
心理测量学
封面作者:NOEYEBROW
本笔记源自北京师范大学黎坚老师本科课程 - 心理测量
⭐心理测量的性质与功能
基本概念
测量 / Measurement
根据一定的法则, 使用量具, 对事物的特征进行定量描述的过程
构念 / Construct
- 一种说明个体间差异的, 理论的、抽象的、概括性的性质或特征
- 无法直接观察到, 必须对其概念化
Conceptualization、操作化Operationalization后, 才有可能对不同个体给予不同分数即测量 - 对同一种构念有不同的测量方法, 但测量结果都必须与该种特质的理论解释相符合
心理测量 / Psychological Measurement
依据一定的心理学理论, 使用测验对人的心理特质 构念 进行定量描述的过程
前提假设
- 个体在能力倾向、思维、情绪、动机、行为等方面存在个体差异
- 这些构念虽不是物理实体, 但表现于外部行为, 因此是可度量的
- 心理测量的准确性、可靠性、精确性是逐步发展提高的
测量目标
心理学构念, 一种说明个体之间差异的, 理论的、抽象的性质或特质
量表 / Scale
测量的本质是根据某一法则将事物数量化, 即在一个定有单位和参照点的连续体上把事物的属性表现出来, 这个连续体称为量表
- 参照点: 确定事物量的计算起点
绝对零点/相对零点 - 单位: 种类多样, 即使测量同一事物属性, 也可采用不同单位
- 好的单位: 有确定的意义、有相同的价值
- 量表化
Scaling: 在测量中通过设置一定的法则来对事物的属性赋值的过程 - 根据量表的精确程度可将测量从低级到高级分成四种水平: 命名量表 → 顺序量表 → 等距量表 → 等比量表
心理测量学 / Psychometrics
研究教育和心理测量理论与技术 包括对知识、能力、态度、个性特征的测量, 主要关注测量工具的构建和验证 比如问卷、测试、个性评估, 涉及两个主要的研究任务: 测量工具和程序的构建、测量理论方法的发展和完善
心理测验法 / Psychological Testing
心理测量的一种具体方法和手段, 即依据心理学理论, 使用一定的操作程序, 通过观察人的少数有代表性的行为, 对于贯穿在人的全部行为活动中的心理特点做出推论和数量化分析的一种科学手段
除心理测验法外, 心理测量还包括观察法、访谈法、调查法、情景模拟法等
心理测验的特点和性质
间接性
- 实施心理测验的目的是测量人的行为, 但实际上仅能测量个体做测验的行为, 得到个体对测验题目的反应
- 利用心理测验测量个体差异时, 往往只是对少数经过慎重选择的行为样本进行观察, 来间接推知受测者的心理特征
行为样本 / Samples of Behavior
有代表性的某些行为 / 反应组成的样本, 但由于这些标准样本只能代表特定心理功能的一部分, 而不能反映该功能的全部, 因此难免存在某种程度的偏差
标准化
为了使不同的受测者所获得的分数有比较的可能性, 测验的条件对所有受测者都必须是相同的 即标准化的
- 题目: 对所有受测者施测相同的或等值的题目
- 施测过程: 施测说明、施测者的言语 / 态度、施测时的环境等的标准化
- 测验评分: 计分的原则和手续标准化, 必要时应举例说明, 使反应的量化客观
- 投射测验的客观性相对较差, 而问卷的客观性较好
- 分数转换和解释标准化, 对结果的推论应该是客观的
相对性
- 对人的行为做比较, 没有绝对的标准, 有的只是一个连续的行为序列
测验就是看每个人处在这个序列的什么位置上 - 受测者所得的原始分数没有实际意义
- 只有将所得分数与其他人的分数或常模相比较才有意义
- 严格地说, 心理量表是等级量表
心理测验的四度
难度、区分度、信度、效度, 是衡量一个测验是否科学的重要指标
心理测验的分类
| 按测量的目标 |
能力测验 Ability Test
|
人格测验 Personality Test
主要用于测量性格、气质、兴趣、态度等个性特点 |
| 按测量的方式 |
个体测验 Individual Test
|
团体测验 Group Test
|
| 按测量的要求 |
最高作为测验 Maximal Performance Test
|
典型行为测验 Typical Performance Test
|
| 按评价所参照的标准 |
常模参照测验 Norm-referenced Test
将被试水平与常模相比较, 以评价被试在团体中的相对地位为目的 |
标准参照测验 Criterion-referenced Test
将被试水平与一绝对标准相比较, 以评价被试是否达到该标准 |
| 按测验材料的性质 |
文字测验 Verbal Test
所用测验材料是文字, 受测者用文字作答 |
非文字测验 Nonverbal Test / 操作测验
|
| 按测验材料的严谨程度 |
客观测验 Objective Test
|
投射测验 Projective Test
|
| 按测验难度和时限 |
速度测验 Speed Test
题目数量多, 并严格限制时间, 主要测量反应速度 |
难度测验 Power Test
包含各种不同难度的题目, 由易到难排列, 测量被试解答难题的最高能力 |
| 按测量的应用领域 |
教育测验 Educational
是测验应用最广的领域, 其中用得最多的是学绩测验 |
职业测验 Vocational
主要用于人员选拔和安置, 可以用能力和学绩测验, 也可以用人格测验 |
临床测验 Clinical
主要用于医务部门, 许多能力和人格测验可用来检查智力障碍或精神疾病, 为临床诊断和心理咨询工作服务 |
心理测验的功能和应用
科学的心理测验观
- 心理测验是有局限的
- 限于目前的技术方法, 仍存在误差
- 某些人格测验可能侵犯个人隐私
- 测验结果可能为偏见与歧视提供依据
- 心理测验是继实验法后, 心理学研究中不可缺少的重要研究方法
- 心理测验是实践决策中的重要辅助工具
心理测验的主要功能
- 描述: 对个人 / 团体的能力、性格、兴趣、学业成就等进行描述和评价
- 诊断: 在临床上诊断各种智能缺陷、精神疾病、学生的学习障碍
- 选拔: 由于心理测验可以预测人们从事各种活动的适宜性, 通过心理测验选拔出来的人才往往比凭借个人的经验选拔出来的人才更可信也更有效
- 安置: 通过测验将人才分门别类, 筛选出各个岗位最适当的人员, 安排至最适当的位置
心理测验的历史
中国古代心理测量思想及实践
发展历程
- 商周时代把礼、乐、射、御、书、数等六艺作为选拔人才的标准, “乐、射、御”即非文字的单项特殊能力测试
- 春秋孔子通过观察把学生分为中人、中人以上、中人以下, 认为”中人以上可以语上也, 中人以下不可语上也”
- 战国孟子提出”权, 然后知轻重; 度, 然后知短长。物皆然, 心为甚”
- 汉代则把笔试法律、军事、农业、税收和地理等五项内容作为选拔人才的标准
- 三国诸葛亮:”问之以是非而观其志, 穷之以词辩而观其变, 咨之以计谋而观其识, 告之以祸难而观其勇, 醉之以酒而观其性, 临之以利而观其廉, 期之以事而观其信”
- 三国刘劭著《人物志》, 提出 “八观与五视”的观察方法, 从人的体貌、言语、行为等诸多方面对人进行观察, 从而将人判定为不同类别, 实质上遵循的是客观测量的原则
- 隋炀帝
606年始置进士科, 是科举制度的开端, 经隋唐宋元明至清代, 科 举制度已相当成熟; 科举考试中的帖经填补词句中的缺字和对偶, 类似于现代言语测验中的填空题
19世纪科举制度传入欧洲后, 很受西方新兴资产阶级的欢迎, 并用于他们的文官考试
民间的测量实践
- 除了官方推行规模宏大的有组织的测量活动之外, 民间自发的测量活动也是形式多样
- 刘勰在《新论·专学篇》中提到”使左手画方, 右手画圆, 无一时俱成”, 其原因是”由心不两用, 则手不并用也”
中国传统心理测量的特点
- 测验方法和形式多样
- 心理测量思想是描述性的, 非定量的
- 测量结果是分类式, 按照能力、性格把人分为不同类型
- 注重对人进行整体的评鉴, 倾向于与道德品质相联系
- 测量思想与因材施教和人才使用密切联系
科学心理测量的诞生与发展
在心理测量领域, 19世纪80年代是高尔顿的十年, 90年代是卡特尔的十年, 20世纪头十年则是比奈的智力测验的十年
—— 波林E.G.Boring
高尔顿 / F. Galton
- 英国生物学家和心理学家, 首先倡导科学心理测验
- 人的气质特点、智能是按身体特点的不同而遗传的
- 为了研究遗传的差异性而设计了测量个体智力差异的方法
但不是正式的测验 - 第一个提出了相关的概念
卡特尔 / J. M. Cattell
- 美国心理学家
- 1890年, 在《心理》杂志上发表《心理测验与测量》一文, 是心理测验
Mental Test第一次出现在心理学文献中 - 文章内容是描述其自编的感觉运动测验
比奈 / A. Binet
- 20世纪初, 法国心理学家比奈为了辨别智力落后儿童, 与助手西蒙合作, 1905年在《心理学年报》上发表《诊断异常儿童智力的新方法》, 介绍了比奈-西蒙智力量表
第一个智力测验 - 虽然该量表只有30个题目, 却是世界上第一个正式的心理测验, 是心理测验史上的一个创新
西方心理测验的蓬勃发展与应用
- 编制出了一批操作测验, 弥补了语言文字量表在理论上的缺陷
- 编制出团体智力测验, 扩大了测验的应用范围
- 能力倾向测验的发展: 韦氏测验、GATB
- 传统的学校考试方法也取得了技术上的突破
- 编制人际关系、动机、兴趣、态度等人格测验
⭐测验的编制
确定测验目的
明确测验的对象
了解团体的组成和特点: 年龄、智力水平、社会经济和文化背景、阅读水平等
明确测验的用途
测验用于描述、诊断、预测、选拔还是安置
确定测验的目标
- 测验将用于测量什么心理构想或行为表现
例如目标是测量学业成就、智力、特殊能力倾向, 还是人格 - 首先对所要测量的心理构想进行概念界定
概念化 - 然后说明该构想所包含的内容或维度将通过什么行为表现出来或怎样进行测量
操作化
测验编制计划
- 测验目标确定后, 需要进一步制定编制计划, 列出测量内容大纲
- 不同测验的编制计划, 其重点不同
用于招聘选拔的测验重视收集工作分析资料, 智力测验注重理论基础或者选取实证效标, 成就测验需要明确测验的内容范围
确定编制计划的方法
- 回顾以往研究成果
- 考虑时代的特点
- 了解受测群体实际情况
- 向有关专家 / 资深者咨询和请教
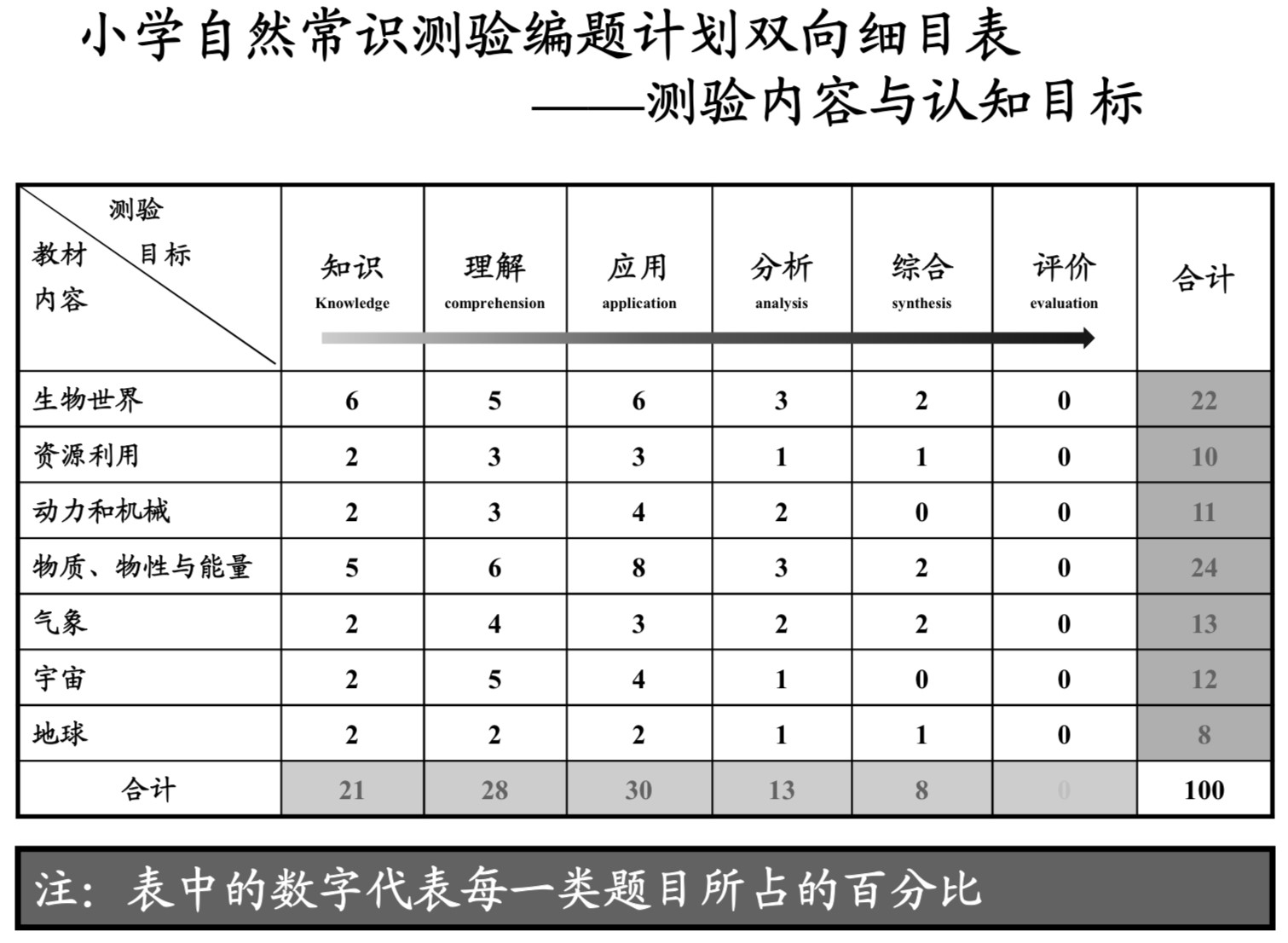
例: 成就测验的编制计划
确定能表征测量目标的内容或技能范围, 并制定各部分比例, 以便行为取样, 例如:
- 测验内容与测验目标或题型之间关系的双向细目表
- 题型与难度、测验内容之间关系的双向细目表

项目的编制
收集资料
- 为编制测验而搜集的资料应当内容丰富, 覆盖面广, 代表性强, 并带有一定趣味性
- 来源包括: 已出版的标准测验, 理论和专家的经验, 临床观察和记录
命题的一般原则
- 内容方面: 题目的内容符合测验目的、内容取样有代表性、题目间内容相互独立, 互不牵连
- 文字方面: 使用当代语言、语句简明扼要、最好一句话说明一个概念、尽量不用双重否定句
- 理解方面: 题目应有确切的答案
但不能有答题倾向线索、题目的内容不要超出受测团体的知识水平和理解能力、题目格式要容易理解 - 社会敏感性方面: 尽量避开社会敏感问题
如涉及社会禁忌或个人隐私的题目不应使用
若必须涉及敏感问题 性、犯罪、自杀等
- 命题时假定受测者具有某种行为, 使其不得不在确实没有该行为时才否定, 可避免否定过多的倾向
- 命题时假定规范不一致
- 指出该行为是常见的, 虽然是违规或违法的
- 随机反应技术
Random Response Technique, RRT
确定项目的形式
根据对受测者的要求分类
- 选择型题目
Selected-response Format: 要求受测者在有限的几个答案中选择正确的答案如选择题、是否题、匹配题 - 构造型题目
Constructed-response Format: 要求受测者自己给出正确答案如论文题、简答题、填充题
根据评分的客观性分类
- 客观题
Objective Test: 把受测者的反应与事先定好的正确答案相比较, 评分有很强的客观性, 不同评分者结果一致既可以是构造型也可以是选择型 - 论述题
Essay Test: 要求受测者针对题目写出相当长的答案, 然后由教师或其他评价者对这些答案进行主观评定论述题都属于构造型题目
具体题目类型
判断题 / 是非题 / 正误题
向受测者提供一个陈述句, 让受测者判断它正确与否, 做出是 / 否、正确 / 错误的判断
- 应绝对正确或错误
- 测量重要的而不是细节性的问题
- 一题只包含一个概念
- 避免反面叙述, 尤其是双重否定
- 避免含混不确定的描述
- 避免使用限定词或暗示性的词汇
- 一般是与非的题数应该相等, 且随机排列
评定量表 / Rating Scale
- 要求受测者对一系列陈述句表示看法
- 有程度的区分, 通常该尺度有5或7点
- 了解受测者的习惯、态度、兴趣等
选择题 / Multiple-choice Item
- 由题干
Stem和选项Alternatives两部分组成 - 题干可以是不完全陈述句, 也可是直接疑问句
- 选项包含一个或几个正确的答案以及若干错误答案
诱答 - 通过分析受测者选择的诱答项目, 可以获得有用的诊断信息
编制原则
- 选项之间相互独立, 避免逻辑上的包含关系
有时需要列出"其它"选项 - 题干的表达要简洁、明确, 适合受测者的文化程度
- 选项一般4个或5个为宜, 各选项长度尽量相等
- 正确答案的顺序要随机排列在各个位置上, 次数大致相等
- 选项要简短、干练
每个选项中都重复遇到的字词放到题干中 - 若是找最合适答案, 应强调”哪个答案最合适”
- 选项的形式统一
例如都是人名、时间等 - 少用诸如”以上都不对” / “以上都对”的选项
诱答的编制方法
- 应阐明不知道正解的受测者会选择该诱答的理由
- 使用最常见的错误
- 能反映出受测者缺乏某种知识或技能
- 使用那些在口语中与题干相联系的词
- 大众认可但实际错误的概念或者部分正确的句子
- 使用书面语言或者其他具有真理性的措辞
- 诱答在内容上与正解同质或者相似
- 诱答与正解在长度 / 结构 / 内容的复杂度上相似
匹配题 / Matching Item
- 分左右两列呈现前提条件
Premise和反应选项Response, 要求受测者以最佳方式将两者对应关联起来 - 儿童可以划线连接, 成人可以直接标注编号
- 反应选项的数量应该多于前提条件数量
以避免受测者的猜测, 或在指导语中声明”每个反应选项可能对应多个 / 单个 / 零个前提条件” - 注意: 每个前提条件只能对应一个反应选项
排序题 / Rearrangement Item
- 受测者需要按照事先确定的固定类别重新排列一组选项
- 匹配题和排序题也属于另一种形式的选择题
填空题 / Completion Item 和 简答题 / Short-answer Item
- 让受测者对用直接疑问句表述的问题用几个字
填空题或几句话简答题进行回答 - 不适合测量复杂的教育目标
- 可能存在一个以上的正确答案
因此评分并非完全客观
编制原则
- 宜用问句, 若为填空, 空格尽量在句尾
- 对不完整的答案, 应事先规定评分标准
- 若为填空, 一题的空不宜过多, 且需填答的内容应该是关键词句
- 答案要明确、唯一、简短、具体
- 题目要对答案范围加以明确限制
例如指明数字型答案的单位, 但不能给予提示
论述题 / Essay Type Test Item
- 包括论述题和作文题
- 能对受测者的知识、能力进行全面考察
- 能测量高层次的认知目标, 考查受测者的整体能力
优点
- 答案能够反映考生解答问题的思维过程
- 可以促使受测者重视所有知识之间的内在联系
- 编题花费的时间较少
- 减少受测者仅靠猜测答对的可能性
不足
- 评分缺乏客观性
- 对整个教育内容的取样缺乏广泛的代表性
- 易高估擅长言辞但学科知识贫乏者的实力
- 阅卷时费时费力
编制原则
- 能不用, 则不用
- 若用, 出”活题”
- 不出脱离考试的范围和要求的”偏题” / “怪题”
- 所有受测者接受同样的论文题, 没有选择作答的机会
- 一个论文题所占比重适当, 不宜太小, 也不宜太大
- 编制题目的同时, 制定明细合理的评分标准
操作题
- 让受测者进行实际操作
如画图、走迷津、装配物体等 - 介于纸笔测验和实际活动评价之间
编制原则
- 明确测量目标并将其操作化
- 选择真实性程度高的项目
- 指导语要简明扼要
- 制定评分细则和计分方法
测验的编排和组织
合成测验
选择试题形式
- 考虑测验的目的和材料的性质
再认/回忆/综合 - 考虑接受测验的团体的特点
对有言语缺陷的人尽量采用操作测验 - 考虑各种实际因素
个体/团体
审定题目
- 既要自审又要他人审
- 各类题目比例是否适当
应与双向细目表的计划一致 - 题目是否表述清楚
- 题目是否适合施测对象和施测条件
- 难度和区分度是否恰当
要结合测验用途 - 题目是否相互独立, 有无重叠题目
- 题目数量应为最终题本的2倍或更多, 以备筛选和编制复本
测题的编排
基本原则
- 难度排列应由易到难
- 同类型的题目放在一起, 统一说明
- 根据题型本身特点调整排列顺序
常见的排列方式
- 并列-直进式: 按题目的性质归为若干个分测验, 在同一分测验内部按题目难度由易到难排列
- 混合螺旋式: 将各种类型的题目按难度划分为若干个层次, 然后将同等难度、不同性质、不同类型的题目组合在一起, 再按难度水平从易到难排列
预测
- 目的在于获得受测者对题目如何反应的资料, 发现未曾设想的情况
例如题意不清或引起误解 - 预测对象来自正式测验准备应用的群体
- 预测的施测过程与情境应接近正式测试
- 时限可以稍宽, 使每个受测者都能做完
- 随时记录受测者的反应情形
项目分析
- 难度、区分度、选项分析
- 为了保证项目分析的准确性, 在一次项目分析, 项目修订后, 应取来自同一总体的另一样本再测一次, 并进行第二次项目分析, 比较两次结果是否一致
测验的标准化
测验内容标准化
- 对所有受测者施测相同或等值的项目
- 测验内容不同, 所得结果的比较没有意义
施测过程标准化
- 相同的测验情境: 统一采光、桌椅、布置等, 防止噪音和无关人员的干扰
- 相同的指导语: 测验目的、如何作答, 不常见的题型需要提供例题
- 相同的测验时限: 一般设定为预测时90%的受测者完成全部项目的时间
人格测验相对宽松, 能力测验时限严格
测验计分标准化
对于客观题
- 要及时而清楚地记录反应情况
- 要有一张记录正确反应的表格
即记分键/Scoring Key/Scoring Stencil - 将受测者的反应和记分键比较, 对反应进行分类
对于主观题
两个或多个评分者的评定应一致 一般要求相关系数达到0.9以上
测验分数解释标准化
- 必要性: 如果同一个分数可做出不同的推论, 测量便失去了客观性
- 原始分数本身无意义, 需要建立参照系统
例如常模参照 - 将原始分转换为导出分数
例如百分位常模、标准分常模等, 并严格根据要求对测验结果进行解释
测验鉴定和使用说明
信效度检验
- 可先在小范围试用, 考察信效度
- 初步确定可用后再进行大范围施测, 检验信效度
- 信度和效度的评估方法多样, 具体应根据测量的性质和目的而定
编写测验说明书
- 测验的目的和功用
- 测验编制的理论背景以及测验中的材料是根据什么原则、应用什么方法选择出来的, 许多手册还提供选择题目的统计指标
- 如何实施测验的说明
- 测验的标准答案和计分标准
- 常模资料, 包括常模表、常模适用的团体及对测验分数如何做解释
- 测验的基本特征, 包括难度、区分度、信度、效度和因素分析的资料, 以及这些资料取得的条件和情境, 包括调查的样本和时间
⭐项目分析
对于某个项目 即试题, 我们主要关注难度和区分度; 对于整个测验, 我们主要关注信度和效度
项目难度
Item Difficulty
难度的计算
二分法计分的项目
 |
 |
非二分法计分的项目
P = (全体受测者平均分 / 试题满分) x 100%
难度水平的确定
从测量目的考虑
- 测量是为了取得个体间的差异, 因此平均难度接近0.5最能把不同的人区分开
- 若题目对要考察的内容范围有良好的代表性, 即使通过率很高或很低也应该保留下来
- 若题目相对要考察的内容范围不具备很好的代表性, 即使中等通过率的题目也应修改或删除
从测量作用考虑
对于选拔用的人事测量, 难度应接近录取率
从分数的分布考虑
- 结果为正偏态分布时, 说明测验对研究样本来说偏难
- 结果为负偏态分布时, 说明测验对研究样本来说偏易
- 但是标准参照测验出现偏态分布是允许的
如大部分人应及格
难度的转换
- 通过率P不便于比较, 而且P越小难度越大, 比较别扭
- 可以用 1-P 对应的Z分数表示难度
- 美国教育领域常用难度指标: △ = 13 + 4Z
项目区分度
Item Discrimination
- 也叫鉴别力, 指测验项目对受测者心理特质的区分能力
- 区分度低的项目, 高水平和低水平受测者的得分差不多, 不能很好鉴别
- 区分度是评价项目质量、筛选项目的主要指标
- 区分度常用D表示, 范围是[-1,1]
计算方法
极端分组法(鉴别指数法)
- 将总分从高到低排序, 取最高 / 低的27%为高 / 低分组
- 分别计算两个组的通过率
- 用高分组通过率减去低分组通过率, 即 D = PH - PL
评价标准
- 0.4以上: 非常优良
- 0.3-0.39: 良好 / 能改进会更好
- 0.2-0.29: 尚可 / 需要修改
- 0.19以下: 差 / 淘汰或改进
前后测法
- 用同一测验, 对同一组受测者, 在教学 / 训练前后各测试一次
- 分别计算两次测试的通过率
- 用后测通过率减去前测通过率, 即 D = Ppost - Ppre
- 缺点: 练习效应、需要进行两次测试、解释不明确
D值低时, 无法确定是由试题不良还是教学不当引起的
对照组法
- 适用于标准参照测验
- 在其它评估指标
例如教师评定的帮助下, 将受测者按照一定标准分为掌握组和未掌握组 - 分别计算通过率
- 用掌握组通过率减去未掌握组通过率, 即 D = Ps - Pn
- 缺点: 外在评估标准不同, 所得区分度不同
题总相关法
- 以项目得分和测验总分的相关作为区分度指标
前提是总分可以作为能力/人格的评价指标 - 计算时使用了所有数据
- 相关越高区分度越好
积差/点二列/二列/phi - 只保留相关高于临界值
如0.4的题目 - 如果需要保留n个测试题, 则选择n个r最高的测试题
区分度的相对性
- 不同计算方法得到的区分度值不同, 无法比较
- 用极端分组法得到的区分度受分组标准影响
- 用相关法得到的区分度的显著性受样本大小影响
- 区分度大小受样本同质性影响
越同质区分度越小
难度与区分度的关系
| 难度P | 1.00 | 0.90 | 0.70 | 0.50 | 0.30 | 0.10 | 0.00 |
| 最大区分度Dmax | 0.00 | 0.20 | 0.60 | 1.00 | 0.60 | 0.20 | 0.00 |
- 较难 / 易的题目对高 / 低水平的受测者区分度高
- 由于多数心理特质呈正态分布, 所以项目难度分布也为正态分布为好, 范围大致在0.3-0.7之间
选择题反应模式分析
选项分析的过程
- 根据受测者的测验总分, 对受测者排序
- 确定高分组和低分组的受测者
- 分别登记两个组在每道题的每个选项上的作答人数及未作答人数
如下 - 根据上一步的表格, 进行具体分析
| 题号 | 组别 | a | b | c | d | 未做答 | 正解 | 难度 | 区分度 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 高分组 | 36 | 0 | 39 | 23 | 2 | d | .21 | .05 |
| 低分组 | 32 | 0 | 46 | 18 | 4 | ||||
| 2 | … | … | … | … | … | … | … | … | … |
选项分析的原则
- 大部分选择的正确率应该在0.4-0.6之间, 其余诱答均分剩余选择率
- 对于正解 / 诱答, 考察高分组和低分组的选择率正差 / 负差是否够大
- 如果正解被所有人选择, 说明题目有暗示或太简单
- 如果题目未做答人数过多或各选项人数相等, 说明题意不清或题目过难
- 如果高分组的选择集中于两个答案且选择率接近, 说明可能有两个正解
- 如果高分组选择率等于甚至低于低分组, 说明题目的测量目标与整个测试的测量目标不同
- 如果某个诱答选择人数过少
低于2%, 说明它不具迷惑性, 应该删除 - 如果高分组选择了同一个诱答, 可能是答案错误或教学错误
项目功能差异与偏差
项目功能差异 / Differential Item Function, DIF
不同群体对同一项目的答对概率不同 即在同一项目上得分存在差异
良性DIF与不良DIF
- 良性DIF: 源于群体间本身水平存在差异, 不存在测验偏差
Test Bias - 不良DIF: 源于文化 / 性别 / 地域 / 种族 / 职业 / 年级等导致, 存在测验偏差
一致性DIF与不一致性DIF
- 一致性DIF: 受测者能力水平与其组别无交互作用
不存在尖子班和实验班的差别 - 不一致性DIF: 受测者能力水平与其组别有交互作用
不良DIF的控制
- 目的是避免项目所测构念与全卷想测的构念不同
- 题目语言规范、无歧义、不使用方言 / 俚语
- 编织好的题目应广泛征集不同群体的意见
- 最好进行小范围试测, 并修改 / 删除有不良DIF的试题项目
项目反应理论
Item Response Theory, IRT
经典测验理论的问题
- 试题难度和区分度因样本不同而不同
因此同一份试卷很难获得一致的难度和区分度 - 对能力很高 / 很低的受测者的能力估计不合理且不准确
- 忽视受测者的项目反应模式
Item Response Pattern, 相同原始分的受测者, 其反应组型不见得一致, 其能力估计值实际上应该不同
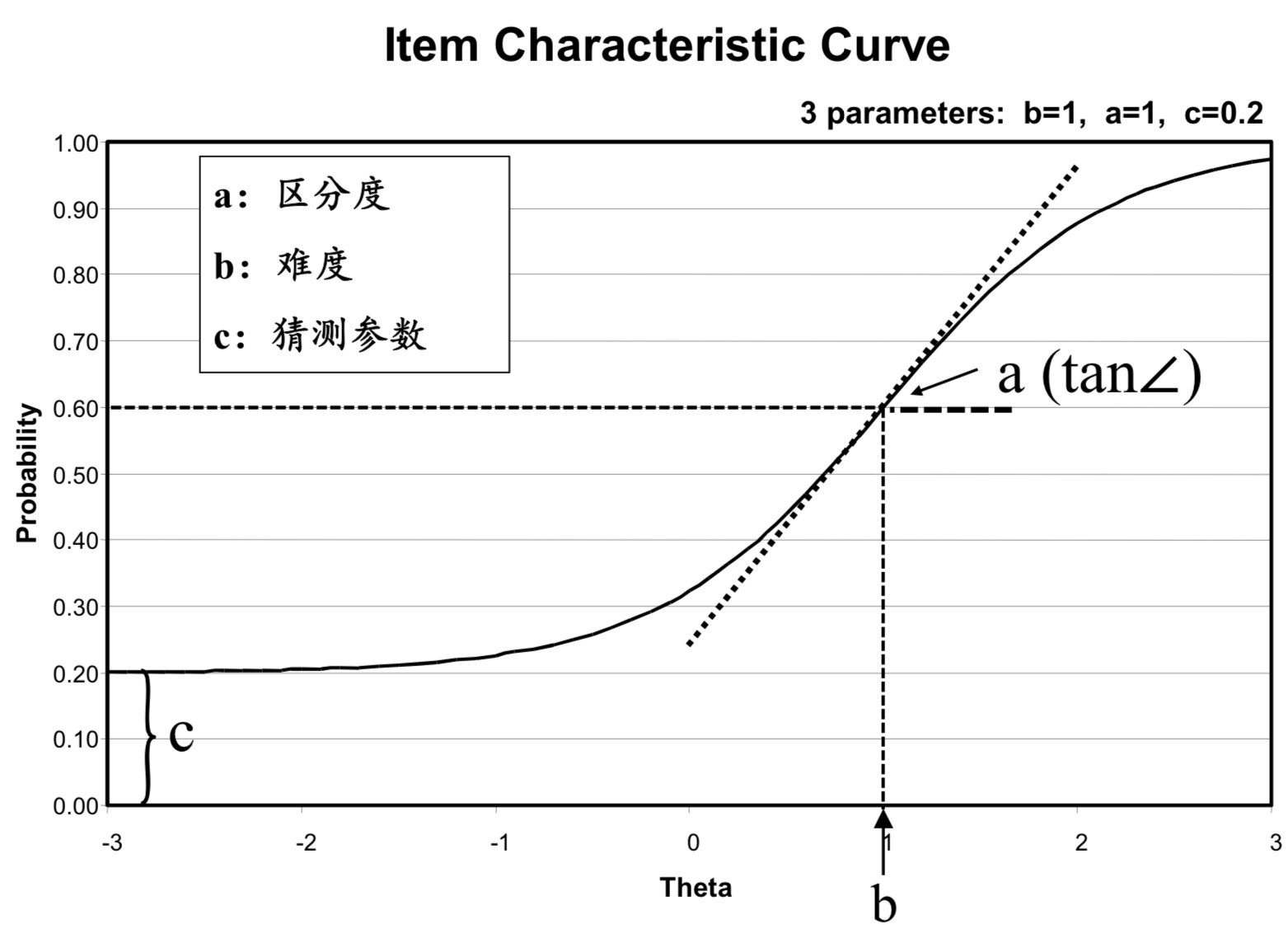
项目反应理论的基本思想
- 假设受测者对测验的反应受某种心理特质(潜在特质 / Latent Traits)的支配
即根据受测者的特质水平可以预测其对项目和测验的反应 - 受测者的表现和潜在特质的关系, 可以用一条连续递增的函数: 项目特质曲线
Item Characteristic Curve, ICC描述 - 假设潜在特质是一维的且对各个问题的回答是相互独立的
项目答对率计算公式

项目反应理论的优点
- 能力参数估计的不变性: 受测者能力参数的估计与所使用测验包含哪些测验项目无关
- 项目参数估计的不变性: 项目参数的估计与所使用的样本无关
- 参数设计科学: a与b独立, c通过数据计算得出
- 受测者能力和项目难度在同一个量表上, 为测验的编制、测验分数的报告和解释提供便利
- 提供受测者能力估计值的误差指标: 项目信息函数
Item Information Functions和测验信息函数Test Information Function, 测验前就可以确定各项目及整个测验对于受测者能力估计的精确度
⭐信度
Reliability
测量误差
误差的含义
在测量中与目的无关的因素所引起的不准确或不一致效应
误差的种类
- 随机误差
Random Error: 由与测量无关的变量引起的一种无规律的误差, 不易控制 - 系统误差
Ssytem Error: 由与测量无关的变量引起的一种恒定而有规律的误差
测量误差的来源
测验内部
- 测验项目和取样的代表性
- 题型的猜测性
测量工具的设计及形式 - 表述的模糊性
语义不清/编排不良等 - 题目的难度过高或过低
- 题目的指导语用词不当
- 测验的时限过短
施测 / 评分 / 解释过程
- 测验环境因素
- 主试因素
主试的解释/重述/语气/态度/肢体动作/反馈 - 意外干扰
- 评分计分
计分错误/数据分析处理不当/主观题评分标准不清/光环效应
受测者本身
- 应试动机
装好/装坏 - 测验焦虑
- 练习效应
- 测验经验
应试技巧 - 反应倾向
选项偏好 - 生理异常
疲劳/疾病
效标的选择不影响信度
经典测验理论
Classic Test Theory, CTT
也叫真分数理论 / True Score Theory
- 测验分数X = 真分数T + 误差E
- 真分数
True Score, T: 受测者不受任何随机因素影响的条件下应该得到的分数, 无法直接测量, 在统计上用无数次测量的平均数代替 - 误差
Measurement Error, E: 即随机误差, 引起测量结果不一致的偶然误差, 可正可负
真分数的数学模型
基本模型: 测验分数是真分数和随机误差分数之和 X=T+E
引申定理一: 若某种构念可以用平行测验反复测量足够多次, 则测验分数的平均值接近真分数 Exp(X)=T Exp(E)=0
引申定理二: 真分数与测量误差的相关为零 r(T,E)=0
引申定理三: 不同测量误差之间, 以及测量误差与被测构念外的其他变量之间的相关为零 r(E1,E2)=0 r(E,T2)=0
引申定理四: 测验分数的方差等于真分数方差和误差方差之和 SX2=ST2+SE2
引申定理都在说明: 误差是随机变量
重要概念: 平行测验 / Parallel Test
- 能以相同的程度测量同一心理特质 / 构念的测验
- 题目形式 / 数量 / 难度 / 区分度 / 分数分布
平均数和标准差都一致 - 既可以完全相同
即重复施测, 又可能有某种差异 - 数学表达为 X=T+E 、X’=T+E’ 、SE2=SE’2
三个基本假设
- 真分数具有不变性: 所测构念必须具有某种程度的稳定性
- 误差是完全随机的: 测量误差是平均数为零的正态随机变量, 且误差间 / 误差与其他构念间相互独立
- 观测分数是真分数与误差分数的和
测量分数方差的分解
- 是信度的基础
- 测验分数的方差SX2 = 真分数的方差ST2 + 随机误差的方差SE2
- 真分数的方差ST2 = 潜在真分数的方差SV2 + 系统误差的方差SI2
信度的定义
信度的理论定义
测量分数的可靠性 Reliability, 即用同一测验 或不同的平行测验 多次测量同一受测者, 所得的结果的一致性程度, 只受随机误差的影响
信度的测量定义
信度系数
- 一组测量分数的真分数方差和总方差
实得方差的比率即真分数方差占总方差多大的比例 - rXX = ST2 / SX2, 其中rXX被称为信度系数
总分数方差不变, 真分数方差越大, 误差方差越小, 信度越高
信度指数
信度还可以解释为测验分数与真分数之间的相关系数的平方, 即rXT2 = rXX,其中rXT被称为信度指数
一般讲信度时, 指的是信度系数rXX
由于不知道真分数是多少, 信度系数和信度指数仍然无法计算
测量标准误 / Standard Error of Measurement, SEM
当受测者完成一大批平行测验后, 这一组测验分数的平均数即为受测者的真分数, 标准差则为测量误差大小的衡量指标, 即标准误SE 标准误越小, 信度越高
标准误与信度系数的转化
测量标准误与误差的标准差的值是相同的, 所以由信度系数的定义可以推得: SE = SE = SX√(1-rXX)
信度的操作定义
两平行测验的测验分数间的相关, 即用一个平行测验分数去推测另一个平行测验分数的能力, rXX = rXX’
信度的临界值
| 从测验类型考虑 | 从测验功能考虑 | |||
|---|---|---|---|---|
| 测量类型 | 标准化能力和成就测验 | 人格 / 兴趣 / 态度 / 价值观 | 比较两个群体的平均水平差异 | 解释个体间的差异 |
| 信度要求 | >=0.9 | 0.8-0.85 | 0.6-0.7 | >=0.85 |
| 备注 | 本身比较稳定, 信度显著的要求较高 | 本身就不太稳定, 信度显著的要求较低 | 群体中的个体的误差平均数理论上是0, 即使个人的测验有相对大的波动, 整体比较时结果也是可信的 | 个人的测验的波动会对比较的结果造成较大影响, 信度的要求较高 |
判断信度的临界值, 其实就是看多大的信度才不会影响到你的使用目的
信度的性质
- 信度范围是[0,1]
- 信度是一组测量分数的性质, 不是个人分数的性质
- 信度不是测验本身的性质, 还受施测程序 / 标准化程度等因素影响
- 信度越高越好, 但没有任何测量是完全可靠的
- 对信度的最低要求视使用目的和情境而定
- 通常在心理和教育测量中, 信度低于自然科学中的测量
- 心理特质只能间接测量, 自然科学的特质往往可直接测量
- 自然科学的工具的精确性更高
- 心理特质变化较大, 自然科学的特质更稳定
信度的种类和估计方法
由于真分数未知, 我们只能对信度进行估计, 选用什么估计方法取决于你假定的误差来源是什么
一般的信度指标
| 重测信度 | 复本信度 | 分半信度 | 同质性信度 | 评分者信度 | |
|---|---|---|---|---|---|
| Test-retest Reliability | Alternate-forms Reliability | Split-half Reliability | Homogeneity Reliability | Inter-rater Reliability | |
| 误差来源 | 时间取样 / 稳定性 | 内容取样 / 等值性 | 内容取样 / 等值性 | 内容取样 / 同质性 | 评价者 / 观察者取样 |
| 施测次数 | 2 | 连续施测: 1 间隔施测: 2 |
1 | 1 | 1 |
| 所需复本 | 1 | 2 | 1 | 1 | 1 |
| 重测信度 | 复本信度 | 分半信度 | 同质性信度 | 评分者信度 | |
| 定义 | 同一量表, 同一受测群体, 不同时间, 两次施测, 求积差相关 | 以两个测验复本来测量同一群体, 然后求受测者群体在这两个测验上得分的积差相关 | 如果只有一个复本且只能测一次, 可以测量两个半测验的积差相关, 再进行校正 | 如果各个题目是测量同一心理特质, 则各个题目得分间相关越高则信度越好 | 抽取若干份 / 全部试卷, 由至少两个评分者分别判分, 然后计算他们的判分结果的相关 |
| 公式 | 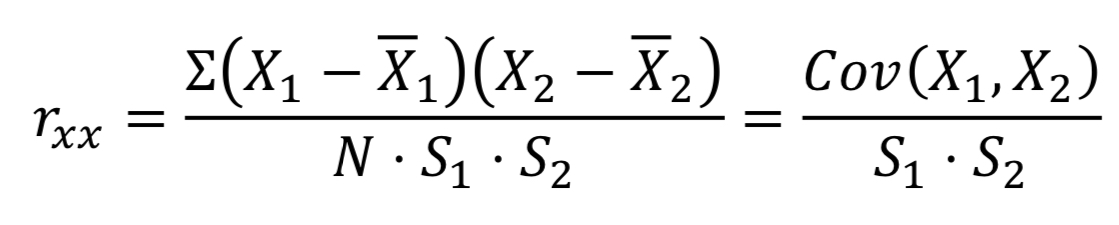 |
|
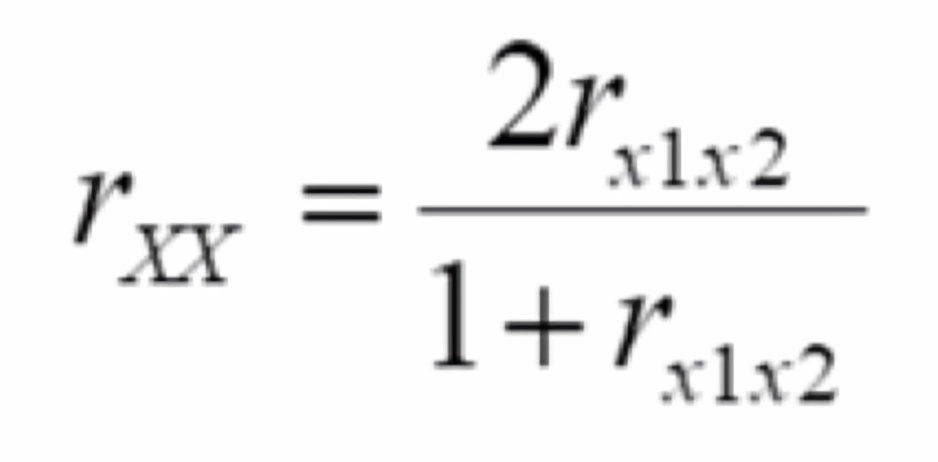 |
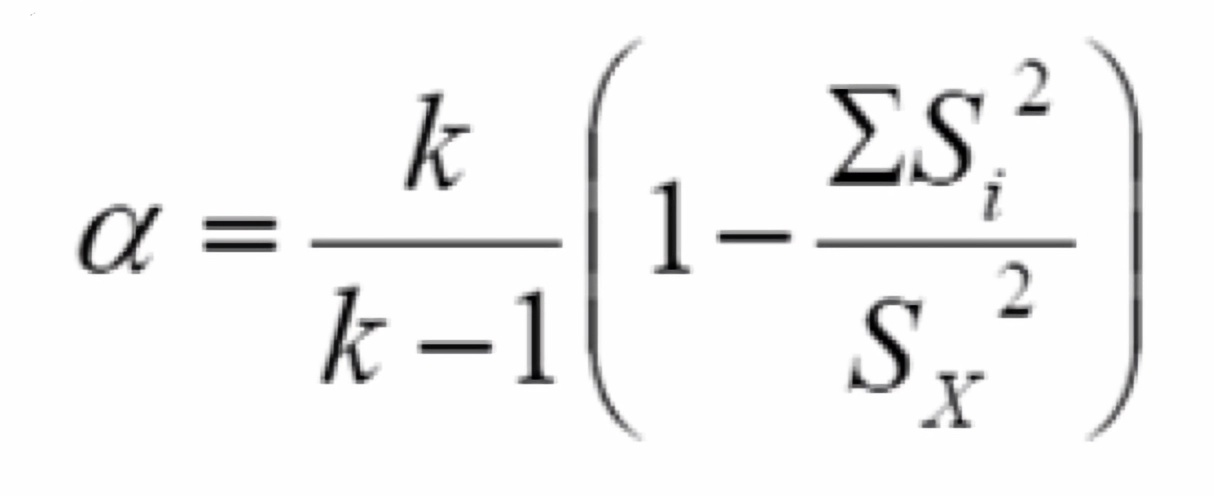 |
  |
| 公式解释 | X1和X2表示配对的原始分 | 同左, 但施测时应该一半被试先测A, 一半被试先测B ABBA设计 |
计算rx1x2方法同左, 上式为将半个测验的信度矫正为整个测验的信度的公式 | k为测验题目数 Si2为题目i得分的方差 SX2为整个测验得分的方差 |
两人等级评分: 斯皮尔曼等级相关 多人等级评分: 肯德尔和谐系数 连续变量评分: 组内相关系数 / ICC |
| 别称 | 稳定性系数 / Coefficient of Stability | 连续施测: 等值系数 / Coefficient of Equivalence 间隔施测: 稳定和等值系数 / Coefficient of Stability And Equivalence |
Alpha系数 / 题总相关 | ||
| 备注 | 施测 → 适当时间 → 再次施测, 表示测验结果的稳定性 | 稳定和等值系数由于同时包含了时间和内容的误差, 更为严格 | 分半时, 按照难易顺序排序后, 奇数偶数各为一半; 分半方式会影响结果 | 应用中, a的值至少要大于0.5, 最好能大于0.7 | 在SPSS中的相关或信度页计算 |
内部一致性信度 / Internal Consistency Reliability
- 分半信度和同质性信度统称为内部一致性信度, 表示如果测量同一维度的题目间相关性高, 则信度高
- 内部一致性信度会高估速度测验的信度, 对于速度测验, 最好用重测 / 复本信度
- 内部一致性信度一般要0.8以上才算好, 但也要视测量的性质和目的而定
用于标准参照测验的信度指标
标准参照测验意不在于区分个体差异, 因而大多时候, 受测者群体的测验分数分布较为集中, 因此传统的估计方法将低估其信度
分类一致性信度
从分类决策一致性角度定义信度, 类似于计算效标效度时的命中率法, 使用广泛, 但易受划界分数的影响
操作方法
受测者群体同时接受两个平行测验, 考察不同测验将受测者区分为”掌握”和”未掌握”的情况是否一致
| 平行测验B → 平行测验A ↓ |
掌握 | 未掌握 |
|---|---|---|
| 掌握 | A | B |
| 未掌握 | C | D |
P0 = (A+D) / N (类似于总命中率, N=A+B+C+D, 越接近 1, 测验越稳定可靠); 注意: 一致性为 0 时 A=B=C=D, P0≠0, 要解决这个问题可以用 Kappa 值
分类一致性系数 / Cohen’s Kappa
- K = (P0-Pe) / (1-Pe), 其中Pe = [ (A+B)(A+C) + (C+D)(B+D) ] / N2
Kappa值的理论范围为[-1,1], 当两个测验完全一致时,Kappa值为1Kappa ≥ 0.75时, 两者一致性较好0.4 ≤ Kappa < 0.75时, 两者一致性一般Kappa < 0.4时, 两者一致性差- 当观测一致率小于期望一致率时,
Kappa值为负数 (比较少见)
荷伊特信度
以真分数模型为基础, 利用方差分析的方法找出个体水平的真变异在总变异中的比例, 同时也适用于常模参照测验
操作方法: 将测验分数的总变异分解为受测者间变异SS人, 项目间变异SS题, 受测者与项目的交互作用SS人×题, rxx = 1 - MS人×题 / MS人
信度还有很多估计方法, 有多少误差来源, 就有多少种信度估计方法, 在考察测验的信度时, 原则上测验的哪种误差来源最大, 就应该优先使用对应的那种信度估计方法, 有条件的话, 还应该报告多种信度系数, 以评估多种误差来源
信度与测验分数的解释
解释个人分数的意义
- 信度系数表示一组测量分数有多可信
- 测量标准误告诉我们一个人的分数究竟有多可信
信度的另一个表达方式 - 二者可以相互转化
用标准误估计真分数范围
- 在CTT中, 测量误差被假定为正态分布, 因此可以根据标准误和Z值表估计真分数
- 一般将置信度设为0.95, 则置信区间为 X-1.96SE ≤ T ≤ X+1.96SE
由 -1.96SE ≤ X-T ≤ 1.96SE 推导而来
比较不同测验分数的差异
分数的可信度将影响我们对分数差异的解释, 包括:
- 两个人在同一测验上分数的差异
- 两个人在不同测验上分数的差别
- 同一个人在不同测验上分数的差别
差异分数的标准误
只有差异的分数高于一定标准 如1.96个差异分数的标准误, 我们才能认为分数差异显著, 不同测验需要转化为标准分, 再放在一起计算, 公式为: |
 |
关于其中的S, 如果都标准化为Z分数则S=1, 也可以都标准化为T分数
相关的校正
| 两个构念的相关往往会因为不可信的测量而被低估, 这时我们可以用校正公式, 估计在完美测量时两个构念的相关, 公式为: | 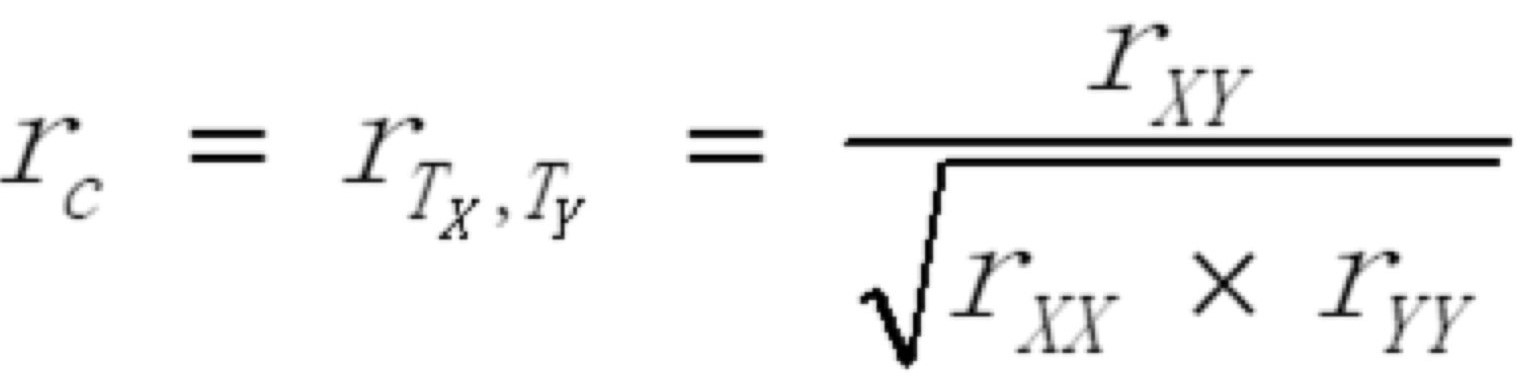 |
影响信度的因素
测验长度
往测验中增加同质的题目, 信度会提高。因为测验越长, 测验的题目 / 内容取样就更能代表总体, 而且受测者猜测因素就会越小, 但是过长会使测试者疲劳和反感, 降低可靠性 公式为: |
 |
样本特征
- 信度系数是相关系数, 会受到样本分数的分布影响
- 分数的分布又会受样本团体的异质程度影响
- 如果获得信度的取样团体较为异质, 往往得到较高的信度
同质性样本的个体排名很容易因为随机误差变化, 导致信度降低
测验难度
- 过难
只能靠猜过易粗心大意的题目都会导致信度降低 - 一般的能力测验最适合用来测量中等能力者
- 标准化测验要根据不同受测者的能力分别报告信度
作为选择测验的参考
时间间隔
- 时间间隔只对重测信度和不同时测量的复本信度有影响
- 间隔过短会导致练习和记忆效应大, 根据情况不同会导致信度偏高或偏低
- 间隔过长会受到自然发展和教育经验的影响, 使信度偏低
⭐效度
Validity
效度概述
效度的定义
- 概念定义: 所测量的与要测量的心理特质之间的符合程度, 即测验的准确性
- 测量定义: 与测量目的有关的方差 SV2 与总方差 SX2 之比, 即 rXY2 = SV2 / SX2, 其中 rXY2 为决定系数, rXY 为效度系数
效度与信度的关系

效度的性质
- 效度是针对测验结果的使用
即测验的目的而不是测验分数本身 - 效度具有相对性: 不存在一般化的效度指标, 任何效度都是相对于某个测量目标来说的
测验被用于与测量目标一致的场合才更有效 - 效度具有连续性: 通常用相关系数表示, 只有程度的不同, 不能说有或无的区别
内容效度
Content-related Validity
测验题目对内容或行为取样的恰当程度, 用以确定测验是否是欲测量的行为领域的代表性取样 多用于成就测验、职业资格测验、工作样本测验
基本要求
- 对所测量的心理特质有明确的概念, 并划定出哪些行为与该心理特质有关
- 测量项目是已界定的内容范围的代表性样本
估计方法: 专家判断法
- 请相关专家对测验题目和原定内容的符合性做出判断, 看测验题目是否有代表性
依赖专家的经验和逻辑能力 - 这种方法的估计是一个逻辑分析过程, 因此也被称为逻辑效度 / Logical Validity
是评价内容效度的主要方法
具体做法
- 先定好测验内容总体范围, 描述有关知识和所用材料来源
- 根据双向细目表
X: 测验目标, Y: 测验内容, 计数: 内容的各目标的相对比例, 确定内容和技能各自所占比例 - 制订评分量表, 请专家从测验包括的内容、技能、材料的重要程度、题目对内容的适用性等维度打分
量化指标
CVR = (ne - N/2) / (N/2)
- ne表示专家中认为项目是必要的数量
- N表示专家的总人数
- CVR范围是[-1,1]
- 正值表示专家中的多数认为项目是必要的
- 负值表示专家中的多数认为项目不必要
其他估计方法
统计分析法
观察测验的复本相关来确定效度: 如果复本都可以很好代表同一个总体, 则相互之间相关高可以代表测验效度高, 但要小心复本都存在相同的偏差 如果复本相关低, 则至少有一个复本的效度不好
再测法
前测 → 教学或训练 → 再测: 检查再测的分数是否显著高于前测
经验法
检查不同年级学生在测验上的的得分和在每个题目上的反映情况 对于成就测验, 如果总分随着年级提高而增高, 说明内容效度较好
内容效度的特性
- 内容效度不是普遍适用的
一个老师出的题对自己班和另一个平行班的效度不同 - 只有测验编制者和使用者定义的内容范围相同, 编制者报告的内容效度对使用者才有意义
内容效度与表面效度
- 表面效度
Face Validity, FV, 指测量从其试题和材料上看起来能在多大程度上测量到其好像要测的指标未必反应测量实际上要测的东西 - 影响测量的友好度和受测者接受度, 进而影响作答动机与测量结果
高质量的测验往往应具备较高的FV - 有时高FV可以起到伪装测验的作用
如表面测量尽责性, 实际上测量社会称许性
效标效度
Criterion-related Validity
- 通过测验预测个体在某种情境下的行为表现的有效性的程度, 即将测验分数与效标
Criterion, 即希望预测的行为联系起来如员工选拔测验与工作绩效 - 效标效度是基于数据的
计算选拔测验分数与工作绩效的相关 - 效标效度需要在实践中检验, 因此又称实证效度
两种效标效度
同时效度 / Concurrent Validity
- 效标分数与测验分数同时收集
- 检查测验测量的某种现有的能力 / 特质的有效性
即描述当前状态的有效性 - 目的: 用测验分数去替代效标分数
因为可能获得效标分数的成本很高
预测效度 / Predictive Validity
- 先收集测验分数, 一定时间后再收集效标分数
- 表明测验对某种行为进行预测的有效性
- 目的: 用测验分数去预测效标分数
重要概念
以大学学业成就作为高考的效标为例
- 观念效标: 概念上要测量的效标
即效标的构念, 如大学学业成就 - 效标测量: 以具体的指标表示效标行为的高低
如大学四年的平均绩点 - 实际预测源: 用于预测效标的测验
高考, 也就是我们编制的测验 - 预测源构念: 实际预测源要测的构念
认知能力
理想情况下: 效标测量 = 观念效标、实际预测源 = 预测源构念
- 效标效度研究的对象: 实际预测源和效标测量的相关
- 效标效度研究的目的: 预测源构念与效标构念的相关
- 但是, 测验使用者关心的是实际预测源与效标构念的关系
效标的适当性和效标的污染

效标效度: 由于EF无法分开, 所以会存在效标效度高只是因为F区域高的风险
效标污染: 比如由于评定者知道受测者的预测源分数, 而有意无意地调整自己的评分 改变BCEF圈, 很可能增大CF, 但其原本目的应该是尽量与观念效标 ABDE圈 重合
好效标的特点
- 能有效反应测验的目标
即本身必须有效 - 具备较高的信度, 稳定可靠, 不随时间等因素变化
- 可以被客观测量, 可用数据或等级表示
- 测量方式简单, 省时省力省钱
常见的效标
- 学业成就: 学科成绩 / 学历 / 获奖
- 工作表现评定: 产量 / 销售额 / 治愈率 / 违规次数 / 被投诉次数
自评/他评/客观指标 - 已知有效的测验的得分
- 临床诊断结果
- 来自他人的等级评定
家长/教师/同事/领导 - 不同团体
智力测验-不同年龄团体、兴趣测验-不同职业团体
估计方法
Z检验、T检验、相关的计算公式见心理统计学笔记
相关法
- 用测验分数和效标分数的相关系数
积差/等级/二列/点二列等来评估效度, 这一相关系数称为效度系数是最常用的方法 - 越大越好, 虽然没有最低要求, 但至少要达到统计显著
- 优点: 提供了一个可比较的统计指标、可用于建立回归方程
- 缺点: 如果预测源与效标的关系非线性就用不了、不能提供有关取舍正确性的指标
区分法
以测验分数进行通过 / 不通过分组, 对两组的校标分数进行Z检验或T检验, 检验测量分数能否有效区分效标所定义的团体
命中率法
- 当测验是用来做取舍的依据时
如人员选拔, 可用其正确决策的比例作为效度的指标 - 总命中率PCT: 命中的人 / 总人数, 即A+D / A+B+C+D
命中: 指测验和效标的结果一致 - 正命中率PCP: 命中成功的人 / 测验成功的人, 即D / C+D
不关心有没有把原本很好的人错误地排除掉
| 效标成绩 → 测验成绩 ↓ |
不合格 | 合格 |
|---|---|---|
| 不合格 | A 命中 True Negative |
B 失误 False Negative |
| 合格 | C 失误 False Positive |
D 命中 True Positive |
构念效度
Construct-related Validity
测验能够测量到理论上的构念或特质的程度, 即测验的结果是否能证实或解释某一理论的假设、术语或构念, 解释的程度如何 也称为构思效度或结构效度
内容效度和效标效度都体现了构念效度
检验流程
- 从某一构念的理论出发, 提出关于某种心理特质的假设
- 设计和编制测验并进行施测
- 对测验的结果采用相关或因素分析等方法进行分析, 验证测验结果与理论假设的符合程度
估计方法
测验内方法
通过研究测验内部结构, 如测验的内容、题目间的关系, 来分析测验的构念效度
- 测验的内容效度可作为构念效度的证据
- 分析被试对项目作反应的过程
社会赞许性等影响因素 - 考察测验的同质性
内部一致性指标
测验间方法
通过分析几个测验间的相互关系, 找出其共同与不同之处, 进而推断这些测验测量的特质是什么, 确定其构念效度
相容效度 / Congruent Validity
考察一个新测验与测量同一构念的现有测验 已有效度证据 的相关系数, 以证明新测验的效度
多质多法矩阵 / Multitrait-multimethod Matrix, MMM
以一种以上的方法 Methods, 测量一种以上的特质 Traits, 具有良好构念效度的测验, 其测验结果不仅应与测量相同构念的变量有高相关 会聚效度, 也应与测量不同构念的变量有低相关 区分效度
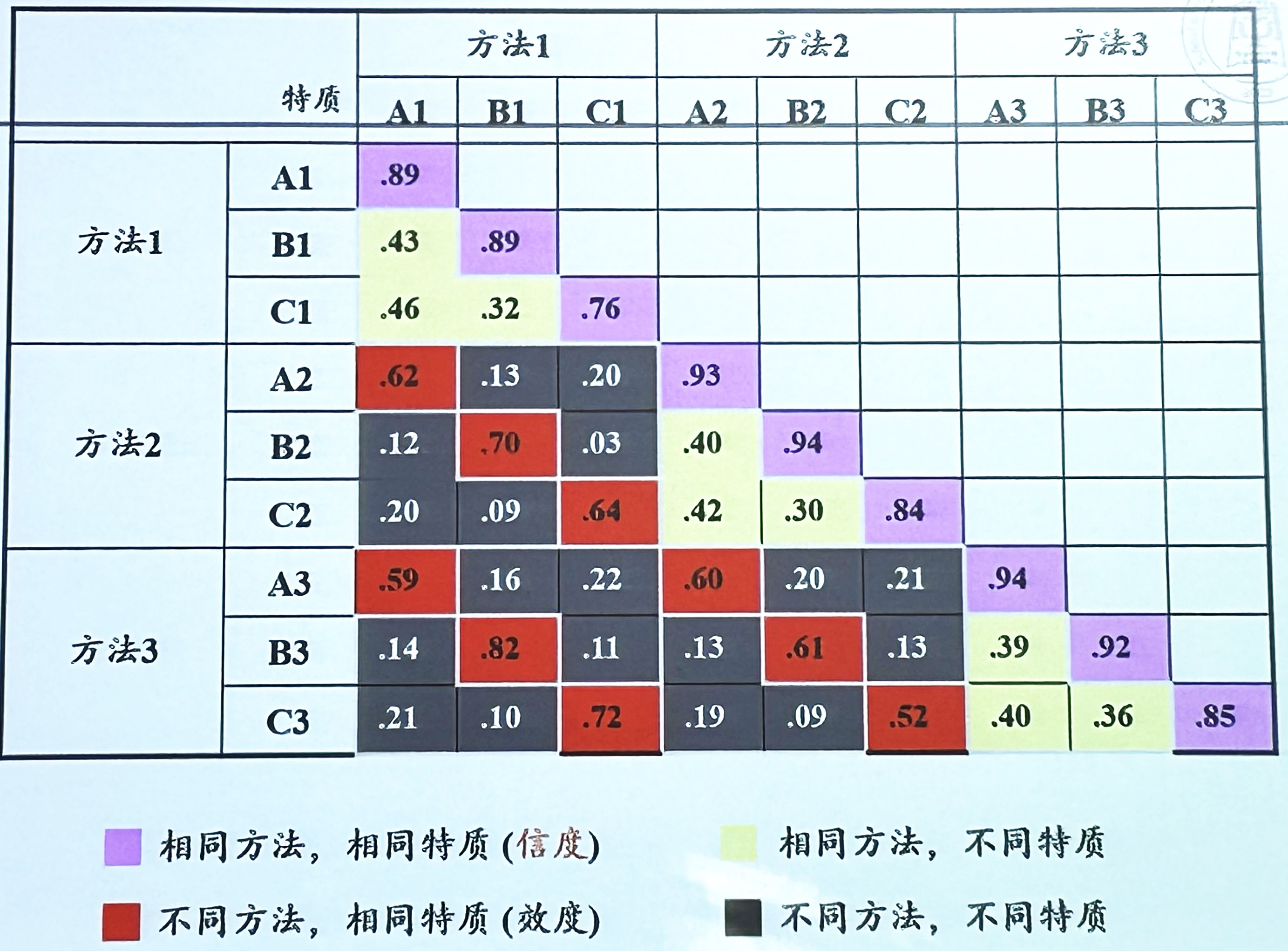
- 效度对角线
Validity Diagonal: 上图中红色线, 对同一构念的不同测量- 可比三角形: 上图中黄色 / 灰色三角形, 应表现为同一相关模式
- 方法效应
Method Effect: 以相同方法测不同特质的相关高于以不同方法测不同特质的相关, 此差异应越小越好
会聚效度 / Convergent Validation
用不同方法测量同一种构念所得的相关, 在MMM中, 这些相关系数值应该较高, 在图中应仅次于信度
区分效度 / Discriminant Validation
- 不同方法测量不同特质之间的相关应小于效度对角线
- 同一方法测量不同特质之间的相关应小于效度对角线
- 在图中应是相关最低的部分
效标效度法
一个测验若效标效度理想, 那么该测验所预测的效标的性质和种类就可以作为分析测验构念效度的指标
- 对比对照组与高低分组
检验用测验测得的心理学部和艺传学院的绘画能力是否有显著差异 - 对比发展变化的不同时期
比较高低年级的得分是否有显著差异
实验法
- 考察经过某种实验训练后, 测验得分是否有所变化
- 出声思考法
边做题, 边把想到的所有细节说出来: 在实验前实施测验, 实验中要求被试出声思考, 考察测验结果与出声思考更加真实客观结果的一致性
因素分析法 / Factor Analysis
- 一种多元统计分析技术, 主要目的是降维, 即用更少量的因素概括解释许多相互关联的变量
- 通过对一组题目进行因素分析, 可以找到影响测验分数的共同因素, 这种因素可能就是我们要测量的构念
- 因素分析法对构念效度的证明既可以是以项目为单位, 也可以以分测验为单位
因素效度 / Factorial Validity
各因素在各分测验 或项目 上的负荷量, 即各分测验 或项目 与因素的相关
共同度 / Communalities
抽取出的因素一共能解释测验分数变异的多大比例, 即测验分数与各个因素的相关系数的平方的和, 可作为测验构念效度的指标
以韦氏智力测验为例
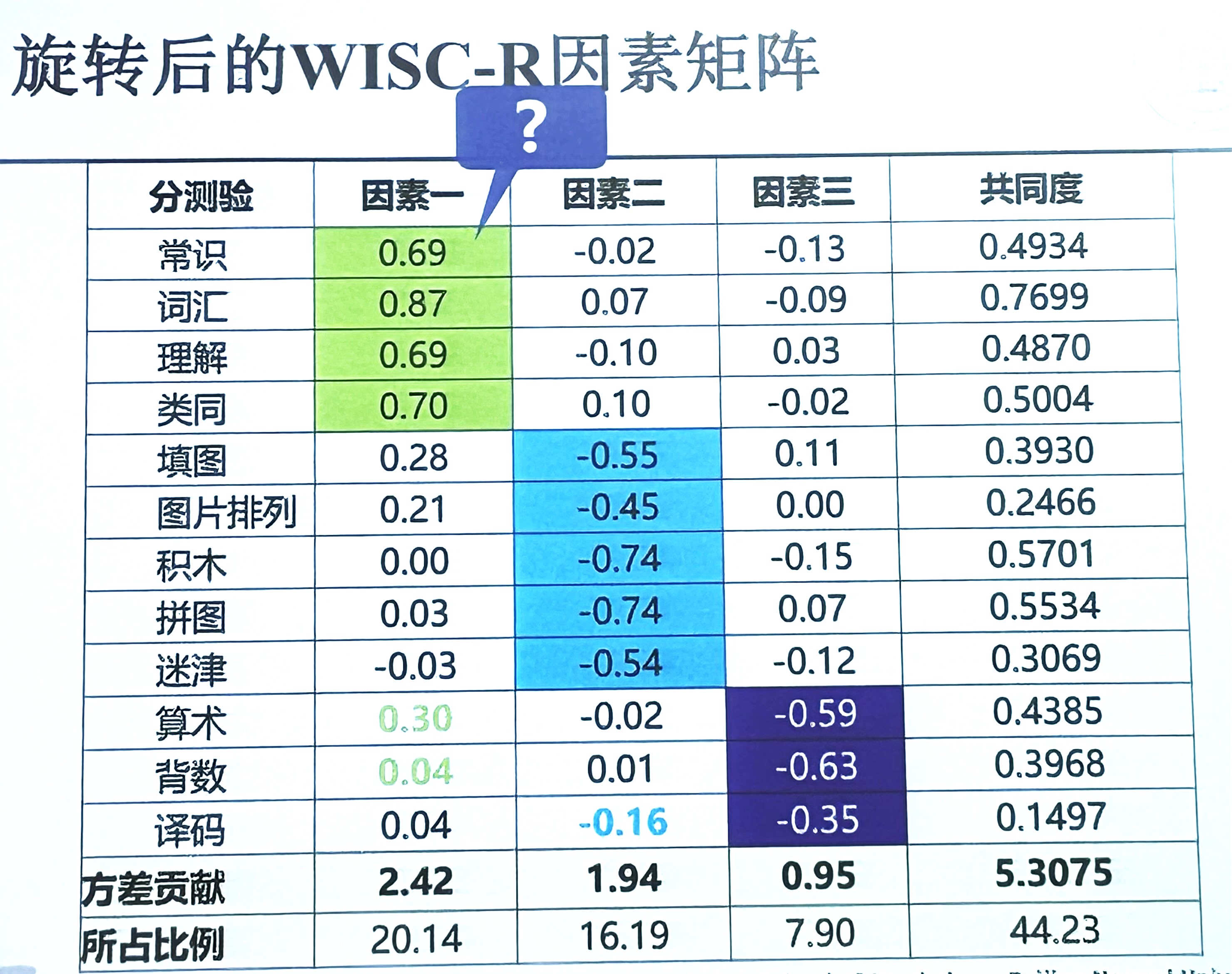
当因素增大到12个(和分测验数量一样, 即每个题目都是一个因素)时, 共同度就是1, 即测验分数完全被因素解释, 但此时因素太多, 模型复杂(因素分析原本就是为了简化模型), 对于自然科学, 要求保留到共同度0.95以上, 人文科学0.5-0.6就可以了 但是也没有绝对标准, 要综合解释率、碎石图、因素数等人为综合判断
图中的负值是因为电脑和人定的因素的方向不一样 人设置的是因素X, 电脑算的是因素-X, 不影响结果, 但是出现和别的题目正负相反的且不是反向计分的题, 可能是题不好
SPSS操作
- 降维 → 因素分析
- 描述统计 → 勾选KMO: 表示这一组题目的变量间的关联性, 关联性高才有因素分析的意义, 一般要大于0.7之后做因素分析比较合适
- 提取 → 勾选碎石图
- 选项 → 显示的临界值: 先设的小一点如.15, 再设的大一点如.30
隐藏低载荷的值, 用以确定每个因素包含的项目
效度的功能
预测效标分数
- 根据已经收集到的测验分数与对应的效标成绩建立回归方程
- 当新的受测者
必须来自于导出回归方程的样本所在的总体出现, 我们可以通过其测验分数, 预测其效标的成绩
建立回归方程


确定预测的误差
决定系数 / Coefficient of Determination
- 等于用测验分数预测效标分数的效度系数的平方
- 表示测验正确预测或解释的效标成绩的方差占效标成绩总方差的比例
- 表示回归平方和在总平方和中所占比例
- 表示X对Y的解释程度, 即X的方差变异占Y的方差变异的比例
- 决定系数为1时, 测验成绩完美替代校标成绩
- 决定系数为0时, 测验与校标没有联系
预测的标准误
Sest = SY √(1 - rXY2)
- SY 为效标成绩的标准差
- rXY2 为决定系数
效度系数的平方 - 95%置信区间: Y - 1.96Sest ≤ YT ≤ Y + 1.96Sest
- 99%置信区间: Y - 2.58Sest ≤ YT ≤ Y + 2.58Sest
计算类似于测量标准误: SE = SX √(1 - rXX)
将测验用于人员选拔
选拔时, 单纯高效度的测验不一定有用, 公司关心是正命中率, 即达到录取线的人, 有多少达到工作要求
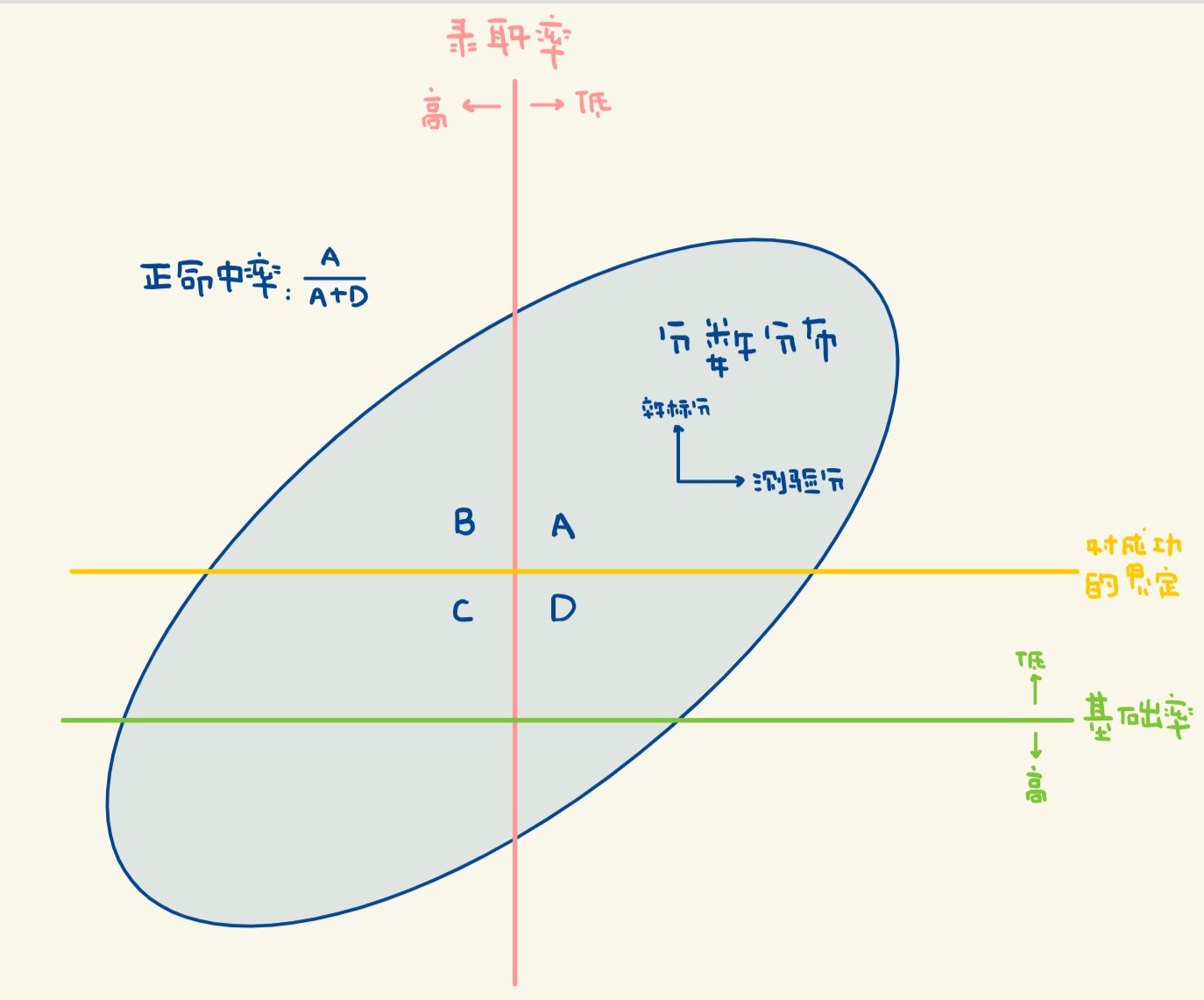
基础率 / Base Rate
- 即在未经选择的总体中某现象或行为的出现率
- 测验要有用, 必须比单纯依据基础率能做出更多的正确决定
- 当要预测的行为的基础率特别高
测不测一样或者特别低只要出现直接全部录取就行时, 没有必要使用测验 - 基础率越低, 测验效度提升使得正命中率提升的相对比例越大, 用测验的好处越大
- 基础率越接近0.5, 测验效度提升使得正命中率提升的绝对数值越大, 测验的贡献越大
录取率 / Selection Ratio
- 即从申请者中选出的人数比例
- 分数线
Cut Score: 合理设置可提高测验使用的价值若工作对所测能力的要求不高, 可以按照最低能力水平划线 - 效度一定时, 录取率越低, 测验的贡献和正命中率越大
- 反之亦然
大学生越来越水了也不一定是高考效度降低了
功利率
- 即投入产出比
- 使用测验的效益应远大于不使用测验的效益
- 测验的好处应远大于测验所耗时间 / 精力 / 经费
利用测验决策时应注意的问题
- 测验只是做决策的辅助工具
- 确定测验效度值的最低标准
- 相关系数达到统计显著
- 使用测验必须比依据基础率产生更多的正确决策
- 使用测验后能达到一定的功利率
- 测验的有效性大于其它现有工具, 或形成补充
- 对效度的评价是基于团体数据, 而非某个人的数据
- 实际工作中可以采用多个测验进行连续选择
- 如果一个测验的效度比较低, 可以多加几个测验, 但是加入测验时, 增大的解释率 △R2 要大于0.15才有价值
参见"心理统计学"笔记的"多元回归"部分
影响效度的因素
测验本身的因素
测验取材的代表性、测验长度、试题类型、难度、区分度以及编排方式等都会影响效度, 要保证测验具有较高效度, 要做好以下几点:
- 测验材料必须对整个内容具有代表性
- 测题设计时应尽量避免容易引起误差的题型
如是非题 - 测题难度要适中, 具有较高的区分度
- 测验长度要恰当, 即要有一定的测题量
- 测题的排列按先易后难顺序
施测过程中的干扰因素
主试的影响因素
- 是否遵从测验使用手册的各项规定进行标准化的实施
- 指导语是否统一正确
- 测验的时限是否一致
- 评分是否合理
- 测验与效标数据收集的时间间隔
- 施测环境如何
受测者的影响因素
- 受测者在测验时的兴趣、动机、情绪、态度和身心状况、健康状态
- 受测者是否充分合作与尽力而为等
- 受测者的反应定势会降低测验的效度
样本团体的性质
样本团体的异质性
类似于信度, 如果其他条件相同, 样本团体越同质, 分数分布范围越小, 测验效度就越低
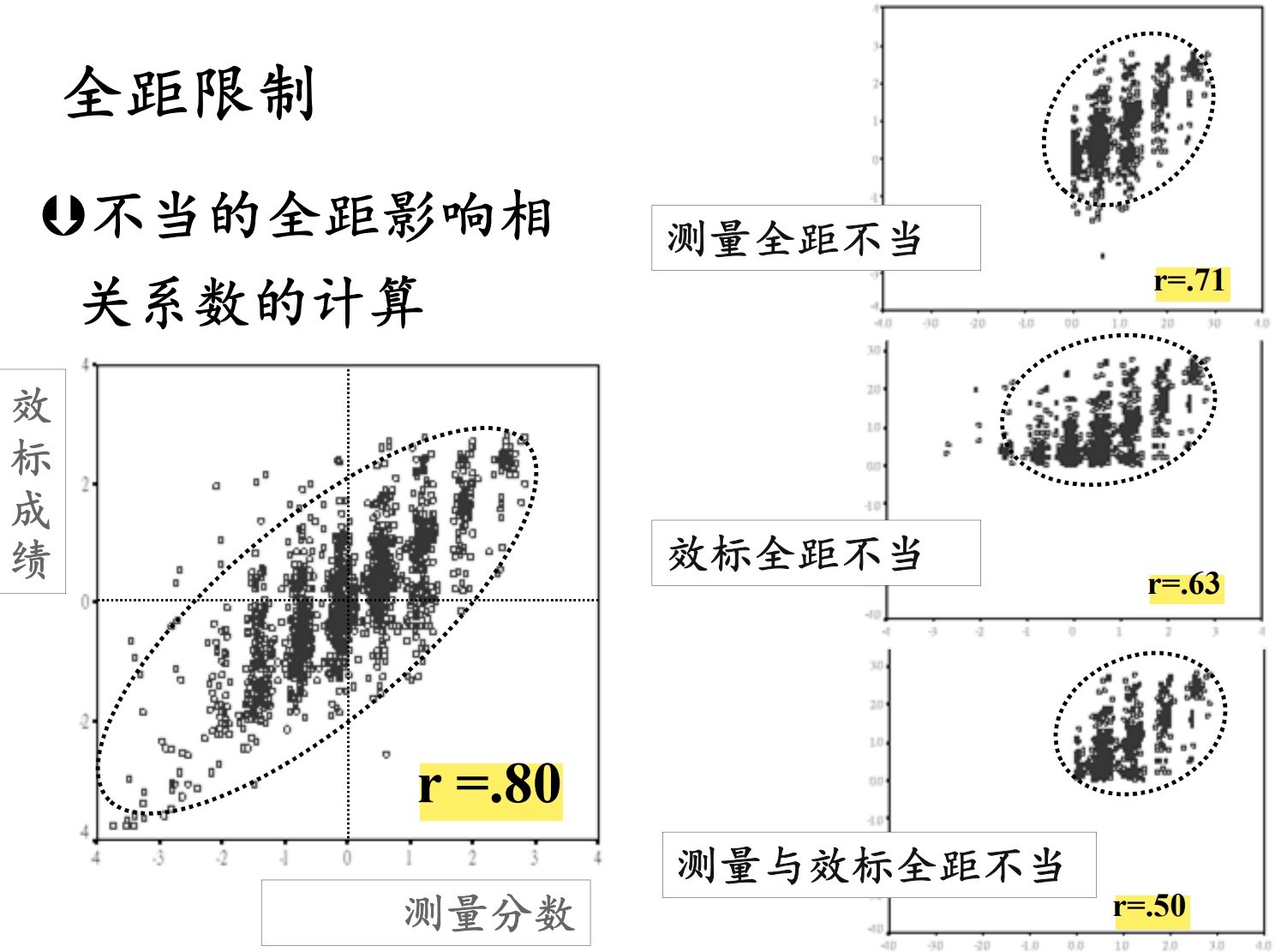
全距限制
取样时, 只取了总体中的一部分, 如只以选拔上的被试为样本研究效度、只以绩优者作为样本研究效度, 会导致效度降低
干涉变量
- 对于不同性质的团体, 同一测验的效度会有很大的不同
- 这些性质包括年龄、性别、教育水平、智力、动机、兴趣、职业等
- 由于这些特征的影响, 使得测验对于不同的团体具有不同的预测能力
- 测量学上称这些特征为干涉变量
Moderator Variable
吉赛利 E. E. Ghiselli 提出处理干涉变量的方法:
- 用回归方程求得每个人的预测效标分数, 将该分数与实际效标分数相比较, 获得差异分数D, 如果D的绝
对值很大, 说明测验中可能存在干涉变量 - 根据样本团体的组成分析, 找出对照组, 分别计算效度, 找出干涉变量
- 对于欲测团体, 根据某些易见的干涉变量将其区分为预测性高和预测性低的两个亚团体。对于预测性高的团体, 获得的测验效度会有所提高
测验分数与校标测量的信度
效度受到信度的制约, 如果预测源测验和效标测量两者本身信度低, 也会导致对效度的低估, 可用公式校正

效标的性质
- 效标效度是以测验分数与效标测量的相关系数来表示的, 在评价测验的效度时要考虑校标的性质
- 考虑效标成绩与测验分数的相关是否为线性
- 考虑效标测量的有效性
⭐测验分数的解释
常模参照测验
Norm-referenced Test
- 原始分数
Raw Score: 不具备实际意义, 需要对其进行解释 - 导出分数
Derived Score: 通过统计方法, 由原始分数构成的分布转化而来的分数 - 常模
Norms: 常模样本的测验分数的分布状态, 用于确定相对位置、发展水平 - 常模团体
Normative Sample: 由具有某种共同特征的人所组成的一个群体, 或该群体的一个样本 - 常模参照分数: 将受测者的分数直接或间接的以在常模团体中的相对等级或相对位置来表示的分数, 属于一种导出分数
常模团体
- 任何测验都有许多可能的常模团体
性别、年龄、职业、社经地位、教育水平、婚姻状况等 - 无论是编制测验还是使用测验, 都必须先明确测验的常模团体是什么
- 分为一般常模和特殊常模
一个特殊的小团体
对常模团体的要求
- 要明确界定群体的构成: 依据不同的变量
见上方确定群体, 可得到不同的常模有条件应该为群体内的亚群体也制定常模 - 常模样本必须是所测群体的代表性样本
取样要适当 - 样本大小要适当: 一般来讲越大越好, 但要考虑人力物力时间成本, 小总体一般要全体取样, 样本最低应不少于30人
全国性常模应有2000-3000人 - 认识到常模样本是一定时空的产物: 适时更新常模, 避免代际、文化、人种等差异
常模团体的取样方法
取样, 即从目标人群中选择有代表性的样本, 有随机抽样和非随机抽样两种方法。为了保证常模团体的代表性, 应采用随机抽样, 以保证每个个体机会均等
简单随机抽样 / Random Sampling
按照随机表顺序选择受测者构成样本, 或者将抽样范围内的每个人或者每个抽样单位编号, 再随机选择, 可以避免由于标记、姓名、性别或其它社会赞许性偏见而造成抽样误差
系统抽样 等距抽样 / Systematic Sampling
在总体数目为N的情况下, 若要选择K分之一的受测者作为样本, 则可以在抽样范围内选择每个第K个人来构成样本
整群抽样 / Cluster Sampling
有时总体数目较大, 无法进行编号, 而总体内的每一个群体具有多样性, 这时可以将群体进行编号, 并随机抽取群体作为常模样本
分层抽样 / Stratified Sampling
先将目标总体按某种变量 如年龄 分成若干层次, 再从各层次中随机抽取若干受测者, 最后把各层的受测者组合成常模样本, 是确定常模最常用的方法
常模的类型
发展性常模 / Developmental Norms
许多心理特质 如智力、技能等 会随着时间有规律地发展, 所以可将个人的成绩与各种发展水平的人的平均表现相比较。根据这种平均表现所制成的量表就是发展性常模 或年龄量表
发展顺序量表常模 / Ordinal Scale Norms
发展顺序量表能够表明多大的儿童具备什么能力或行为就显示其发育正常, 最早的一个范例是格塞尔发展过程量表 Gesell Developmental Schedule, 按月份显示儿童在运动水平、适应性、语言、社会性四个方面的大致发展水平
皮亚杰认知发展阶段也属于此常模
心理年龄常模 / Mental Age Norms
比纳-西蒙量表中首先使用心理年龄 Mental Age 的概念。研究者为每个年龄水平都编制一些适当的题目, 从而建构各年龄水平的分测验, 根据儿童能够通过的最高水平组来确定代表其智力水平的年龄, 即心理年龄, 也称智力年龄
年级当量常模 / Grade Equivalents Norms
- 年级当量是指受测者在某个测验上的得分所对应的标准化样本的年级
分数5.8表示5年级零8个月的水平 - 在教育成就测验中常用, 一般用在小学阶段
- 只适用于一般课程, 且在各年级间系统改变
- 不适用于未进入正规学校学习的人
- 对结果的解释需要慎重
测验分数高不代表可以直接跳级了, 即不代表已经掌握了高年级知识
百分位常模 / Percentiles
百分位数 原始分数 与百分等级的双向对照表
| 原始分数 | 32 | 31 | 30 | 29 | 28 | 27 |
| 百分等级 | 99 | 86 | 57 | 35 | 22 | 1 |
百分等级 / Percentile Ranks
某测验分数的百分等级是指在常模样本中低于这个分数的人数百分比 越高成绩越好
- 应用最广的表示测验分数的方法之一
- 便于计算, 易于理解
- PR = 100 - (100R - 50) / N
R为原始分数排名, N为总人数, 50用于修正 - 不受原始分分布影响, 适用任何类型的测验
- 只考虑序, 不考虑值, 结果比较粗糙
百分位数 / Percentiles
也称百分点, 表示处于某一百分等级的人对应的测验分数 原始分数 是多少
标准分常模
标准分常模是将原始分数与平均数的距离以标准差为单位表示出来的量表, 属等距量表
直接线性转换得出标准分
- 直接计算z分数
平均数为0, 标准差为1 - 转换后的Z分数, Z = A + Bz
用以避免小数和负数 - T分数, T = 50 + 10z
和T检验不是同一个东西 - CEEB分数, CEEB = 500 + 100z
美国大学入学考试的标准分 - 比奈-西蒙智力测验分数, IQ = 100 + 16z
- 韦氏智力测验分数, IQ = 100 + 15z
特点
- 标准分数可以作分布内与跨分布的比较
- 标准分数仅是将原始分数进行线性转换, 并未改变各分数的相对关系与距离, 因此z分数转换并不会改变分布的形状
- 在心理测验中, 有时需要将各分量表得分相加, 以求得总分
如韦氏智力测验 - 当原始分数为正态分布时, 标准分数不仅具有可比性, 还具有可加性
非线性转换得出标准分
- 当原始分数不是正态分布时, 可将其正态化, 这一转换过程是非线性的
- 转换后生成的正态化标准分消除了分布形态的影响, 具有了可比性和可加性
正态化过程
- 将原始分数转化为百分等级
- 将百分等级转化为正态分布上相应的分数z’
即对照标准正态分布的百分位常模 - z’可以再转化为上述其他标准分
常模的应用实例: 智商及其意义
比纳-西蒙智力测验: 心理年龄
在最早的比纳-西蒙智力测验中没有智商的概念, 只用心理年龄 Mental Age, MA 来表示受测者智力的高低
在使用中发现, 单纯用心理年龄来表示智力高低的方法缺乏不同年龄儿童间的可比性, 因此改为比率智商, 而现在最常用的是离差智商
斯坦福-比奈智力测验: 比率智商
斯坦福大学推孟教授于1916年对比奈-西蒙测验进行修订, 得到斯坦福-比奈量表。它在心理年龄的基础上, 以智商 (心理年龄/实际年龄)*100 表示测验结果, 即比率智商
比率智商提出后, 普遍被心理学界和医学界接受, 但也出现了问题: 由于个体智力增长是一个由快到慢再到停止的过程, 即心理年龄与实足年龄并不同步增长, 所以比率智商并不适合于年龄较大的受测者 可能出现智商的倒退
韦氏智力测验: 离差智商
离差智商是一种以年龄组为样本计算而得的标准分数, 表示的是个体智力在年龄组中所处的相对位置
为使其与传统的比率智商基本一致, 韦克斯勒将离差智商的平均数定为100, 标准差定为15, 即: IQ=100+15z
常模分数的表示方法
转换表法
也叫常模表, 是最简单且最基本的表示常模的方法。一个转换表显示出一个特定的标准化样组的原始分与其相对应的等值分数。利用此法可以将原始分转换为与其对应的导出分数, 对测验的分数作出有意义的解释
剖面图法
将测验分数的转换关系用图形表示出来。从剖面图上可以直观地看出受测者在各个分测验上的表现及其相对的位置 将分测验标准分连成折线图
标准参照测验
Criterion-referenced Test
根据某一明确界定的内容范围而缜密编制的测验, 并且, 受测者在测验中所得结果, 也是根据某一明确界定的行为标准直接进行解释的
- 不关心测验成绩的相对水平
- 常用于测量教育成就或掌握水平
- 标准指的是编制测验和解释测验分数时所依据的知识和技能范围
分类
内容参照测验 / Domain-referenced Test
测验所使用的标准是由内容材料定义的, 即考察受测者掌握某领域知识和技能的比例, 一般以通过 / 不通过来呈现结果 如高中会考、驾驶理论科目
结果参照测验 / Result-referenced Test
当已知测验分数和某个外部效标有关时, 可用受测者在效标上的表现来解释测验分数。可以通过期望结果概率或预期的效标分数呈现结果参照测验的分数
| ACT分数 | GPA>3 | GPA>2 | GPA<2 |
|---|---|---|---|
| 32 | .93 | .99 | .01 |
| 31 | .67 | .97 | .03 |
| 30 | .58 | .97 | .03 |
| 29 | .34 | .89 | .11 |
| ACT分数 | 32 | 31 | 30 | 29 | 28 | 27 |
|---|---|---|---|---|---|---|
| 预期GPA | 3.17 | 3.06 | 2.95 | 2.84 | 2.73 | 2.62 |
编制流程

- 应当清晰地界定目标
- 给出严格的操作定义
- 强调题目对内容的代表性
用途
- 各类教育水平测验、职业水平 / 资格测验往往会采取标准参照测验的编制、施测、记分和解释模式
用于确定最低要求 - 应用于教育教学实践, 如教师通过自编测验来考察学生对知识的掌握情况, 或自我调节式学习的成果检验等
强调测验的诊断功能和发展功能
划界分数设置
判断法
整体判断法 / Holistic Impressions
每位专家 学科专家、测量学家、教学能手等, 要求较高 从整体上对测验和内容范围进行判断, 提出符合标准的最低能力水平的受测者正确回答的项目的比例。然后将所有专家的分数平均, 作为划界分数
Nedelsky方法
只适用于选择题
- 由每位专家对每个题目判断临界水平受测者都能够排除的选项的个数
- 记录剩余的选项的倒数
- 将该测验中所有项目的倒数的和记为A, 作为该专家确定的临界水平受测者的可能分数
- 对所有专家的A值进行平均, 即为最低通过分数
Angoff方法
由专家对临界水平受测者答对某项目的概率进行估计, 并求每个项目的平均答对概率Pi, 再结合各项目满分来求划界分数λ
| 题号 | 题目满分Fi | 临界水平Pi | Fi*Pi |
|---|---|---|---|
| 1 | 8 | 0.8 | 6.4 |
| 2 | 10 | 0.65 | 6.5 |
| 3 | 22 | 0.7 | 15.4 |
| 4 | 25 | 0.6 | 15 |
| 5 | 35 | 0.55 | 19.25 |
总分ΣFi = 100, 划界分数λ = ΣFi*Pi = 62.55
Ebel方法
以题目特性决定最低通过分数。先将项目按照难度和重要性进行分类, 再由专家对每一单元格的重要性给予权数 通过率, 将各题目数 默认一题一分 与权数相乘、加总、求题目权数的均值, 即为划界分数
| 难度 → 权数 / 题目数 ↘ 重要性 ↓ |
困难 | 一般 | 容易 |
|---|---|---|---|
| 必要的 | 0.12 / 6 | 0.48 / 26 | 0.94 / 20 |
| 重要的 | 0.22 / 10 | 0.35 / 22 | 0.55 / 36 |
| 可用的 | 0.11 / 14 | 0.19 / 10 | 0.43 / 20 |
| 有问题的 | 0.03 / 10 | 0 / 20 | 0.2 / 6 |
Angoff修正法
这种方法采用了与Ebel方法不同的两个维度:
- 受测者完成测题所需要的能力高低
如记忆和理解等- 每题的测量目标
如词汇、语法和阅读理解等计算划界分数的方法相同
实证法
实证法可减少经验判断法中主观因素的影响, 但会受到抽样误差的影响。具体方法有多种, 例如:
- 将测验实施于一组比最终目标总体水平略低的群体, 以该群体的平均分或中位数作为划界分数
- 以低于团体平均水平一个标准差的分数为截点
综合法
临界组法 / Borderline Groups Method
由专家判断和选择一组正处于临界水平的受测者, 将测验施测于该组受测者, 计算他们在测验上的平均成绩, 以确定测验的内容范围所要求的临界水平 但是如何找到并确定临界水平的受测者较困难
对照组法 / Contrasting Groups Method
- 选择熟悉受测者的专家
- 让专家判断一组受测者为掌握组, 另一组受测者为非掌握组, 不太容易判断的受测者一概剔除
- 对两组受测者进行施测
- 在同一坐标系上画出两组的分数分布图
- 将两个组的交叉点设置为划界分数
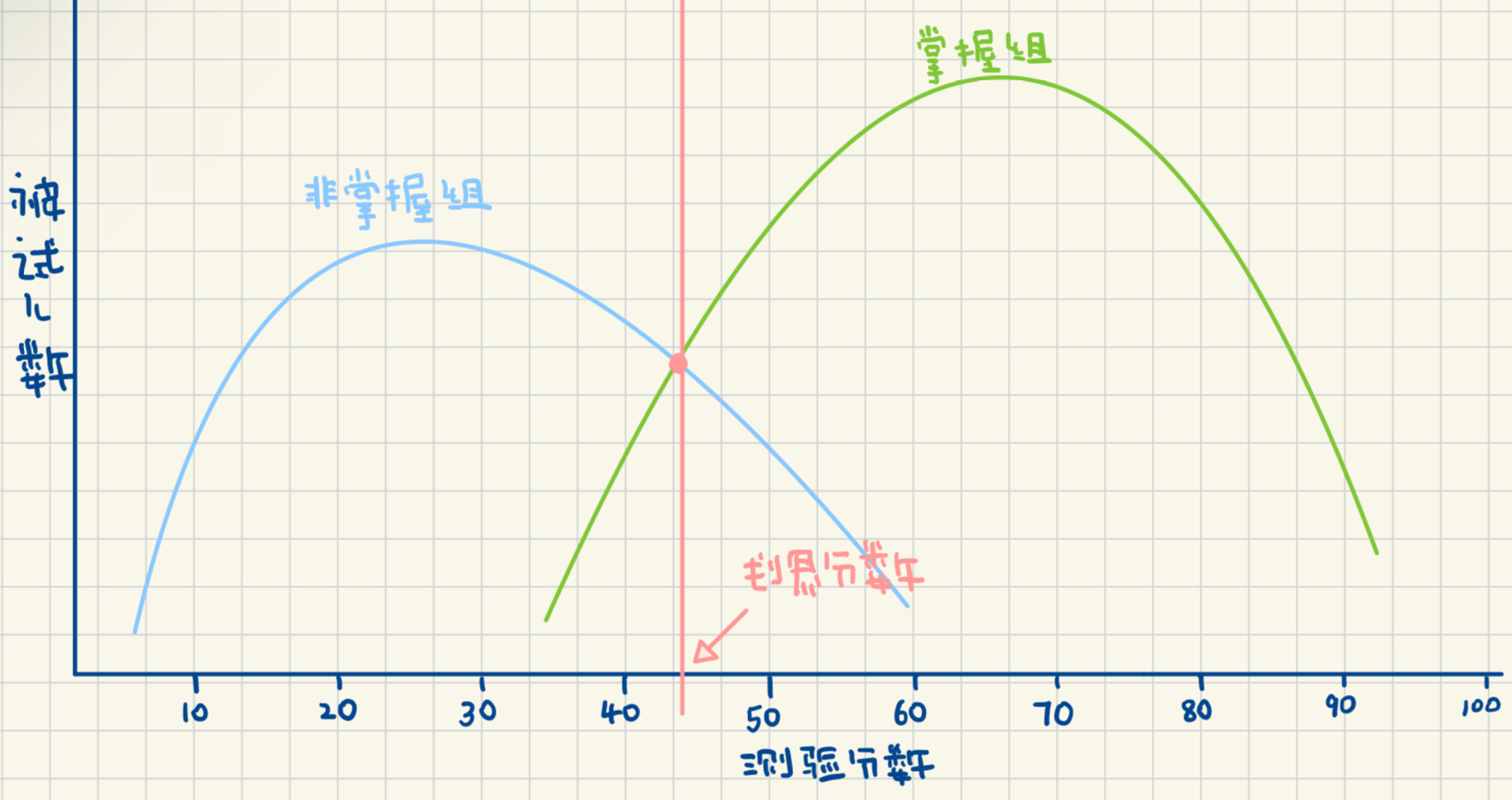
通常会选择多个对照组, 取交叉点的平均值为测验分数的划界分数; 这种方法比临界组法更实用
Jeager方法
- 由中学教师、学校校长与学校辅导员、当地居民共三类人员组成专家组
- 每位专家先完成该测验
采用标准指导语, 不限答题时间, 之后获知正确答案。 - 每位专家对问题”当地每个要毕业的中学生都应能正确回答这道题吗?”作是或否回答
- 确定每组专家所建议的通过分数分布
- 告诉每位专家一组比毕业生低一个年级的学生在某测验项目上的通过率和组内其他专家对某测验项目的评定
- 允许专家根据上一条的信息修改他们最初的评定, 一共需评定三轮
- 根据各专家最终的项目评定, 计算划界分数
- 计算所有专家
包含各组划界分数的中位数
注意事项
分数解释
- 主试应充分了解测验的性质与功能
- 对导致测验结果的原因的解释应慎重, 不能把分数绝对化
- 将个人在测验前的经历考虑在内
- 考虑测验的情境是否会影响结果
- 应将测验分数视为分数区间
置信区间, 而不是一个点 - 充分估计测验的效度和常模的局限性
分数报告
- 不应把测验分数直接告诉有关人员, 应告诉的是测验分数的解释和建议
- 避免使用专业术语, 保证对方正确理解
- 要保证当事人知道这个测验测量或预测什么
- 要使当事人知道他是和什么团体在进行比较
- 要使当事人知道如何运用他的分数
- 要考虑测验分数将给当事人带来什么心理影响
- 要让当事人积极参与测验分数的解释
⭐心理测验的使用
主试的资格
专业知识
- 基础知识: 普通心理学、发展心理学、社会心理学、心理统计学等
- 专业知识: 人格心理学、变态心理学、智力理论等
- 还要清楚测验的性质和特点、作用与局限性
专业技能
- 熟悉测验内容、程序、计分方法
- 个别测验会对主试有较高要求
- 投射测验需经验丰富的咨询专家或医生
职业道德
- 测验的保密: 泄露将导致测验失效, 若有宣传的必要, 只能采用例题
- 控制使用: 必须经过专业训练, 有资格, 避免滥用、误用
- 知情同意与隐私保护: 除非可能对个人或社会造成危害
详见咨询心理学 - 避免歧视: 使用最轻烙印标签
Least Stigmatizing Label, 如用”智力损伤”代替”白痴”或”弱智”, 用”青少年适应性人格”代替”变态人格”等
美国指导系统
AGS对测验使用者的要求
- 测验前后保持测验材料的安全
- 避免根据单一测验分数对个体贴标签
- 严格按照著作权法并在任何情况下都不得进行影印或复制其他答题纸、测验书籍或手册
- 正确按照手册进行测验的施测和计分
- 按照认可的测验解释规则, 并仅向授权人发布测验结果
测验的选择
测验应适合测量的目的
- 要了解各种测验的功能、优缺点
- 不能仅根据测验名称选择
测验应符合心理测量学要求
- 经过标准化
- 信效度良好
- 常模
对象、时间合理
测验前的准备
测验前的准备工作
- 预告测验
- 准备测验材料
- 熟悉测验指导语
- 熟悉测验的具体程序
建立协调关系
协调关系 Rapport: 一个在临床心理咨询、心理治疗中经常用到的专业术语: 主试与受测者应该是友好合作关系, 以促使更好地完成测验
- 智力测验: 引导被试最佳表现
- 人格测验: 引导被试最真实表现
- 学前儿童: 帮助被试克服胆怯、友好愉快
- 一般学生: 以适当竞争激发被试动机
- 普通成人: 晓之以理, 减少不认真作答倾向
测试实施的程序和要素
对被试的指导语
- 如何选择反应方式
- 如何记录反应
- 是否有时间限制
- 若不能正确反应时应如何操作
- 提供例题
- 有时可告知受测者测验目的
有多个主试时, 还需要对主试的指导语
主试的职责
- 按指导语要求施测, 不带暗示, 必要情况下, 尽量按照字典的意思解释
- 测验过程不讲无关的话, 以免引起受测者烦躁或焦虑
- 对受测者的反应不作出暗示性反应
- 对特殊问题、突发事件有心理准备
测验的时限
- 大多数典型行为测验是不受时间限制
- 最高作为测验中时限是重要因素, 尤其在速度测验中, 要注意时限, 不得随意延长或缩短
- 施测测验的时间点也需要考虑
在高考前后施测推理能力测验, 不能反映真实水平 - 特殊情况
生病等, 必要时可延长时限
测验的环境条件
- 光线、通风、温度、噪音的标准化
- 避免干扰
- 记录测试过程中的意外因素
受测者误差及控制方法
应试技巧和练习效应
- 被试对测验的经验或应试技巧会影响测验成绩
如善于"察言观色"、合理分配时间、阅题无数 - 对测验的程序和技能熟悉程度不同, 所得分数便不能直接比较
- 避免练习效应: 尽量使受测者有相同的熟悉程度
应试动机
- 对于成就测验、智力测验、能力倾向测验, 较强烈的动机会导致更高的成绩
- 对于上述测验, 社会经济地位不高的受测者往往测验动机不强
- 态度、兴趣、人格测验易受社会称许性
装好和逃避惩罚装差影响
测验焦虑
- 适度的焦虑会使人的兴奋性提高, 有积极影响
- 过度的焦虑会使工作能力降低, 成绩大多偏低
思维狭隘、考试焦虑 - 总体影响呈倒U型曲线
- 降低焦虑的方法: 辅导、熟悉测验程序
反应定式
即反应风格 Response Sets of Styles, 指独立于测验内容的反应倾向
- 求快 / 求精确: 通过注明每个项目的答题时间来控制
没到时间不能答下一题 - 偏好正面叙述
人格测验中: 通过平衡正面和反面描述来控制 - 偏好特殊位置: 通过平衡标准答案的位置来控制
- 偏好较长选项: 通过使选项长度相对一致来控制
- 趋同回答
李克特量表中, 都选高的/低的: 通过设置反向题来控制 - 极端应答偏差: 李克特量表中, 喜欢选中立还是极端值
东西方文化差异 - 对猜测的偏好不同: 通过增大猜错的代价来控制
不努力作答 / Insufficient Effort Responding, IER
受测者由于作答动机较低, 从而出现不遵循问卷指导语, 没有精确地理解题目内容、没有提供准确问答的行为, 也称不用心作答 Careless Responding
事前控制方法
降低任务难度
- 采用清晰简洁易懂的指导语和题目描述, 从而减轻认知加工负担
- 缩短问卷, 降低疲劳感
提升作答动机
- 提供反馈报告
- 使用外部奖励或惩罚 / 警告
- 要求受测者承诺认真作答
- 作答过程增强社会互动
弹窗互动、虚拟形象等 - 提升积极情绪: 测验穿插娱乐放松激励
检测被试是否满足目标群体要求
用一两道只有目标群体能回答的题目
在网络游戏”明日方舟”中, 以下哪两位角色从小一起长大?
A. 梅菲斯特和浮士德
B. 凯尔希和阿米娅
C. 博士和水月
D. 德克萨斯和拉普兰德
事后识别方法
线上问卷
无监控、低动机的线上问卷更容易出现不努力作答 问卷可用率甚至只有60%上下
- 删除答题时间低于0.5s的被试
- 删除漏答率高于5%的被试
- 删除无意义连续作答的被试
连着选A或一直ABABAB - 删除前后部分作答时间相差过大的被试
嵌入质量控制 Quality Control 题目
- 假题 / 陷阱题
Bogus Items: 如”我的生日是2月30日” - 指定题
Instructed Items: 应当写明此题的目的, 如”为了确保您在认真作答, 本次请不要选择任何答案” - 自我报告认真程度
Self-reported Diligence - 在指导语中指定了特殊作答方式的题目: 检测是否认真阅读指导语
根据作答时长 Response Time 检测
- 依据过往研究的经验, 每题平均作答时间应至少为2秒左右
- 观察被试们反应时的分布图象, 若为双峰分布, 删除时间较短的峰的被试
- 可以通过预实验大致确定本测验合理的作答时长
个体一致性分析
如果受测者在各个题目上的选项分布过于随机或过于一致, 则表明其没有认真作答, 以下是一些判断指标:
- 长串
Long String, LS: 连续选择某一选项的最长个数, 超过了问卷长度的一半就可以认为问卷无效; 注意: 本方法只有在有反向计分题目的测验中有效 - 作答标准差
Intra-individual Response Variability, IRT: 可以弥补长串的不足, ISDi = sqrt[ Σg=1k ( Xig - averXi )2 / (k-1) ] - 奇偶一致性
Even-Odd Consistency: 将整个问卷分为若干个单维度的子量表, 分别计算每个子量表的奇数项和偶数项的均值, 求所有奇数项均值与所有偶数项均值之间的相关斯皮尔曼-布朗公式, 低于0.3则被试大概率不认真 - 正反向题目对相关
Within-person Correlation Across Item Pairs: 观察被试在语义一致 / 相似 / 相反的题目对和心理测量一致常模中相关大于0.6以上的题目对上的作答是否一致 - 奇异值分析
Outlier Analysis: 假设大多数受测者都在认真思考作答实际上可能正相反, 此时奇异值恰好反映了真实情况, 则当个人作答模式偏离群体过大时, 可判定为作答不认真; 注意: 不认真作答者不一定是奇异值
奇异值分析指标


汇总建议
- 想办法激励受测者认真填答
环境、测试报告、贡献、被试费- 备维度包含正反向题, 各维度题量不能太少, 整个问卷包含积极和消极的变量
如大五人格中的神经质和开放性- 不要采用太过严厉的指导语, 以免惹怒受测者
- 每50-100题目, 插入1-3个诈选 / 指定题
- 末尾加入一个自我报告认真程度题
- 尽可能记录各题作答时间
- 采用至少一种个体一致性分析指标和一种奇异值分析指标
- 筛选数据后, 比较筛选前后的分析结果, 并在论文进行报告
测验的评分和报告
原始分数的获得
- 及时而清楚地记录反应情况
- 要有一张标准答案或正确反应的表格, 即计分键
- 将被试的反应和计分键比较, 对反应进行分类
解释和报告的注意事项
终于结束了, 令人头秃
- 标题: 心理测量学
- 作者: 小叶子
- 创建于 : 2023-11-02 20:34:44
- 更新于 : 2026-02-25 14:11:09
- 链接: https://blog.leafyee.xyz/2023/11/02/MeasuringPsychology/
- 版权声明: 版权所有 © 小叶子,禁止转载。


