监听并在return中取消监听)
前端监听特定浏览器事件
1 | import { getCurrentWebviewWindow } from '@tauri-apps/api/webviewWindow'; |
前端单次监听
1 | import { once } from '@tauri-apps/api/event'; |
后端监听全局事件
1 | use tauri::Listener; |
取消监听
1 | // unlisten outside of the event handler scope: |
后端监听特定浏览器事件
1 | use tauri::{Listener, Manager}; |
后端单次监听
1 | app.once("ready", |event| { |
前端触发全局事件
1 | import { emit } from '@tauri-apps/api/event'; |
前端触发特定浏览器事件
1 | import { emit } from '@tauri-apps/api/event'; |
Channels
Events 不适合用于发送大量或强即时性的数据, Channels 则被设计用于快速传递有序的数据流, 例如下载进度、子进程输出等
Rust 端
1 | use tauri::{AppHandle, ipc::Channel}; |
JavaScript 端
1 | import { invoke, Channel } from '@tauri-apps/api/core'; |
webview.eval
webview.eval 方法用于在 Rust 中控制前端执行 JavaScript 代码
1 | use tauri::Manager; |
对于复杂脚本, 推荐使用
serialize-to-javascripitCrate
Commands
Commands 用于在 JavaScript 中调用 Rust 函数
1 | // src-tauri/src/lib.rs |
1 | // 导入方法一 |
- 函数的参数名分别遵守
Rust和JavaScript的命名规范, 即snake_case和camelCase; 在JavaScript中调用时, 所有参数作为一个对象传入invoke函数的第二个参数 Rust函数的返回值可以是一个Result类型, 以便JavaScript可以处理错误- 函数返回值必须可以被序列化为
JSON格式, 即实现serde::Serialize特性 - 一些第三方库的错误可能无法被序列化, 可以使用
map_err方法将错误转换为字符串; 也可以使用自定义错误, 详见官方文档 Tauri中的命令默认是同步的, 如果需要异步命令, 在命令函数fn前添加async关键字即可; 目前, 异步命令不可以直接包含借用参数, 详见官方文档- 命令还可以访问
WebviewWindow、AppHandle、状态、原始IPC请求等数据, 详见官方文档
在单独的模块中导出命令
1 | // src-tauri/src/commands.rs |
1 | // src-tauri/src/lib.rs |
Plugins
Tauri 通过其插件系统支持各个系统的原生功能, 例如文件系统、系统通知、剪贴板、对话框、NFC、SQL 等, 从而让开发者在很多情况下不用编写 Rust、Kotlin 或 Swift 代码
各个插件支持的平台不尽相同, 详见官方文档
🚧 React Native
React Native 是一个用于构建移动应用程序的框架, 使用 JavaScript 和 React 进行开发, 通过 JavaScript 代码调用原生 API 来实现跨平台开发
由于页面的布局和样式是由原生组件实现的, 所以 React Native 的性能和体验要优于基于 Web 技术的 Tauri 和 Ionic 框架
其他
WebAssembly
🚧 AssemblyScript
Rust
wasm-pack 是一个用于构建 Rust 项目为 WebAssembly 模块的工具, 它可以将 Rust 项目编译为 WebAssembly 模块, 并生成 JavaScript 包装器, 以便在 Web 环境中调用
1 | # 添加 wasm32-unknown-unknown 编译目标 |
1 | use wasm_bindgen::prelude::*; |
1 | import init, { add } from 'xxx' |
🚧 Pyodide
🚧 WebR
Docker
Docker 是一个开源的应用容器引擎, 使用 Go 语言开发, 可以让开发者打包应用及其依赖, 并以容器的形式进行交付; 相比于虚拟机, 容器更轻量, 更快速, 可以在同一台机器上运行更多的容器
推荐使用 Docker Desktop 来安装 Docker 和 Docker Compose
| 命令 | 描述 |
|---|---|
docker version/info |
查看版本/信息 |
docker pull/rmi <image>[:tag] |
拉取(下载)/删除镜像 |
docker images |
查看镜像 |
docker ps [-a] [-s] |
查看容器, -a 查看所有容器, -s 查看容器资源使用情况 |
docker run [-d] [-p from:to] [-e xxx=xxx] [--name xxx] <image[:tag]> |
运行容器-d 后台运行(不占用当前控制台)-p 端口映射, 主机端口:容器端口--name 容器名称-e 环境变量, 可以多次使用 |
docker rename <container> newname |
重命名容器 |
docker port/top/stats/logs <container> |
查看容器端口/进程/资源使用情况/日志 |
docker start/stop/restart/pause/unpause <container> |
启动/停止/重启/暂停/恢复容器 |
docker rm [-f] <container> |
删除容器, -f 强制删除 |
docker exec -it <container> bash |
进入容器, -it 交互式终端, bash 进入 bash |
docker cp <container>:<path> <path> |
从容器中复制文件到宿主机, 反之亦然 |
docker commit [-m "xxx"] <container> <image[:tag]> |
提交容器为镜像, 类似于 git commit |
docker save [-o <file.tar>] <image> |
保存镜像为文件 |
docker load -i <file.tar> |
加载镜像文件 |
docker login |
登录 Docker Hub |
docker tag <image[:tag]> <newimage[:tag]> |
重命名镜像, 发布镜像时需要重命名为 username/repo重命名后原镜像不会被删除, 两个镜像的 ID 相同 |
docker push <image[:tag]> |
发布镜像到 Docker Hub |
小寄巧-删除全部容器:
docker rm -f $(docker ps -aq)
存储
Docker 容器中的文件可以通过目录挂载 (将宿主机目录/文件挂载到容器目录/文件中) 或卷映射 (将容器目录/文件映射到宿主机中 Docker 的卷目录中) 来保存和编辑; 前者会将宿主机目录/文件覆盖到容器中
- 也可以直接在
Docker Desktop中编辑容器的文件 - 使用命令
docker volume ls可以查看所有卷 -v参数可以多次使用, 用于挂载/映射多个目录/卷
| 方式 | 命令 |
|---|---|
| 目录挂载 | docker run -v /path/in/host:/path/in/container删除容器后, 被挂载的目录/文件不会被删除 |
| 卷映射 | docker run -v <volume_name>:/path/in/container为了区分卷名和路径, 目录挂载中的 ./ 不能省略Docker 会在 /var/lib/docker/volumes 中创建或使用已有卷, 删除容器后, 卷不会被删除 |
如果出现
Permission Denied错误, 可以在主机中修改文件权限:chmod -R 777 /path/in/host
网络
在默认情况下, 容器使用 bridge 网络, 通过 NAT 进行通信, 通过 docker0 网桥连接宿主机; 容器的 IP 地址为 172.17.0.x, 网关地址都是 172.17.0.1, 相互之间可以通过内网 IP 直接通信
默认的 bridge 网络不支持主机域名的解析, 可以通过 docker network create 创建自定义网络, 通过 docker run --network <network> 指定容器使用的网络
| 命令 | 描述 |
|---|---|
docker network ls |
查看所有网络(包括一些内置网络) |
docker network create <name> |
创建网络(默认 driver 为 bridge, 但可以通过容器名作为域名来进行容器间通信) |
docker network inspect <name> |
查看网络详情 |
docker network connect/disconnect <network> <container> |
连接/断开容器网络 |
docker network rm <network> |
删除网络 |
| 内置网络 | 描述 |
|---|---|
bridge |
默认模式, driver 为 bridge |
host |
容器和宿主机共享网络, 容器端口和宿主机端口一致, driver 为 host |
none |
容器不使用网络, 仅 localhost, driver 为 null |
container:<name> |
容器和指定容器共享网络, 两个容器可以通过 localhost 直接通信 |
Docker Compose
Docker Compose 是一个用于定义和运行多容器 Docker 应用程序的工具, 通过 YAML 文件配置, 可以一次性启动多个容器
docker compose 或 docker-compose 命令会自动在当前目录查找 compose.yaml 文件, 也可以通过 -f 参数指定文件
| 命令 | 描述 |
|---|---|
docker compose up [-d] [-w] |
创建并启动容器, -d 后台启动, -w 监听配置变化 |
docker compose down [-v] [--rmi all] |
停止并删除容器和网络, -v 删除卷, --rmi all 删除所有镜像 |
docker compose start/stop/restart <service> |
启动/停止/重启某个服务 |
docker compose scale <service>=n |
扩展服务数量 |
docker compose ps |
查看容器状态 |
docker compose logs <service> |
查看容器日志 |
1 | # compose.yaml |
执行
docker compose up时, 实际创建的容器/卷/网络等的名称都为project-name_xxx
Dockerfile
Dockerfile 是一个文本文件, 包含了一系列命令, 用于构建 Docker 镜像
构建时, Docker 会从 FROM 开始执行, 每一条指令都会创建一个新的镜像层; 通过分层, 可以在多个镜像间实现层的复用, 减少实际需要存储的镜像的体积
实际上, 每个容器都有一个只读的镜像层, 以及一个可读写的容器层, 容器层的改动不会影响镜像层, 但可以通过 commit 命令保存为新的镜像; 如果不保存, 容器删除后, 容器层也会被删除
| 命令 | 描述 |
|---|---|
docker build -t <image[:tag]> [-f <Dockerfile>] <path> |
构建镜像 |
docker build . |
使用当前目录下的 Dockerfile 构建镜像 |
docker init |
在项目中初始化 docker 相关文件 |
docker compose up --build [-d] |
构建并启动容器 |
docker history <image> |
查看镜像构建历史(各个层) |
1 | # Dockerfile |
打包一个JAVA程序
1 | FROM openjdk:17 |
打包一个Next.js程序
1 | FROM bun:latest |
.dockerignore
.dockerignore 文件用于指定哪些文件不需要被复制到镜像中, 语法和 .gitignore 相同
多阶段构建
使用多阶段构建能将构建依赖留在 builder 镜像中,只将编译完成后的二进制文件拷贝到运行环境中,大大减少镜像体积
1 | FROM golang:alpine as builder |
- 标题: 全栈开发相关学习笔记
- 作者: 小叶子
- 创建于 : 2024-02-18 09:10:27
- 更新于 : 2026-02-25 14:11:09
- 链接: https://blog.leafyee.xyz/2024/02/18/Fullstack/
- 版权声明: 版权所有 © 小叶子,禁止转载。


