
心理统计学
封面作者:NOEYEBROW
推荐使用:在线统计软件 PsychPen, 内含统计检验、图表绘制、统计量P值转换等功能
本笔记源自:
- 北京师范大学张丹慧老师本科课程 - 心理统计
- Fang J., Wen Z., Ouyang J., & Cai B. (2022). Methodological research on moderation effects in China’s mainland. Advances in Psychological Science, 30(8), 1703. https://doi.org/10.3724/SP.J.1042.2022.01703
- Wen, Z., Fang, J., Xie, J., & Ouyang, J. (2022). Methodological research on mediation effects in China’s mainland. Advances in Psychological Science, 30(8), 1692. https://doi.org/10.3724/SP.J.1042.2022.01692
- 方差分析后的公式不再直接在笔记中列出, 请点击下载复习笔记查看, 内含”心理统计(下)”可能需要记忆的所有公式 🚧 部分未完成内容也可以参考这个笔记 🚧
- 如果仍不清楚, 可以在师大云盘下载附带笔记的教材查阅
- 其中多元线性回归一章请点击此处独立下载
- 点击跳转到速查表
统计学概述
统计学 / Statistics
一套组织、总结和解释信息的数学过程
统计量 / Statistic
基于某些个体的观测值而重新计算出来的新的值
抽样和测量
抽样 / Sampling
从总体 实际上是抽样框 中选取个体, 用以推测总体的性质
- 总体
Population: 特定研究中所关注的所有个体的集合 - 个体
Individual: 一组数据描述的对象, 它可以是人, 也可以是动物 - 抽样框
Sampling Frame: 总体中能够被抽样的部分, 应尽量接近总体 - 抽样单元
Sampling Unit: 抽样框中的每一个部分个体/学校/机构等 - 样本
Sample: 那些从总体中选出的个体, 通常在研究中是被用来代表总体的 - 样本量
Sample Size: 研究中被试的数目, 或一个观测重复的次数一般n≥30则称为大样本
| 概率抽样 | 非概率抽样 |
|
|
测量 / Measurement
利用适当的工具对个体的某些属性赋予数值的过程
参见心理测量学笔记
- 变量
Variable: 因个体不同而可以改变、或具有不同的数值的属性 - 常量
Constant: 不变的、对每个个体都相同的特征或环境 - 参数
Parameter: 一个描述总体某种性质的数值, 是一个常量, 通常是未知的, 一般使用统计量的均值来估计 - 统计量
Statistic: 一个描述样本某种性质的数值, 是一个变量, 能从样本得到, 用来估计总体的参数也叫做总体的估计值 - 变异性
Variability: 在相同的条件下, 不同个体得到的测量数据存在差异的特点源于个体差异和抽样误差 - 抽样误差
Sampling Error: 一种差异, 或一些存在于样本统计量和总体参数之间的随机误差 - 偏差
Bias: 由抽样框、抽样方法、测量工具的不当而造成的系统误差
数据和符号
原始分数
一般用 X 表示, 其中 X 代表一个个体的分数, X1 代表第一个个体的分数, X2 代表第二个个体的分数, 以此类推
求和符号
一般用 Σ 表示, 其中 Σ 代表求和, ΣX 代表所有个体的分数之和, ΣX2 代表所有个体的分数的平方之和, 以此类推
比率与比例
- 比率
Ratio: 两个数值之间的比值 - 比例
Proportion: 某个数值与总数之间的比值 - 百分数
Percentage: 通常会写成.xx而不是0.xx或xx%
频数与频率
- 频数
Frequency: 某个数值出现的次数 - 频率
Relative Frequency: 某个数值出现的次数与总数的比值 - 累积频数
Cumulative Frequency: 某个数值及其之前的数值出现的次数之和 - 累积频率
Cumulative Relative Frequency: 某个数值及其之前的数值出现的次数之和与总数的比值
计数数据与测量数据
- 计数数据: 计算个数的数据, 具有独立的分类单位, 一般都取整数
人数、反应发生次数等 - 测量数据: 用一定的测量工具测量得到的数据, 数据是连续的, 可以是整数也可以是小数, 由于测量误差的存在, 是一种近似值
身高、体重、测验分数、幸福度等
数据类型
- 称名数据
Nominal Data: 数据仅用于对观察对象进行命名和分类, 相互之间没有数量关系性别、民族、学历等 - 等级数据
Ordinal Data: 又称顺序数据, 数据可以按照大小顺序排列, 但没有等间距性和绝对零点ABCD等级成绩、职位等 - 等距数据
Interval Data: 数据可以按照大小顺序排列, 且相邻数据之间的间距是相等的, 但没有绝对零点摄氏温度、IQ等 - 等比数据
Ratio Data: 数据可以按照大小顺序排列, 且相邻数据之间的间距是相等的, 且有绝对零点华氏温度、长度、重量等
- 连续数据
Continuous Data: 任意两个数据点间可以无限地划分出大小不同的数值, 在数轴上用一段距离表示, 对其的测量结果是一种近似值, 只表示一个数据范围即精确区间 - 离散数据
Discrete Data: 不连续, 任意两个数据点之间的取值是有限的, 在数轴上用一个个点表示 - 精确区间: 类似于
0.12、0.13、0.14这样的连续数据,0.12其实是表示[0.115,0.125), 这个区间称为精确区间,0.115称为精确下限,0.125称为精确上限
四舍五入
为了结果精确, 计算过程要比计算结果多保留一位小数, 最后结果四舍五入
描述统计
Descriptive Statistics
用来总结、整理和简化数据的统计方法
数据分布
Data Distribution
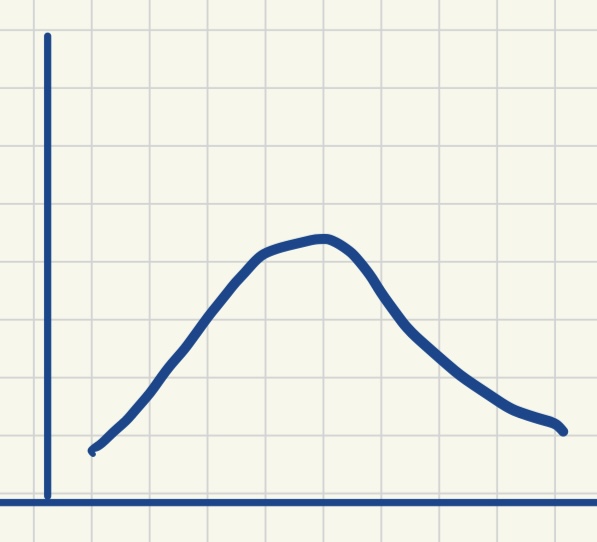
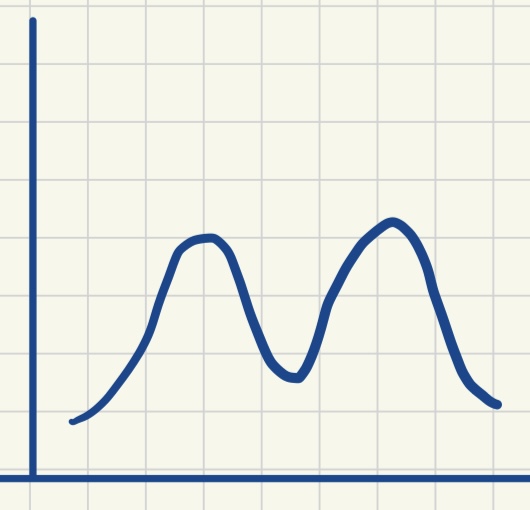
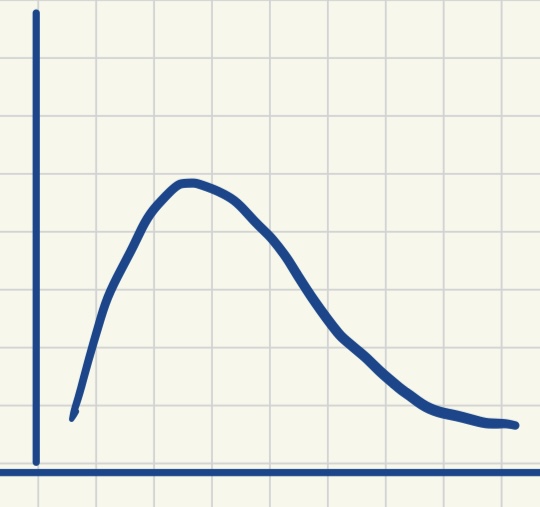
| 单峰对称分布 | 双峰对称分布 | 正偏态分布 | 负偏态分布 |
|---|---|---|---|
 |
 |
 |
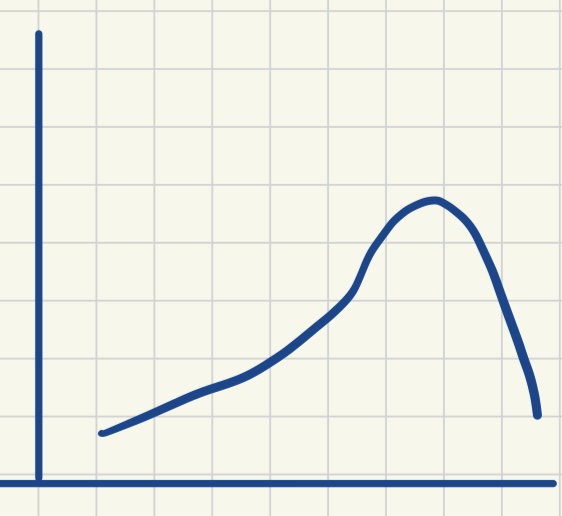 |
| 众数 = 平均数 = 中位数 | 众数1 < 平均数 = 中位数 < 众数2 | 众数 < 中位数 < 平均数 | 平均数 < 中位数 < 众数 |
集中趋势
Central Tendency
用来描述一组数据分布的中心的统计指标
平均数 / Mean
所有个体分数之和除以个体总数, 总体均值用 μ 表示, 样本均值用 M 或 x̄ 表示
计算公式
- 总体均值: μ = ΣX / N
- 样本均值: x̄ = ΣX / n
- 加权平均数: x̄ = ΣwiXi / Σwi
wi 代表第 i 个个体 / 群体的权重 / 人数
Xi 代表第 i 个个体 / 群体的分数 / 均分
性质
- 改变一个数据, 均值会改变
- 加入或删除一个数据, 均值会改变
- 每个数据都改变
加减乘除一个常数, 均值也会改变这个常数 - 离均差之和为零, 即 Σ(Xi - x̄) = 0
- 容易受到极端值的影响
平均工资
离均差: 每个数据与均值的差值, 有正负
离差平方和: 所有离均差的平方之和, 用 SS 表示
众数 / Mode
出现次数最多的分数, 用 Mo 表示
- 一般计数数据可以直接看出众数
- 通过皮尔逊经验公式计算众数: Mo ≈ 3Md - 2M
M 代表均值, Md 代表中位数, 要求数据接近正态分布 - 通过金氏插补法公式计算众数: Mo = LMo + i [ fa / (fa + fb) ]
LMo 代表众数所在区间的精确下限, fa 代表高于众数所在组的那一组的频数, fb 代表低于众数所在组的那一组的频数, i 代表组距, 数据可以是偏态分布
中位数 / Median
将所有个体分数按大小顺序排列, 位于中间的分数, 用 Md 表示
- 奇数个数据, 则中位数为中间的那个数据
- 偶数个数据, 则中位数为中间两个数据的平均数
- 中位数不受极端值影响
- 有重复数据时, 把重复数据看作等距的几个数据计算
如下
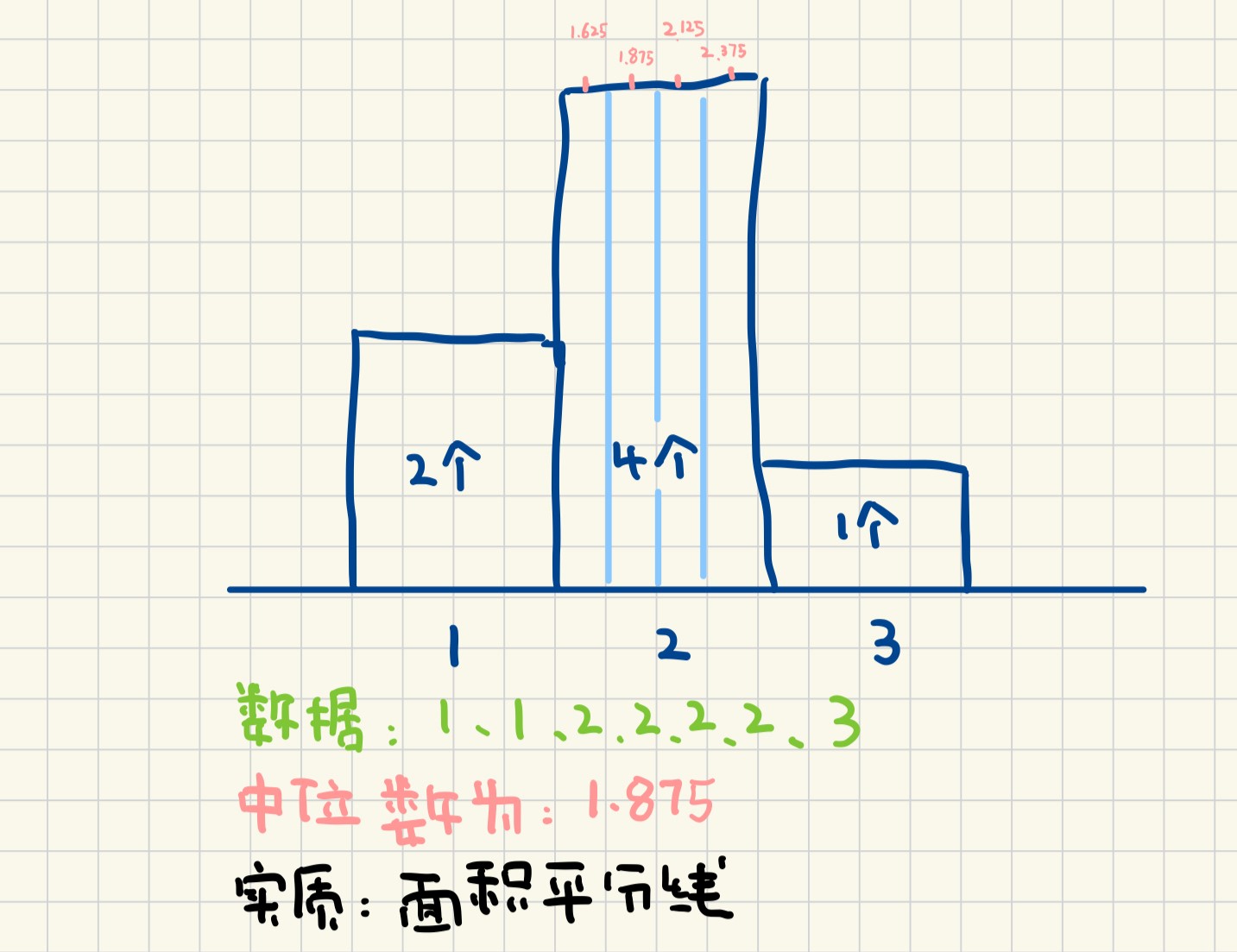
但是实际操作中, 也有直接忽略重复数据, 按通常方法计算的,
反正不会去手算, 统计软件说什么就是什么吧
离散趋势
Dispersion Tendency
用来描述一组数据变异或分散程度的统计指标
全距 / Range
数据分布中最大值与最小值之差, 又称两极差, 用 R 表示
- 对于原始数据, R = Xmax - Xmin
- 对于分组数据
不知道原始数据是什么, R = 最大组的精确上限 - 最小组的精确下限
四分位数 / Quartile
有三个, 用 Q1、Q2、Q3 表示, 分别代表25%的百分位数、50%的百分位数、75%的百分位数
计算方法
将N个原始数据从大到小排序, 第 (N + 1) / 4 个数据为 Q1, 第 3(N + 1) / 4 个数据为 Q3
如果 (N + 1) / 4 和 3(N + 1) / 4 不是整数, 则在临近两个数之间, 根据算出的值的小数部分, 按照比例插值
例如, 若算出 (N + 1) / 4 为 3.25, 而第三个数据为5, 第四个数据为7, 则 Q1 = 5 + 0.25 x (7 - 5) = 5.5
四分位差 / Quartile Deviation
分布在中央50%的数据的全距, 等于第三四分位数减去第一四分位数, 用 Q 表示, Q = Q3 - Q1
- 四分位差不等于全距的一半
- 分半四分位差等于四分位差的一半, 即 (Q3 - Q1) / 2
方差 / Variance
又称变异数、均方, 离差平方和的算数平均数, 表示一组数据的离散程度, 总体方差用 σ2 表示, 样本方差用 s2 表示
计算公式
- 自由度
Degree of Freedom, df: 样本中独立或自由变化的数据的个数, 一般df = n - 1 - 离差平方和: SS = Σ(X - x̄)2 或 SS = ΣX2 - (ΣX)2 / N
加权算法同加权平均数 - 总体方差: σ2 = SS / N
- 样本方差: s2 = SS / (n - 1) 即 s2 = SS / df
无偏估计: 由于样本的变异一般小于总体的变异, 所以样本方差会小于总体方差, 即如果用相同公式计算, 样本方差是有偏的, 而用自由度代替样本量进行修正后, 样本方差是无偏的
标准差 / Standard Deviation
方差的算术平方根, 表示一组数据的离散程度, 总体标准差用 σ 表示, 样本标准差用 s 或 SD 表示, 一般与均值相差三个标准差以上的数据会被称为极端值
方差和标准差的相关计算公式
| 分样本方差合成总样本方差 | 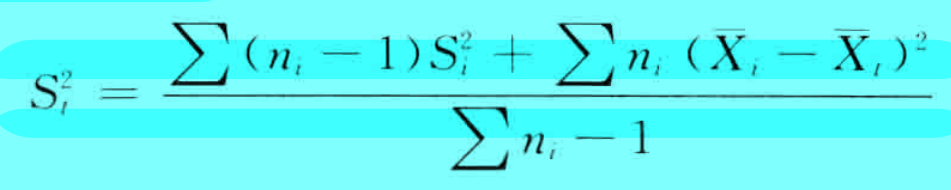 |
| 方差和标准差的变换 |
|
差异系数 / Coefficient of Variation
又称变异系数、相对标准差, 指一组数据的标准差与均值之比, 用 CV 表示, CV = s / x̄ 也可以再乘个100%, 适用于不同单位的数据的比较
相对位置量数
百分位数与百分等级
- 百分等级
Percentile Rank: 在一组数据中, 不高于某个分数的百分比, 一般用 Pp 表示 - 百分位数
Percentile: 某个百分等级对应的分数, 一般用 p 表示 - 百分位数 → 百分等级: Pp = Lp + i (pn - fb) / fp
Lp 代表百分位数所在组的精确下限
i 代表组距
p 代表百分等级
n 代表样本量
fb 代表低于百分位数所在组的各组的累积频数
fp 代表百分位数所在组的频数 - 原始分数 → 百分位数: p = (100 / N) [ f (X - Lb) / i + Fb ]
X 代表原始分数
Lb 代表原始分数所在组的精确下限
i 代表组距
f 代表原始分数所在组的频数
Fb 代表低于原始分数所在组的各组的累积频数
N 代表样本量
Z分数与T分数
- 标准分数
Standard Score: 将原始分数转换无单位的、表示相对位置的、可比可加的量数, 用 Z 表示, Z = (X - x̄) / s - 标准化分布
Normalized Distribution: 将原始分数的标准差和均值转化为特定的数值Z分布中均值为0, 标准差为1, 分布的形状不会改变 - T分数
T Score: 将原始分数转换为均值为50, 标准差为10的分数, 用 T 表示, T = 50 + 10Z和T检验不是同一个概念
推论统计
Inferential Statistics
用来研究样本, 并推论总体的统计方法
正态分布
Normal Distribution
概率密度函数如下的分布, 其中 μ 代表均值, σ 代表标准差, π 代表圆周率, e 代表自然对数的底数
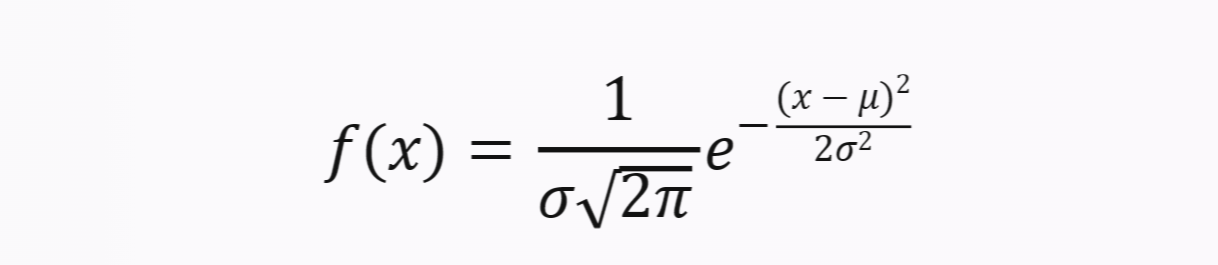
- 正态曲线关于均值对称, 均值处为最高点
- 正态曲线是单峰分布
- 正态分布的拐点是 x = μ ± σ 处
- μ 影响正态分布曲线的位置, 称为位置参数
- σ 影响正态分布曲线的形状, 称为形状参数
标准正态分布
均值为0, 标准差为1的正态分布
| Z值范围 | 概率 / 占总数比例 |
|---|---|
| [-1.645, 1.645] | 0.90 |
| [-1.96, 1.96] | 0.95 |
| [-2.58, 2.58] | 0.99 |
| [-1, 1] | 0.683 |
| [-2, 2] | 0.954 |
| [-3, 3] | 0.997 |
抽样分布
某个样本统计量 一般是均值 的分布, 即无限次重复抽样后, 所得的样本们的均值所组成的分布
- 中心极限定理: 当样本量足够大时, 样本均值的抽样分布近似于正态分布, 且均值为 μ(总体均值), 标准差为 σ / √n(总体标准差 / 样本量的平方根)
- 只要总体是正态分布、样本量大于等于30, 样本均值的抽样分布就近似于正态分布
- 样本均值的标准差称为标准误, 用 SE 表示, SE = σ / √n
- 样本量越大, 样本均值越接近总体均值, 标准误越小
假设检验
利用样本信息, 根据一定概率, 对总体参数或分布的某个假设做出接受或拒绝的判断的过程
- 虚无假设
Null Hypothesis: 也称原假设或零假设, 通常指某个参数无变化的假设, 用 H0 表示, 研究中我们通常希望拒绝它 - 备择假设
Alternative Hypothesis: 也称研究假设或对立假设, 通常指某个参数有变化的假设, 用 H1 表示, 研究中我们通常希望接受它 - 小概率原理: 当样本统计量在参数不变的条件下, 出现的概率低于某个临界值时, 我们就认为参数发生了变化, 拒绝虚无假设
- α水平
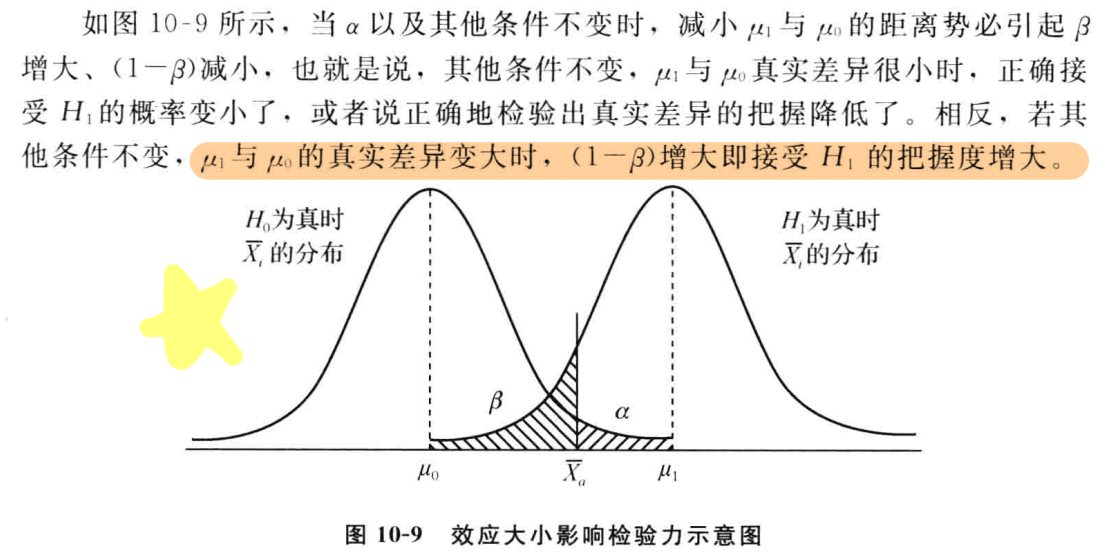
Significance Level: 即显著性水平, 当样本统计量在参数不变的条件下, 出现的概率低于α水平时, 我们就认为参数发生了变化, 拒绝虚无假设, 一般α水平取0.05 - 第一类错误
Type I Error: 拒绝了虚无假设, 但实际上参数没有变化, 即在参数不变的情况下, 真的发生了小概率事件, 发生概率等于 α - 第二类错误
Type II Error: 接受了虚无假设, 但实际上参数发生了变化, 即在参数变化的情况下, 发生了反向的小概率事件, 发生概率等于 β - 统计检验力
Power: 在参数变化时, 能够拒绝虚无假设的概率, 可以理解为检验的灵敏度, Power = 1 - β - 单侧检验
One-Tailed Test: 当备择假设是大于或小于时, 称为单侧检验 - 双侧检验
Two-Tailed Test: 当备择假设是不等于时, 称为双侧检验
α不是越小越好, α越小, 第一类错误发生的概率越小, 但第二类错误发生的概率越大


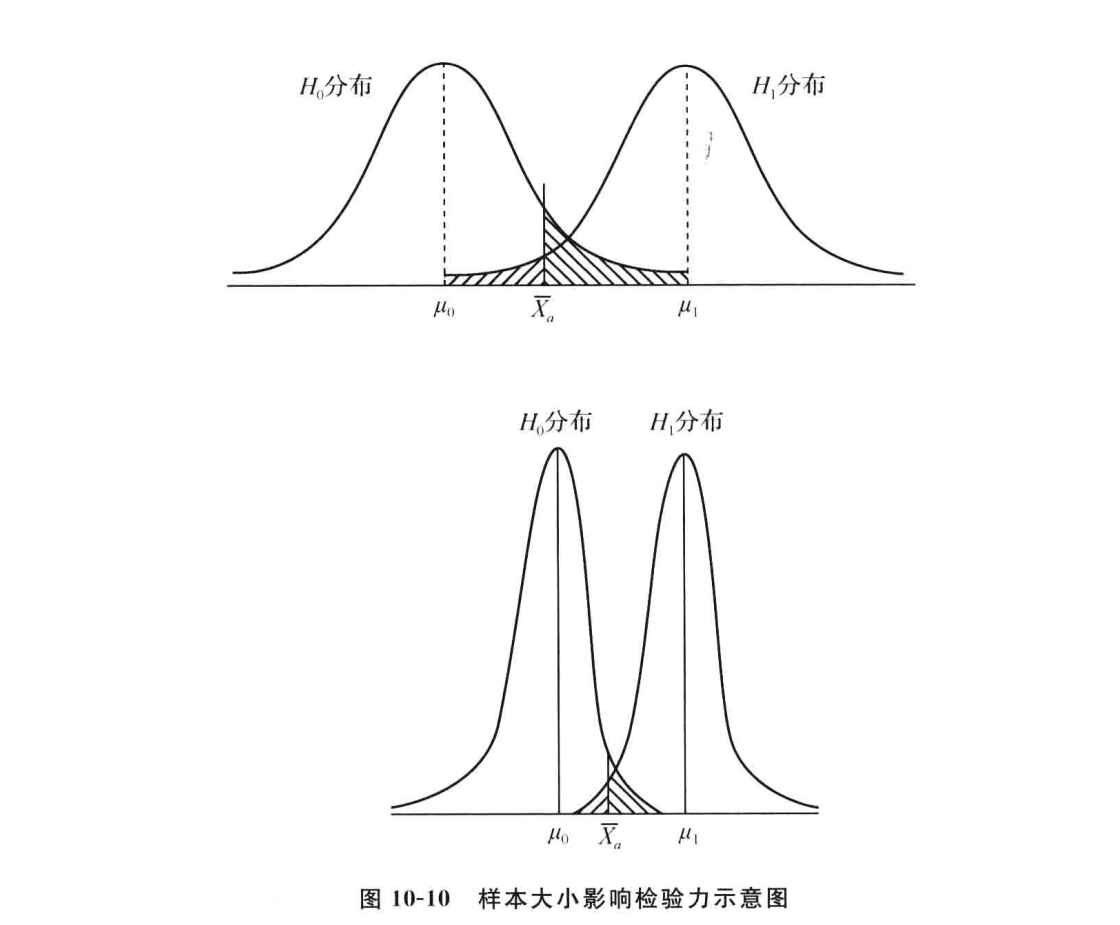

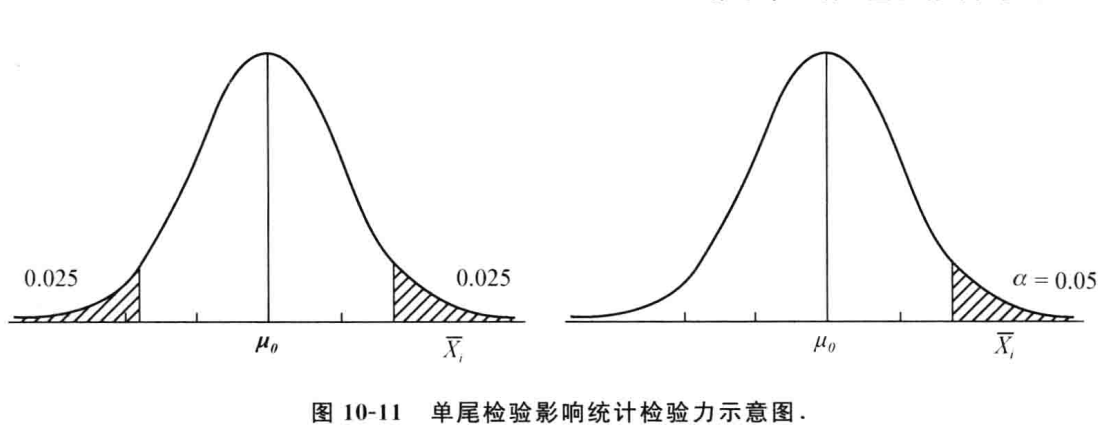
T检验
检验正态分布、大样本的数据的均值, 是否发生变化(单样本 / 重复测量)或互相不同(独立样本)的方法
独立样本T检验还应满足两个样本方差齐性, 相关内容将在方差分析中介绍
检验方法
| 检验方法 | 适用场景 | 计算方法 | 统计检验力 |
|---|---|---|---|
| 单样本T检验 | 通过样本均值, 检验一个样本所代表的总体的均值是否与指定的均值不同的方法 | 1. 计算样本标准差: S = √[ Σ(X - x̄)2 / (n - 1) ] 2. 计算估计标准误: Sx̄ = s / √n 3. 计算T值: T = (x̄ - μ) / Sx̄ 4. 查表得出T的临界值, 与结果比较 |
1. 计算δ值: δ = d · √n d 代表效应量, 见下文 2. 查表得出统计检验力 |
| 独立样本T检验 | 通过样本均值, 检验两个样本所代表的两个总体的均值是否不同的方法 | 1. 计算样本标准差: Sp = √[ (SS1 + SS2) / (df1 + df2) ] 2. 计算估计标准误: S(x̄1 - x̄2) = Sp √[ (1 / n1) + (1 / n2) ] 3. 计算T值: T = (x̄1 - x̄2) / S(x̄1 - x̄2) 4. 查表得出T的临界值, 与结果比较 |
1. 两组样本量相同: δ = d · √(n / 2) 2. 两组样本量不同: δ = d · √(nh / 2) nh = 2n1n2 / (n1 + n2) 3. 查表得出统计检验力 |
| 配对样本T检验 | 通过同一个样本两次测量的各自的均值, 检验样本所代表的总体的均值是否变化的方法 | 1. 计算差值: D = X1 - X2 d = x̄1 - x̄2 2. 计算样本标准差: SD = √[ Σ(D - d)2 / (n - 1) ] 3. 计算估计标准误: SD_ = SD / √n 4. 计算T值: T = (d - μ) / SD_ 5. 查表得出T的临界值, 与结果比较 |
1. 计算δ值: δ = d · √n 2. 查表得出统计检验力 |
效应量
通过上述的检验方法, 我们可以得出样本均值是否发生了变化, 但是我们并不知道变化的程度, 这时候就需要用到效应量
Cohen’s d 系数
Cohen’s d 系数是一种标准化的均值差, 用 d 表示
d = 均值差异 / 标准差, 对于独立样本T检验, 标准差按标准差合成公式计算
评价标准
| d值 | 效应量的大小 |
|---|---|
| 0 < d ≤ 0.2 | 小效应 |
| 0.2 < d ≤ 0.8 | 中等效应 |
| d > 0.8 | 大效应 |
测定系数 R2
表示测量分数的变异中, 由处理效应所引起的变异占了多大比例, 也即自变量的变化能在多大程度上解释因变量的变化, 用 R2 表示
R2 = t2 / (t2 + df), 其中 t2 代表T值的平方, df 代表自由度
另有: 非测定系数 = 1 - R2
评价标准
| R2值 | 效应量的大小 |
|---|---|
| 0.01 < R2 ≤ 0.09 | 小效应 |
| 0.09 < R2 ≤ 0.25 | 中等效应 |
| R2 > 0.25 | 大效应 |
参数估计
通过参数估计, 我们可以根据样本统计量, 估计出总体参数的范围
点估计
使用一个值来作为未知参数的估计, 例如用样本均值来作为总体均值的估计值
区间估计
使用一个区间, 以一定的概率来估计未知参数的范围, 例如用”样本均值 ± 1.96个标准误”来作为总体均值的估计范围
根据抽样分布的原理, ±1.96的标准误范围内, 有95%的概率包含了总体均值
- 置信度: 表示”参数位于置信区间中”的概率, 等于 1 - α, 一般取 0.95
- 置信区间: 某一置信度下, 未知参数的估计范围
- 样本量越大, 置信区间越窄, 估计越精确和准确
- 置信度越高
α水平越低, 置信区间越宽, 估计越不精确, 但越准确
用T统计量进行参数估计
| T检验类型 | 点估计 | 区间估计 |
|---|---|---|
| 单样本T检验 | x̄ | x̄ ± t · Sx̄ |
| 独立样本T检验 | x̄1 - x̄2 | (x̄1 - x̄2) ± t · S(x̄1 - x̄2) |
| 配对样本T检验 | d | d ± t · SD_ |
方差分析
检验正态分布、大样本、方差齐性的数据的均值, 是否发生变化(重复测量)或互相不同(单因素)的方法, 也称F检验
与T检验的区别在于, T检验只能检验两组数据的均值是否发生变化, 而方差分析可以检验多组数据的均值是否不全相同
基本逻辑
- 因素
Factor: 即自变量如年级 - 水平
Level: 即自变量的各个取值, 对于T检验, 自变量只有两个水平, 而对于方差分析, 自变量可以有多个水平如高年级、低年级(两个水平); 一年级、二年级、···、六年级(六个水平) - 虚无假设: 各组数据的均值相等, 即没有处理效应
- 备择假设: 各组数据的均值不全相等
不代表都不相等, 即存在处理效应 - 变异: 由处理效应或随机误差引起的数据的差异, 用方差表示
- F值: 方差分析的统计量, 等于”处理效应引起的变异”除以”随机误差引起的变异”
- 方差的可分解性: 上述”变异”通过方差体现, 而方差可以分解, 因此我们可以从可直接计算的方差来推算出不可直接计算的方差
- 处理间方差: 实验处理效应引起的方差; 各组数据的均值与总体均值的差异, 用 SSb 表示
- 处理内方差: 实验随机误差引起的方差; 各组数据的均值与各组数据的实际值的差异, 用 SSw 表示
- 总方差: 实验数据的方差; 各个数据与总体均值的差异, 用 SSt 表示
广义线性模型
将测验分数描述为总体均值、处理效应和随机误差的和, 即 X = μ + α + ε, 其中 X 代表测验分数, μ 代表总体均值, α 代表处理效应, ε 代表随机误差; 而方差分析就是广义线性模型的特例
方差齐性检验

测量效应
即差异的大小或差异有多大程度能被实验处理效应解释, 用 η2 指标或 Cohen’s f 系数表示, 二者可以相互转化
事后检验
当方差分析结果显著时, 我们只知道”各组数据的均值不全相等”, 但并不知道哪些组数据的均值不相等, 这时候就需要进行事后检验, 来确定哪些组数据的均值不相等; 常用的事后检验方法有 Bonferroni检验、Tukey HSD检验、Scheffe检验 等
具体类型
单因素方差分析
只包含一个自变量、每个被试只接受一个水平的实验设计; 可以得出”自变量的各水平的均值是否不全相等”的结论
重复测量方差分析
只包含一个自变量、每个被试接受所有水平的实验设计; 也可以得出”自变量的各水平的均值是否不全相等”的结论; 由于处理的顺序可能会影响结果, 需要通过拉丁方设计来消除影响
拉丁方设计示例
| 被试 | 第一次测量 | 第二次测量 | 第三次测量 | 第四次测量 |
|---|---|---|---|---|
| 1 | 水平A | 水平B | 水平C | 水平D |
| 2 | 水平B | 水平C | 水平D | 水平A |
| 3 | 水平C | 水平D | 水平A | 水平B |
| 4 | 水平D | 水平A | 水平B | 水平C |
相比于单因素方差分析, 重复测量方差分析控制了被试间的差异, 所以我们可以把 SSw 进一步分解为 SSsubject 和 SSerror, 在计算时使用 SSerror 代替 SSw 即可
两因素方差分析
包含两个自变量、每个被试只接受一个水平的实验设计; 可以得出”两个自变量的各水平的均值是否不全相等”的结论
- 主效应: 单个因素里, 自变量的变化对因变量的影响
- 交互效应: 两个因素的交互作用对因变量的影响
- 有主效应不一定有交互效应, 有交互效应不一定有主效应
- 虚无假设: 因素1没有主效应, 因素2没有主效应, 因素1和因素2没有交互效应
- 备择假设: 因素1有主效应, 因素2有主效应, 因素1和因素2有交互效应
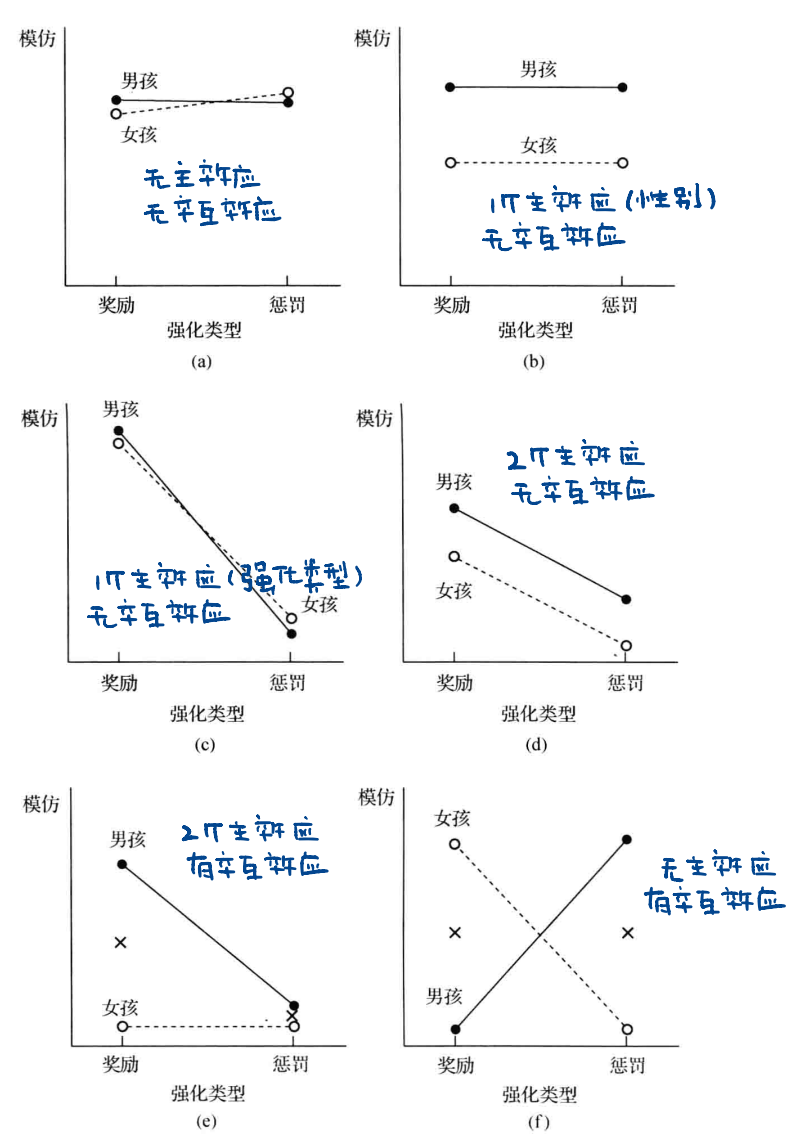
自由度
- 因素1的自由度为其因素数减1
- 因素2的自由度为其因素数减1
- 处理间自由度为二者因素数相乘再减1
- 交互效应自由度为处理间自由度减去前两者
简单效应检验
当交互效应显著时, 我们想要知道具体有怎样的交互效应, 这时候就需要进行简单效应检验; 简单效应检验可以得出”某一因素的主效应在另一个因素的哪一个/些水平上显著”
🚧 相关分析
皮尔逊相关
斯皮尔曼相关
肯德尔和谐系数
点二列相关
二列相关
Phi相关
🚧 回归分析
简单线性回归
多元线性回归
🚧 非参数检验
二项检验
卡方检验
K-S检验
U检验
中位数检验
Kruskal-Wallis H检验
符号检验
Wilcoxon符号秩检验
弗里德曼检验
中介效应
揭示变量间的关系是量化研究的一个重要目标. 中介 Mediation 效应分析能解释自变量 X 通过中介变量 M 影响因变量 Y 的过程. 例如 刺激-机体-反应 的过程, 其中 刺激 是自变量, 机体 是中介变量, 反应 是因变量
中介效应分析的历史相较于心理学的历史较短, 直到 20 世纪 80 年代, 才由 Baron & Kenny 提出具体的分析方法和模型. 而在中国, 直到 21 世纪初, 中介效应分析才被温忠麟老师等引入, 并迅速成为了国内心理统计学研究的热点之一
简单中介效应模型
对于标准化 消去截距项 的连续变量, 最简单的中介模型由一个自变量 X、一个因变量 Y 和一个中介变量 M 组成, 其结构方程模型如下:
| 数学模型 | 图示 |
|---|---|
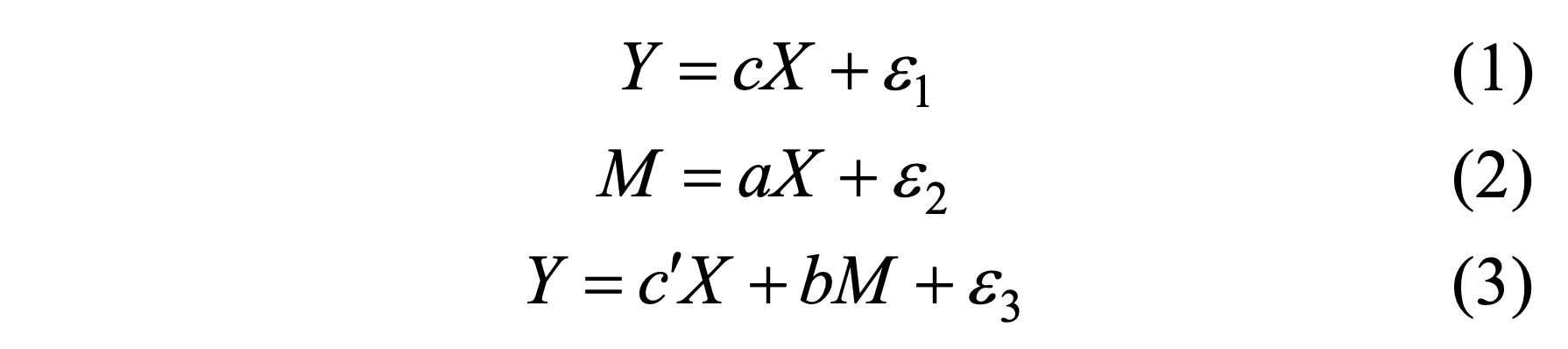 |
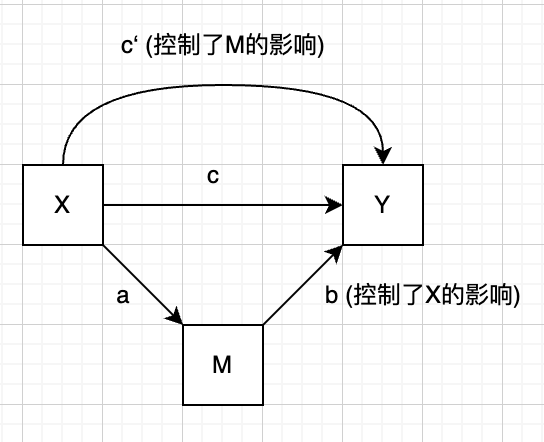 |
- 将
(2)代入(3)可得: Y = (c’ + ab)X + e2b + e3 c'为X对Y的直接效应: 即控制了M后X对Y的影响ab为X对Y的中介效应: 即X通过M对Y的影响c' + ab为X对Y的总效应: 即X对Y的总影响- 在没有其他变量影响的情况下,
c = c' + ab, 即X对Y的总效应等于直接效应与中介效应之和
相关概念
- 间接效应: 如果只有一个中介变量, 则中介效应
ab就是间接效应; 如果有多个中介变量, 则间接效应可以指所有或部分中介效应之和 - 遮掩效应: 如果
c'与c的符号相反, 且c'的绝对值大于c的绝对值, 则称存在遮掩效应; 也就是说,X对Y的影响被M遮掩了- 只有上面的方程
(1)中c(即X对Y的总效应) 显著, 才应进行中介效应分析, 研究X如何影响Y; 否则, 考虑遮掩效应分析, 研究X为什么不影响Y
- 只有上面的方程
- 完全中介效应: 如果
c'(直接效应) 不显著, 则称为完全中介效应 - 部分中介效应: 如果
c'(直接效应) 显著, 则称为部分中介效应- 但是有时候这种区分并不合适, 因为完全中介模型的中介作用不一定比部分中介模型的中介作用更强, 而且”完全中介”的概念阻碍了研究者继续探索其他可能的中介变量; 更合适的做法是直接报告
c'(直接效应) 和ab(中介效应) 的显著性
- 但是有时候这种区分并不合适, 因为完全中介模型的中介作用不一定比部分中介模型的中介作用更强, 而且”完全中介”的概念阻碍了研究者继续探索其他可能的中介变量; 更合适的做法是直接报告
检验方法
早起的中介效应检验方法可分为系数差异检验法 H0: c = c' 和系数乘积检验法 H0: ab = 0, 前者由于一类错误率过高而逐渐被淘汰. 以下是常用的中介效应的系数乘积检验法:
- 间接检验: 分别检验
a和b的显著性- 依次检验法: 分别检验
H0: a = 0和H0: b = 0, 从而得出真正的H0: ab = 0的结果; 依次检验法的检验力较低, 可能导致二类错误; 依次检验法还无法给出ab的置信区间 - 联合显著法与依次检验法检验过程相同, 有时会被混用. 但是联合显著法是为了得出
a != 0 且 b != 0的结论, 依次检验法是为了得出ab != 0的结论. 这带来的区别是联合显著法发生一类错误的概率更高
- 依次检验法: 分别检验
- 直接检验: 直接检验
ab的显著性- Sobel检验: 基于正态分布假设, 但由于
ab常常不服从正态分布, 故已极少使用 - 乘积分布法: 把
ab当作两个连续变量的乘积分布, 并据此得到ab的区间估计, 如果区间不包含0, 则认为ab显著; 该方法只需要a和b的估计值及其标准误, 无需原始数据; 详见方杰, 张敏强, 李晓鹏. (2011). 中介效应的三类区间估计方法. 心理科学进展, 19(5), 765–774. - Bootstrap法: 通过重复抽样, 计算
ab的置信区间, 如果区间不包含0, 则认为ab显著, 是最常用的方法- 参数Bootstrap法: 抽样的对象是参数 (如
a和b), 如 Monte Carlo 法 (MC法), 只需要a和b的估计值及其标准误, 无需原始数据; 详见方杰, 温忠麟. (2018a). 三类多层中介效应分析方法比较. 心理科学, 41(4), 962–967. - 非参数Bootstrap法: 抽样的对象是原始数据, 并根据样本计算
a和b的估计值, 从而得到ab的区间估计 - 偏差校正的Bootstrap法: 可以提高检验力, 但也会增加一类错误率, 仅在需要高检验力的情况下使用; 详见
方杰, 张敏强, 李晓鹏. (2011). 中介效应的三类区间估计方法. 心理科学进展, 19(5), 765–774.
- 参数Bootstrap法: 抽样的对象是参数 (如
- 贝叶斯法: 也叫马尔可夫链蒙特卡洛法 (MCMC), 这种方法的关键是选择合适的先验分布 (无法通过数据获得, 需要依赖研究者的主观判断或外部证据), 通过后验分布来得到
ab的区间估计, 如果区间不包含0, 则认为ab显著; 详见方杰, 张敏强, 李晓鹏. (2011). 中介效应的三类区间估计方法. 心理科学进展, 19(5), 765–774.
- Sobel检验: 基于正态分布假设, 但由于
这几种方法各有所长, 在实际应用中, 推荐先使用依次检验法, 如果
a和b不同时显著, 则使用Bootstrap法进行进一步检验; 如果需要报告中介效应的置信区间, 使用Bootstrap法 (但仍应了解a和b的显著性); 如果有合适的先验分布, 也可以使用贝叶斯法
效应量
- PM = ab / c: 中介效应占总效应的比例
- RM = ab / c’: 中介效应与直接效应之比
- κ2 = ab / abmax: 中介效应与中介效应最大可能值之比; 没有单调性, 不适合用作效应量
- R2med: 公式见下图, 表示方差只能被
X和M共同解释而不能被X或M单独解释的部分的比例; 没有单调性, 不适合用作效应量 - v = a2b2: 推导见下图; 虽然有单调性, 但还不如直接使用标准化的
ab, 也不适合用作效应量
建议当
ab与c符号一致时, 使用P<sub>M</sub>, 并报告ab的标准化估计值; 当ab与c符号不一致时, 没有合适的效应量推荐

非连续变量的中介效应检验
- 自变量为二分变量: 将其编码为
0和1再进行中介效应分析 - 自变量有多个类别: 采用虚拟变量法, 选择一个类别作为基准, 其他类别与基准进行比较; 详见
方杰, 温忠麟, 张敏强. (2017). 类别变量的中介效应分析. 心理科学, 40(2), 471–477. - 两水平被试内设计 (中介变量和因变量各重复测量两次)、自变量为二分变量、中介变量和因变量为连续变量: 详见
王阳, 温忠麟. (2018). 基于两水平被试内设计的中介效应分析方法. 心理科学, 41(5), 1233–1239. - 中介变量和/或因变量为分类变量: 详见
刘红云, 骆方, 张玉, 张丹慧. (2013). 因变量为等级变量 的中介效应分析. 心理学报, 45(12), 1431–1442.
纵向数据的中介效应检验
- 检验方法详见
刘国芳, 程亚华, 辛自强. (2018). 作为因果关系的中介效 应及其检验. 心理技术与应用, 6(11), 665–676. - 发展趋势:
- 考察随时间变化的中介效应
- 考察随个体变化的中介效应
- 中介模型的整合
- 使用Bootstrap和贝叶斯法进行纵向数据的中介分析
多重中介效应模型
有时候单个中介变量不足以描述一些复杂的情况, 这时候就需要多重中介模型 Multiple Mediation Modal, 它分为并行多重中介模型和链式多重中介模型
- 并行多重中介模型: 多个中介变量之间不相互影响
- 链式多重中介模型: 多个中介变量之间有影响关系
- 中介效应
- 特定路径的中介效应: 如
a1b1、a1a3b2(这种多个系数的乘积叫做链式中介效应) - 总的中介效应: 各个路径中介效应之和
- 对比中介效应: 某两个路径的中介效应差异 (都取绝对值)
- 特定路径的中介效应: 如
| 并行多重中介模型 | 链式多重中介模型 |
|---|---|
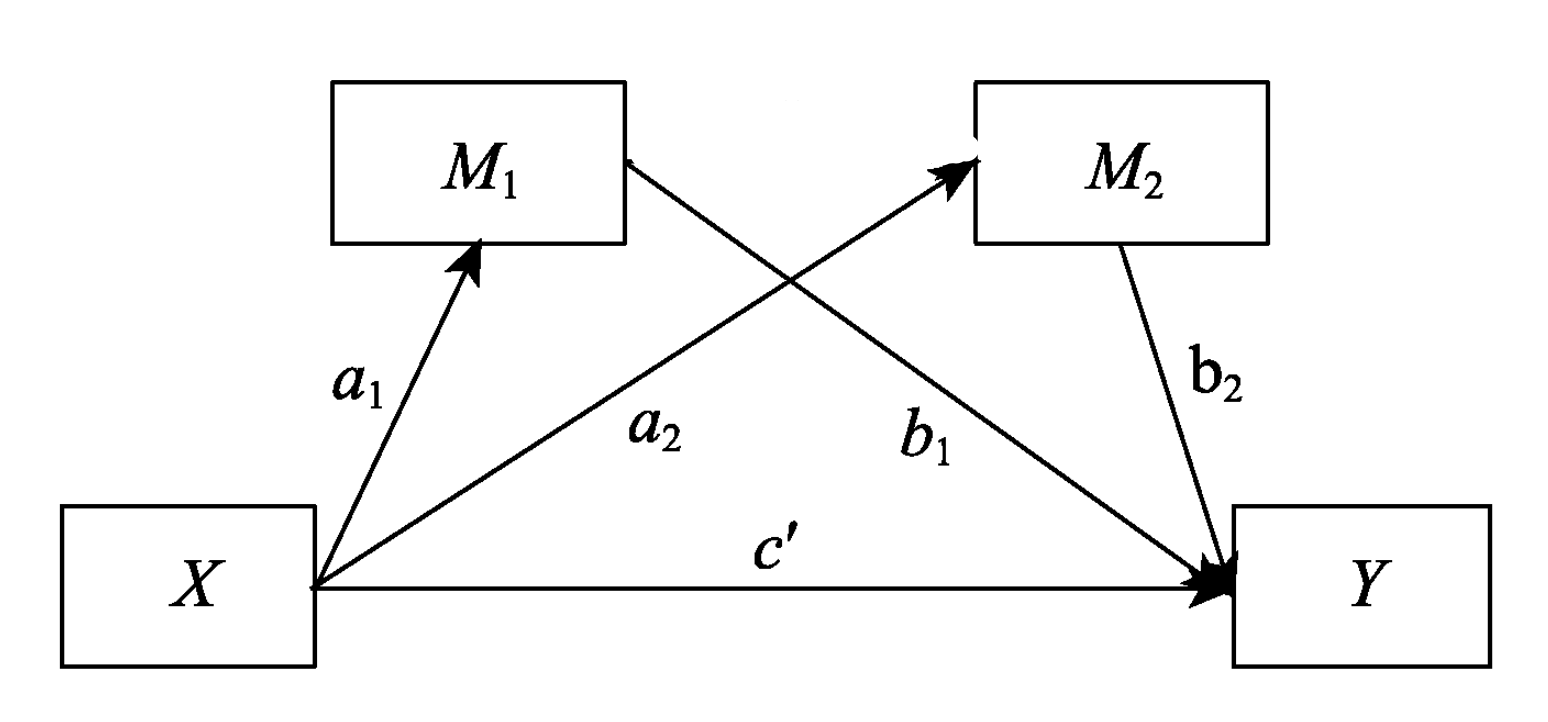 |
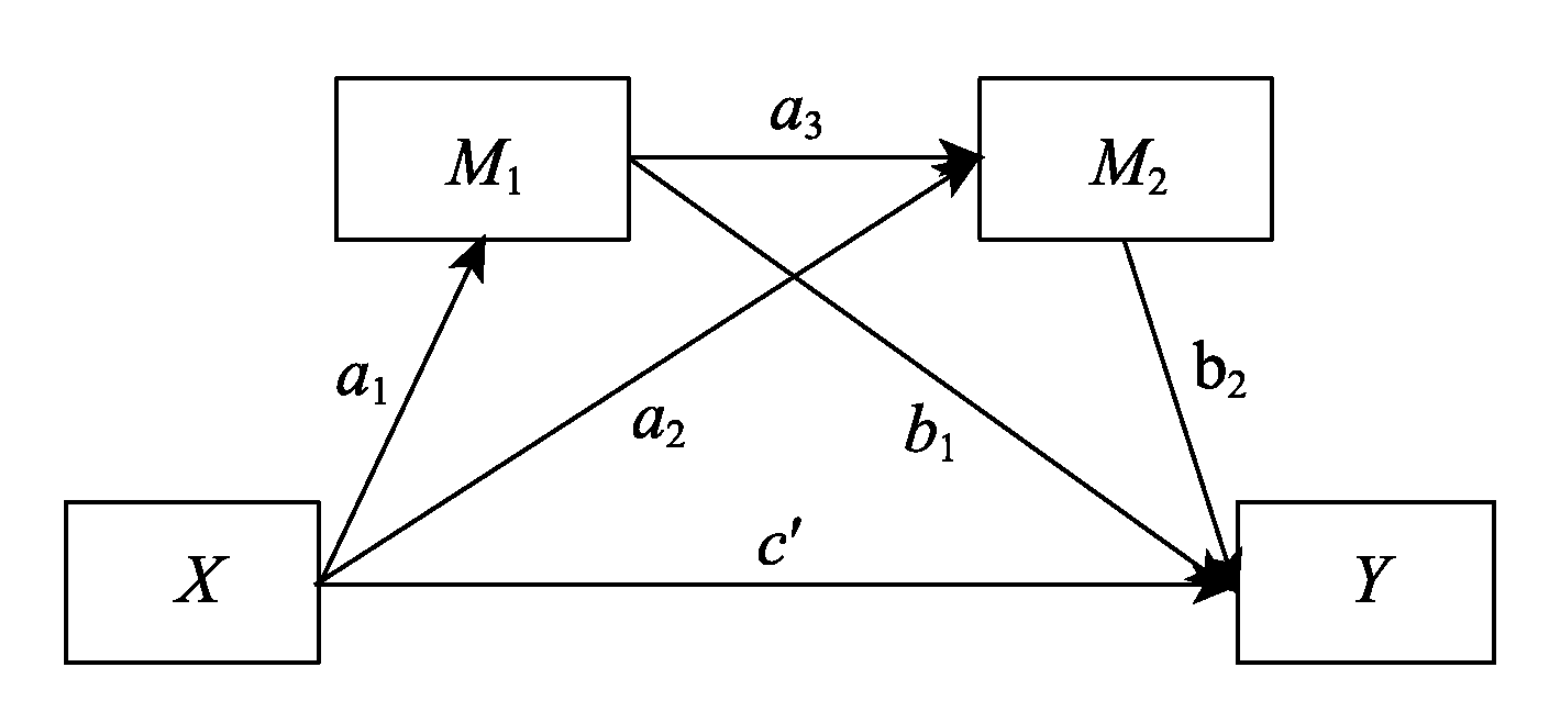 |
多层中介效应模型
多层(嵌套)数据在社会科学领域中经常出现, 如学生嵌套于班级; 这时多层数据之间不满足独立性条件, 需要引入多水平模型 Multilevel Model 分析中介效应
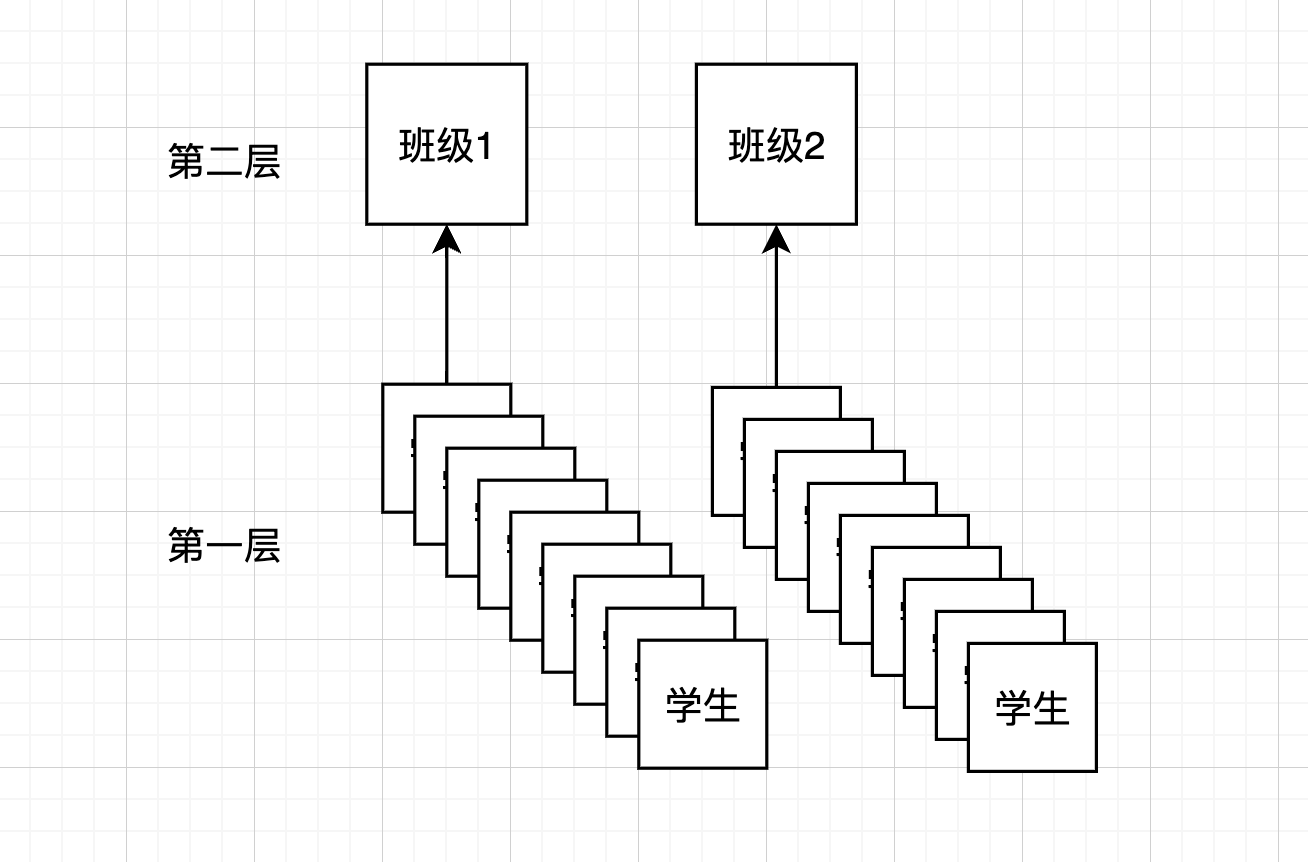
-
2-2-1模型:自变量(X)和中介变量(M)在群体层次(第2层),因变量(Y)在个体层次(第1层); 例如,班级管理风格(X)通过班级整体的学习氛围(M)影响个体学生的学习成绩(Y) -
2-1-1模型:自变量在群体层次(第2层),中介变量和因变量在个体层次(第1层); 例如,公司文化(X)通过个体工作满意度(M)影响个体工作表现(Y) -
1-1-1模型:自变量、中介变量和因变量都在个体层次,但个体嵌套在群体中; 此时,模型分析个体层次的中介效应,并允许效应在群体层次间有变异; 例如,个体的心理资本(X)通过自我效能感(M)影响工作表现(Y),但这些效应在不同公司之间可能有所不同
检验方法见
方杰, 张敏强, 邱皓政. (2010). 基于阶层线性理论的多层级中介效应. 心理科学进展, 18(8), 1329–1338.
有调节的中介模型
下面第一排是三种只调节中介效应的模型, 第二排是三种同时调节中介效应和直接效应的模型
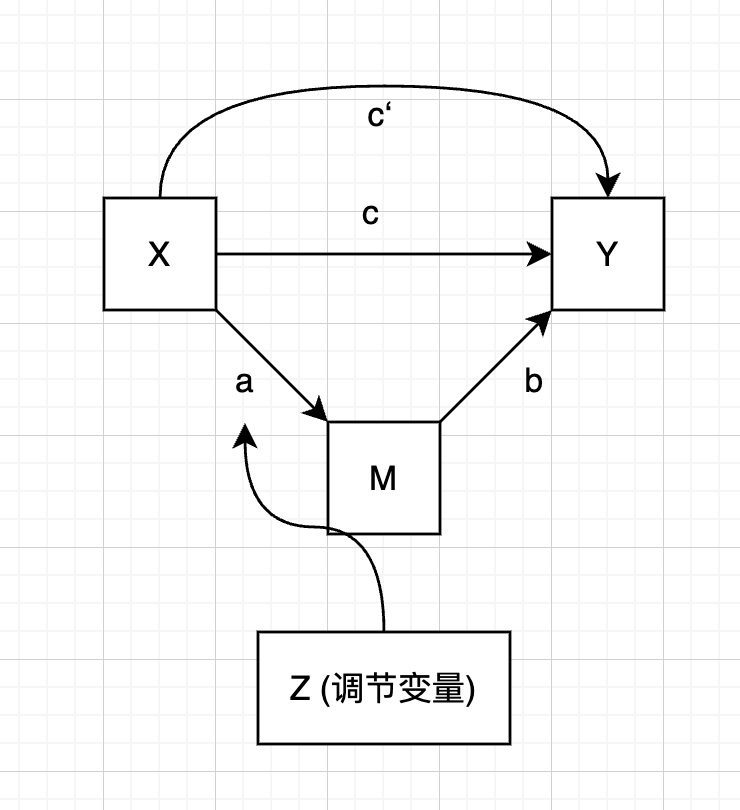 |
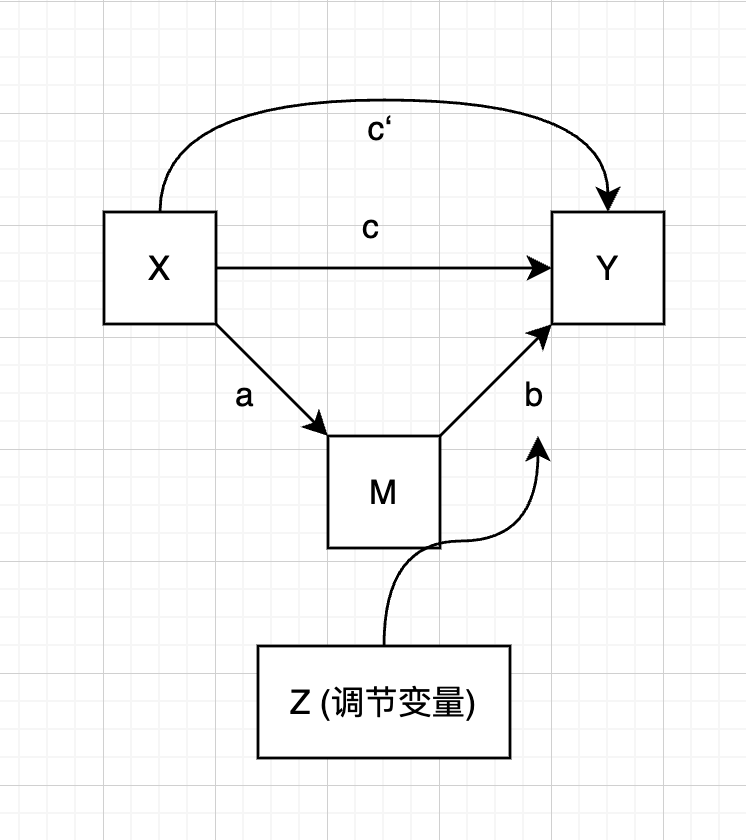 |
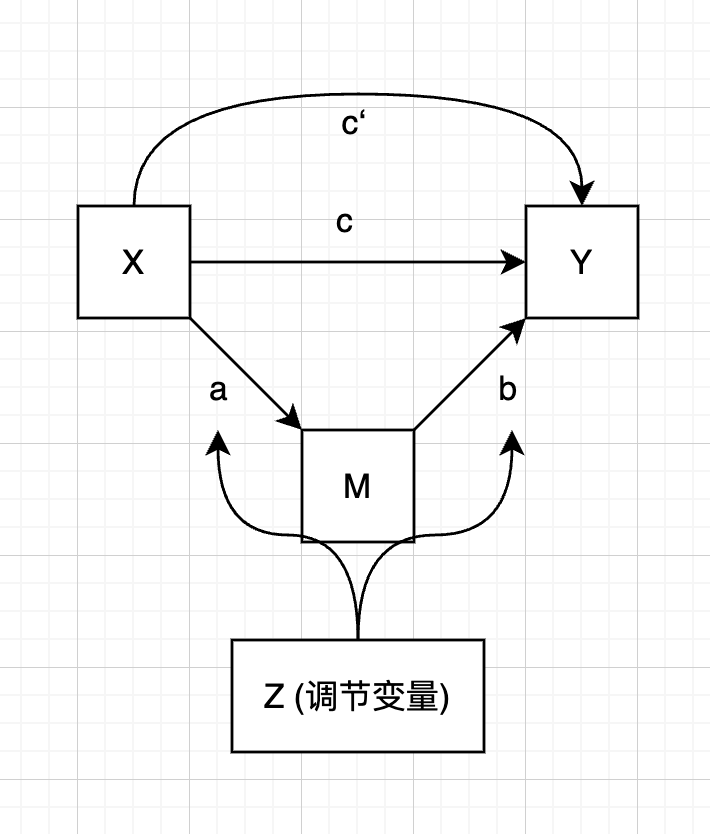 |
|---|---|---|
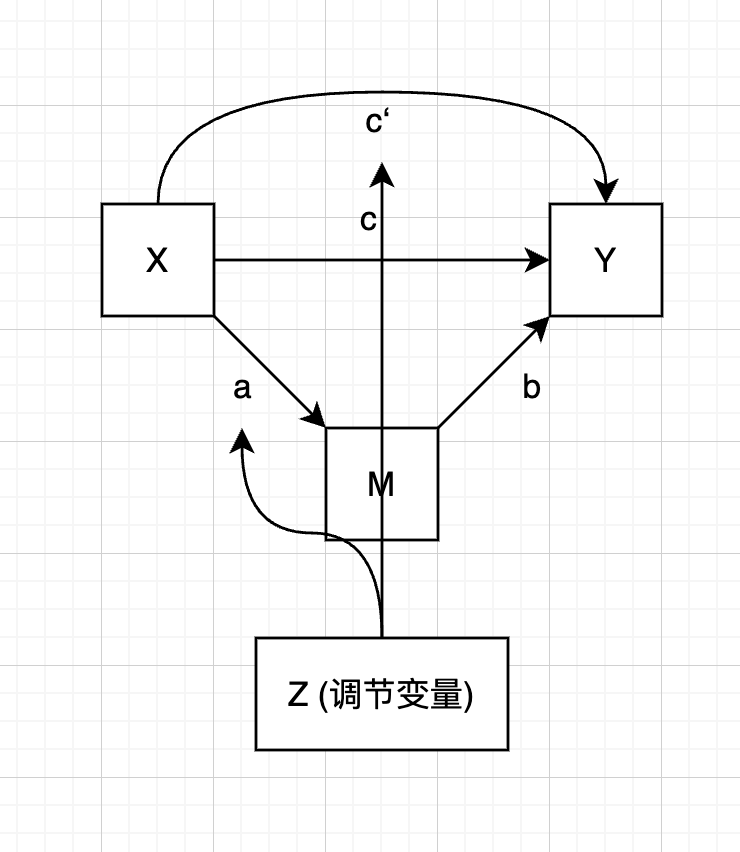 |
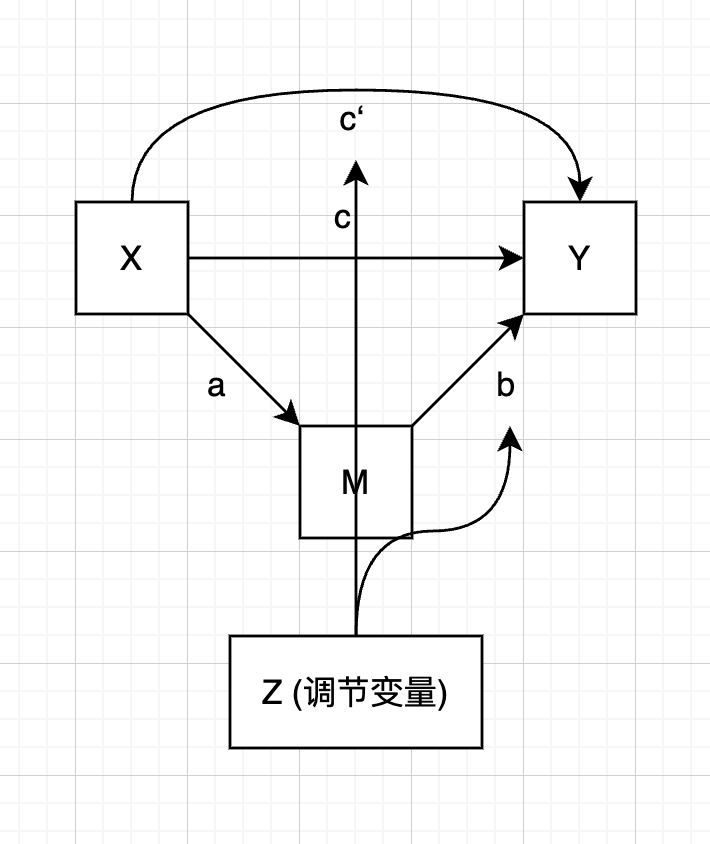 |
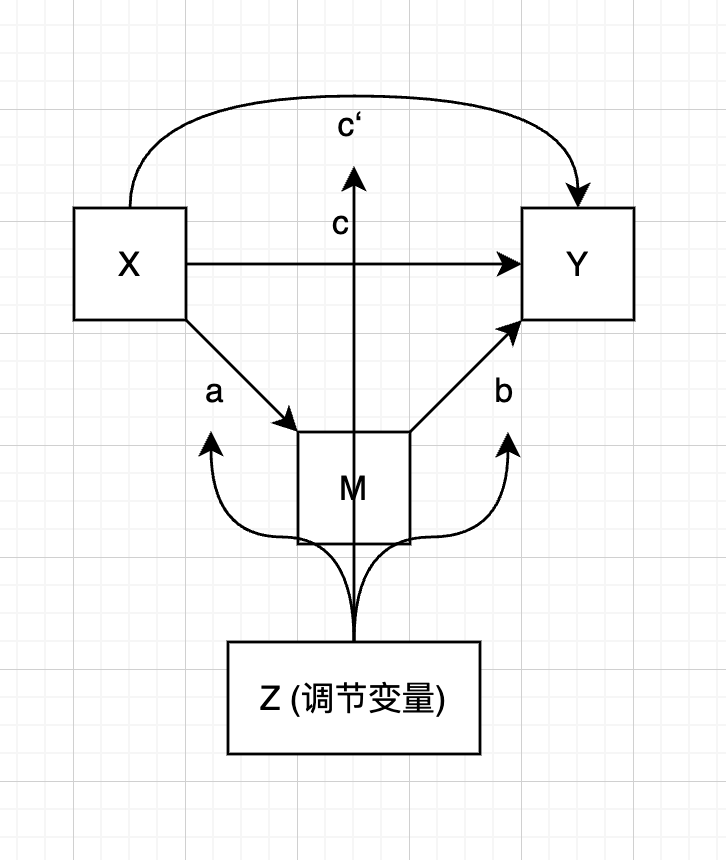 |
检验方法见
温忠麟, 叶宝娟. (2014b). 有调节的中介模型检验方法:竞争还是替补? 心理学报, 46(5), 714–726.
有中介的调节模型
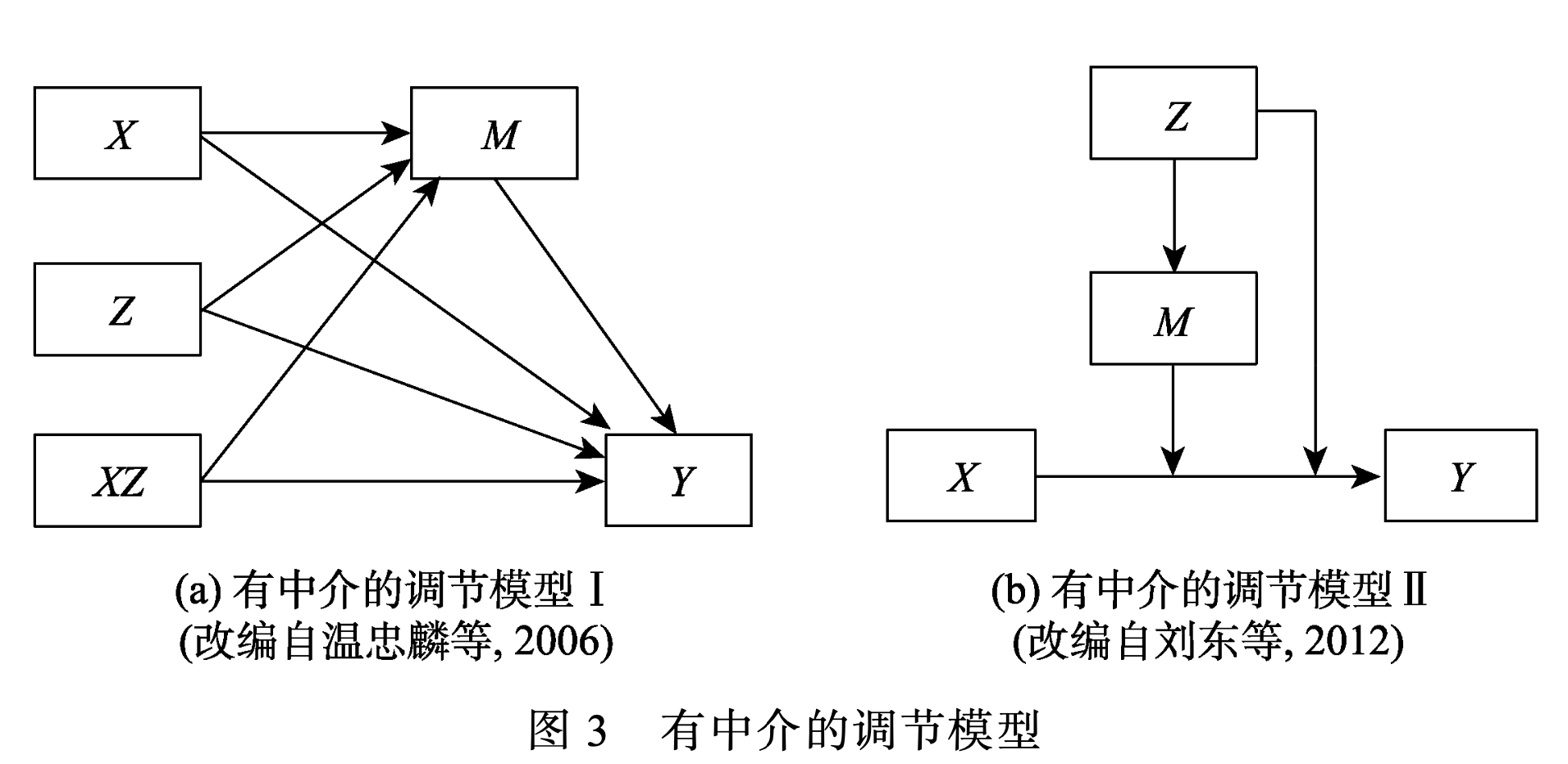
检验方法见
叶宝娟, 温忠麟. (2013). 有中介的调节模型检验方法: 甄别和整合. 心理学报, 45(9), 1050–1060.
混淆变量的控制
在中介效应分析中, 如果一个变量 T 即影响 M (T->M), 又影响 Y (T->Y), 则称为混淆变量; 混淆变量的存在会影响对 M->Y 的因果推断; 混淆变量分为前处理混淆变量和后处理混淆变量
- 前处理混淆变量: 混淆变量发生在实验处理
X之前, 可以假设其不受X的影响; 此种情况的检验详见Fritz, M. S., Kenny, D. A., & MacKinnon, D. P. (2016). The combined effects of measurement error and omitting confounders in the single mediator model. Multivariate Behavioral Research, 51(5), 681–697. - 后处理混淆变量: 混淆变量发生在实验处理
X之后, 其可能受X的影响; 此种情况下应把混淆变量当成新的中介变量进行分析, 即增加X->T->M、X->T->Y、X->T->M->Y三个路径
| 前处理混淆变量 | 后处理混淆变量 |
|---|---|
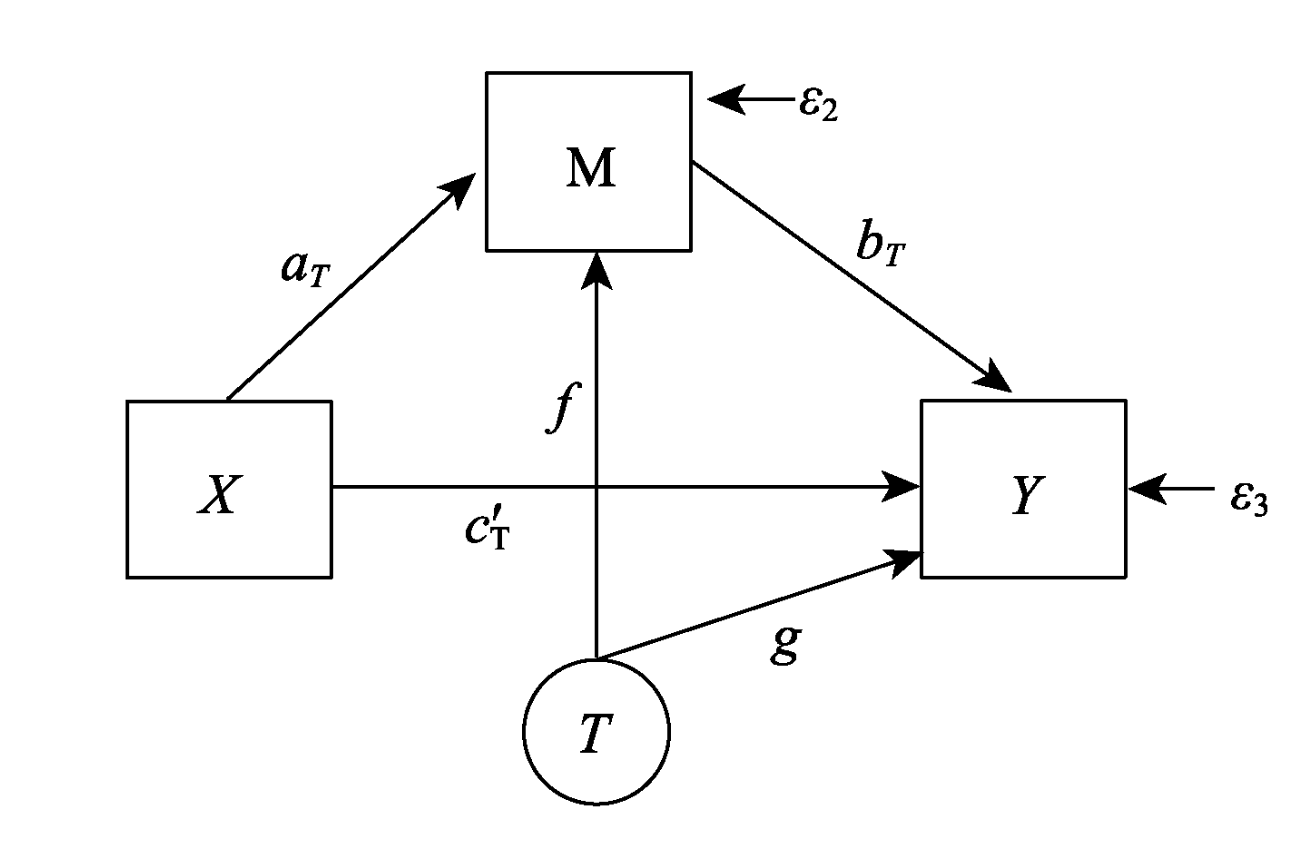 |
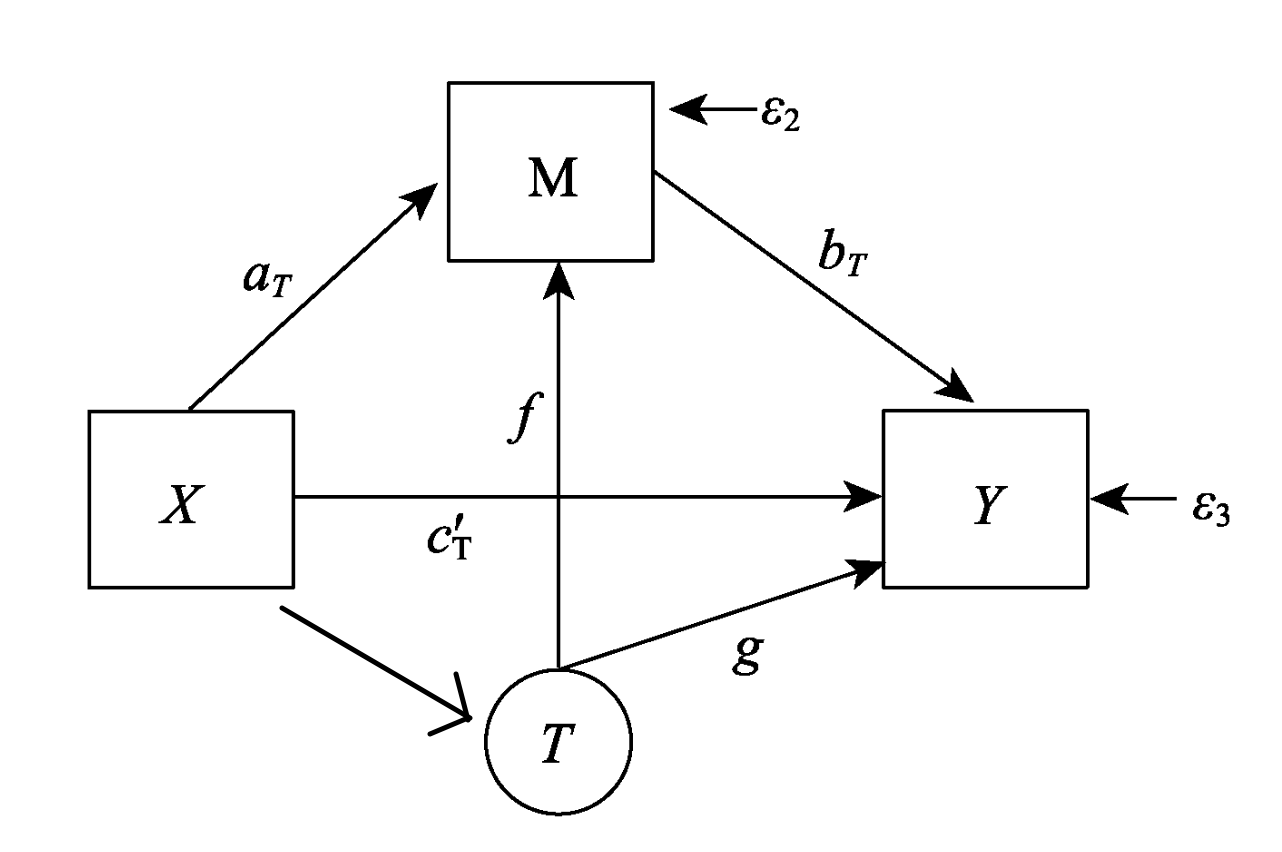 |
稳健中介分析
利用线性回归进行中介效应检验时, 线性回归需要满足残差同质 Homoscedastic 且正态的假设, 但实际上往往难以满足。稳健方法 Robust Method 可以缓解线性回归的中介分析中由于假设违背而造成的中介估计偏差; 检验方法包括:
- Robust M 估计法: 见
Zu, J., & Yuan, K.-H. (2010). Local influence and robust procedures for mediation analysis. Multivariate Behavioral Research, 45(1), 1–44. - 中数回归法: 见
Yuan, Y., & MacKinnon, D. P. (2014). Robust mediation analysis based on median regression. Psychological Methods, 19(1), 1–20. - Robust Bootstrap法: 见
Alfons, A., Ates, N. Y., & Groenen, P. J. F. (in press). A robust bootstrap test for mediation analysis. Organizational Research Methods.
中介效应的检验力分析
- 已知样本量、显著性水平
α、中介效应量, 求得检验力1-β; 此种分析也叫事后检验力分析, 意义不大 - 设定期望的检验力
1-β、显著性水平α、预估的中介效应量, 求得样本量
估计工具见
Schoemann, A. M., Boulton, A. J., & Short, S. D. (2017). Determining power and sample size for simple and complex mediation models. Social Psychological and Personality Science, 8(4), 379–386.
🚧 调节效应
矩阵基础
矩阵是一个矩形的数组, 由行和列组成, 表示为 m x n 的形式, 其中 m 代表行数, n 代表列数; 矩阵中的元素用小写字母表示, 如 a<sub>ij</sub> 表示第 i 行第 j 列的元素
- 多项式方程组的矩阵表示:
1
2
3
4
5
6
7
8// 多项式
3x + 4y + 5z = 10
2x + 3y + 4z = 5
x + y + z = 3
// 矩阵表示
| 3 4 5 | | x | | 10 |
| 2 3 4 | * | y | = | 5 |
| 1 1 1 | | z | | 3 | - 矩阵的加法和减法: 矩阵的加法和减法与数的加法和减法类似, 但是只有相同大小的矩阵才能相加或相减
1
2| 1 2 | | 3 4 | | 1+3 2+4 | | 4 6 |
| 5 6 | + | 7 8 | = | 5+7 6+8 | = | 12 14 | - 矩阵的乘法: 参考上面的多项式方程组的矩阵表示, 矩阵的乘法是将第一个矩阵的行与第二个矩阵的列相乘, 且第一个矩阵的列数必须等于第二个矩阵的行数
1
2| 1 2 | | 3 4 | | 1*3+2*7 1*4+2*8 | | 17 20 |
| 5 6 | * | 7 8 | = | 5*3+6*7 5*4+6*8 | = | 57 68 | - 单位矩阵: 对角线上的元素为
1, 其他元素为0, 用I表示; 单位矩阵的行数和列数相等、与任意矩阵相乘都等于原矩阵1
2
3| 1 0 0 | | 1 2 3 | | 1*1+0*4+0*7 1*2+0*5+0*8 1*3+0*6+0*9 | | 1 2 3 |
| 0 1 0 | * | 4 5 6 | = | 0*1+1*4+0*7 0*2+1*5+0*8 0*3+1*6+0*9 | = | 4 5 6 |
| 0 0 1 | | 7 8 9 | | 0*1+0*4+1*7 0*2+0*5+1*8 0*3+0*6+1*9 | | 7 8 9 | - 逆矩阵: 一个矩阵与其逆矩阵相乘等于单位矩阵, 用
A<sup>-1</sup>表示; 逆矩阵只有方阵即行数等于列数才有, 且行列式不为0的矩阵才有逆矩阵1
2| 1 2 | | 1 0 | | 1*1+2*0 1*0+2*1 | | 1 0 |
| 3 4 | * | 0 1 | = | 3*1+4*0 3*0+4*1 | = | 0 1 |
🚧 速查表
|差异检方法|样本大小要求|样本分布要求水平数|因素数|数据类型|备注|
|:—:|:—:|:—:|:—:|:—:|:—:|:—:|
|单样本T检验|||||||
|独立样本T检验|||||||
|配对样本T检验|||||||
|单因素方差分析|||||||
|重复测量方差分析|||||||
|两因素方差分析|||||||
|二项检验|||||||
|卡方检验|||||||
|K-S检验|||||||
|U检验|||||||
|中位数检验|||||||
|Kruskal-Wallis H检验|||||||
|符号检验|||||||
|Wilcoxon符号秩检验|||||||
|弗里德曼检验|||||||
| 相关分析方法 | 样本大小要求 | 样本分布要求 | 水平数 | 因素数 | 数据类型 | 备注 |
|---|---|---|---|---|---|---|
| 皮尔逊相关 | ||||||
| 斯皮尔曼相关 | ||||||
| 肯德尔和谐系数 | ||||||
| 点二列相关 | ||||||
| 二列相关 | ||||||
| Phi相关 |
- 标题: 心理统计学
- 作者: 小叶子
- 创建于 : 2024-01-08 16:09:47
- 更新于 : 2026-02-25 14:11:09
- 链接: https://blog.leafyee.xyz/2024/01/08/StatisticPsychology/
- 版权声明: 版权所有 © 小叶子,禁止转载。


